







 本文对比了Spark Streaming和Flink在实时ETL过程中处理小文件的问题。Spark Streaming由于小文件过多导致资源浪费和查询性能下降,需要通过延长batch时间、调整写入方式等解决。而Flink提供了设置写入文件大小和自动翻滚的API,能更高效地处理小文件,减少复杂性。Flink的自定义bucketer功能允许根据数据内容决定HDFS路径,避免了预处理数据的需要。
本文对比了Spark Streaming和Flink在实时ETL过程中处理小文件的问题。Spark Streaming由于小文件过多导致资源浪费和查询性能下降,需要通过延长batch时间、调整写入方式等解决。而Flink提供了设置写入文件大小和自动翻滚的API,能更高效地处理小文件,减少复杂性。Flink的自定义bucketer功能允许根据数据内容决定HDFS路径,避免了预处理数据的需要。

题图:金黄阳光下的建筑
一、Spark Streaming 实时 ETL
Spark Streaming 实时消费kafka入hive,一般控制批次数据在1分钟以内,甚至30s,而hive分区一般都会按照小时分区,就会导致小文件数据非常多。小文件多了,有如下两个问题:
- 小文件过多,占用 namenode 资源,hive 查询也会读取过多数据块 block 的数据,影响 hive 查询性能;
- 因如上的问题,一般需要在某个分区不再更新的时候,比如上一个小时的数据不再更新了,就可以执行hive sql达到指定文件大小来合并分区。而合并小文件同样需要消耗 namenode 资源;
-- hive 合并小文件示例
ALTER TABLE test_table PARTITION(p_dt='${date}',p_hours='${hour}') CONCATENATE;
那么没有更好的方案呢?
实际使用过程,我们看到,1分钟一个批次的数据,处理时间只需20s左右(业务场景不同时长有所不同),这空闲的40s,显然浪费了。
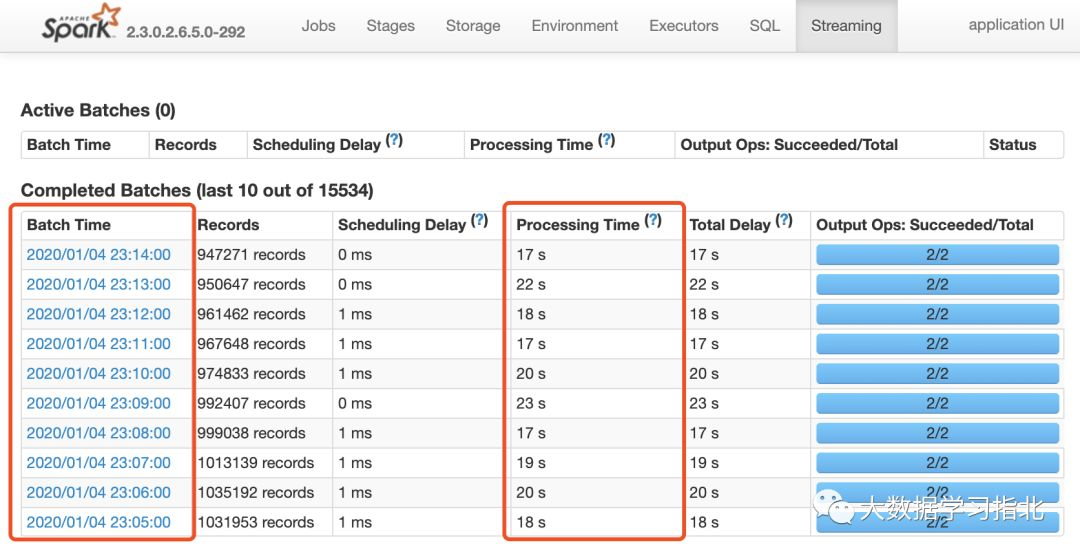
图1: spark streaming 实时ETL任务的处理时间
问题的根源还是小文件的存在,解决方式自然在这里:
- batch time 延长
- 写入到一个文件,需改写写入 hdfs 方法(不展开)
- 写入文件可能需要使用 ORC 格式
- 保证文件大小接近 HDFS 文件系统的 Block Size
spark 写入 hdfs 均为小文件,可通过 repartition(1) , coalesce(1) 来实现写入到一个文件;
如果要保证文件接近HDFS,那必定需要知道 RDD 的大小
var rddSize = rdd.map(_.toString())
.map(_.getBytes("UTF-8" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









