




 本文介绍了Spring Data JPA中save和saveAndFlush的区别。save方法适用于常规的增删操作,当数据库中不存在记录时插入,存在时更新。而在同一事务中,若需要立即获取保存后的ID,如保存Order后再保存OrderItem,此时应使用saveAndFlush。save在更新操作时可能丢失原有字段值,需注意先查询再合并更新以保持所有字段完整。
本文介绍了Spring Data JPA中save和saveAndFlush的区别。save方法适用于常规的增删操作,当数据库中不存在记录时插入,存在时更新。而在同一事务中,若需要立即获取保存后的ID,如保存Order后再保存OrderItem,此时应使用saveAndFlush。save在更新操作时可能丢失原有字段值,需注意先查询再合并更新以保持所有字段完整。
Spring Data Jpa中save和saveAndFlush的区别,首先直接看图:
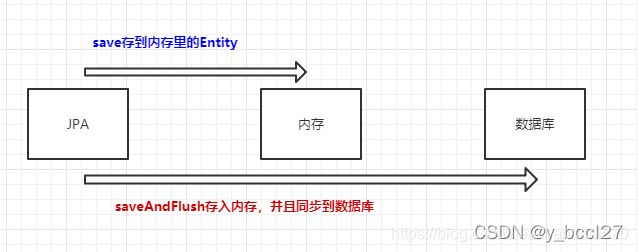
save是CurdRepository接口下的方法
saveAndFlush是JpaRepository接口下的方法
一般情况下,我们仅仅使用save方法就可以满足业务需求。但是如果在同一个事务中,例如在方法上添加了@Transactional注解,我们想先保存Order(订单)数据,然后直接在这个事务中保存OrderItem(订单明细)数据,但是OrderItem需要前面所新建的Order里面的ID,这个时候保存Order就可以用saveAndFlush,订单实体中就会有保存在数据库里面的id了。
save 的具体的工作机制:
1.使用save方法的时候,如果数据库中没有这条数据,是根据主键进行插入一条数据的操作
2.使用save方法的时候,如果数据库中已经存在这条数据的时候,是进行更新操作
问题:为什么在使用save方法,如果是更新操作,有时会丢失之前原来数据行已经有的字段值?
答:其实save方法,就是直接保存一个对象,这个操作是覆盖(我说的是在这个ID已经存在的情况下,否则就是一个插入操作,没有任何疑问)。举个例子,假如这个数据库已经有此ID 的数据,并且这条数据有10个字段。其中5个字段一已经有值了。现在要save操作,但是现在恰恰要保存没有值的5个字段,我们直接用save,会发现本来有值的几个字段可能没有了,这不是我们想要的结果。如果想要达到我们想要的结果,应该先查询一次,如果有数据就将查到的数据合并到要save 的实体类中去,然后再针对这个实体进行更新操作。这样才能做到,十个字段全有值,不丢失已有的字段的值。

















 1560
1560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









