







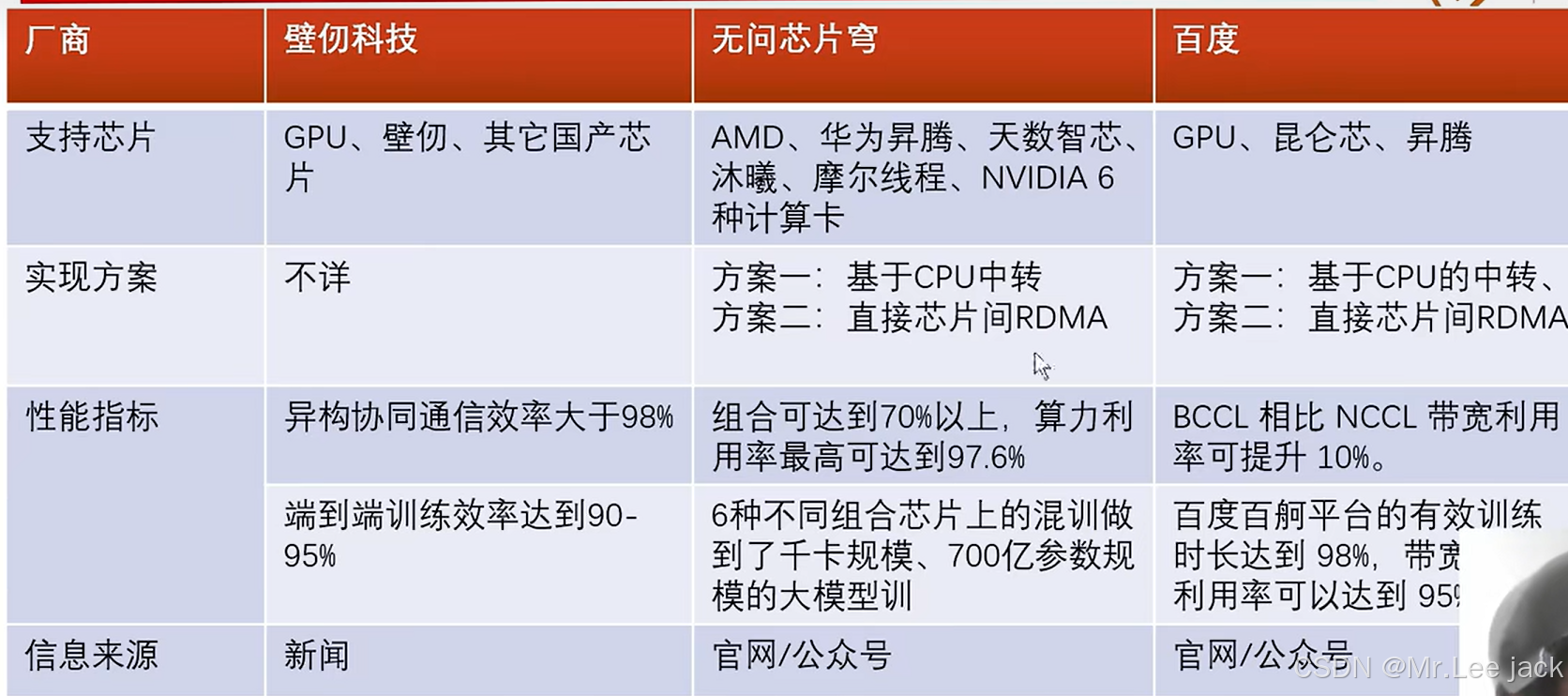
结论
通过gloo通信,可以将各家芯片通信联通
通过梯度更新实验,证明方式可行
背景
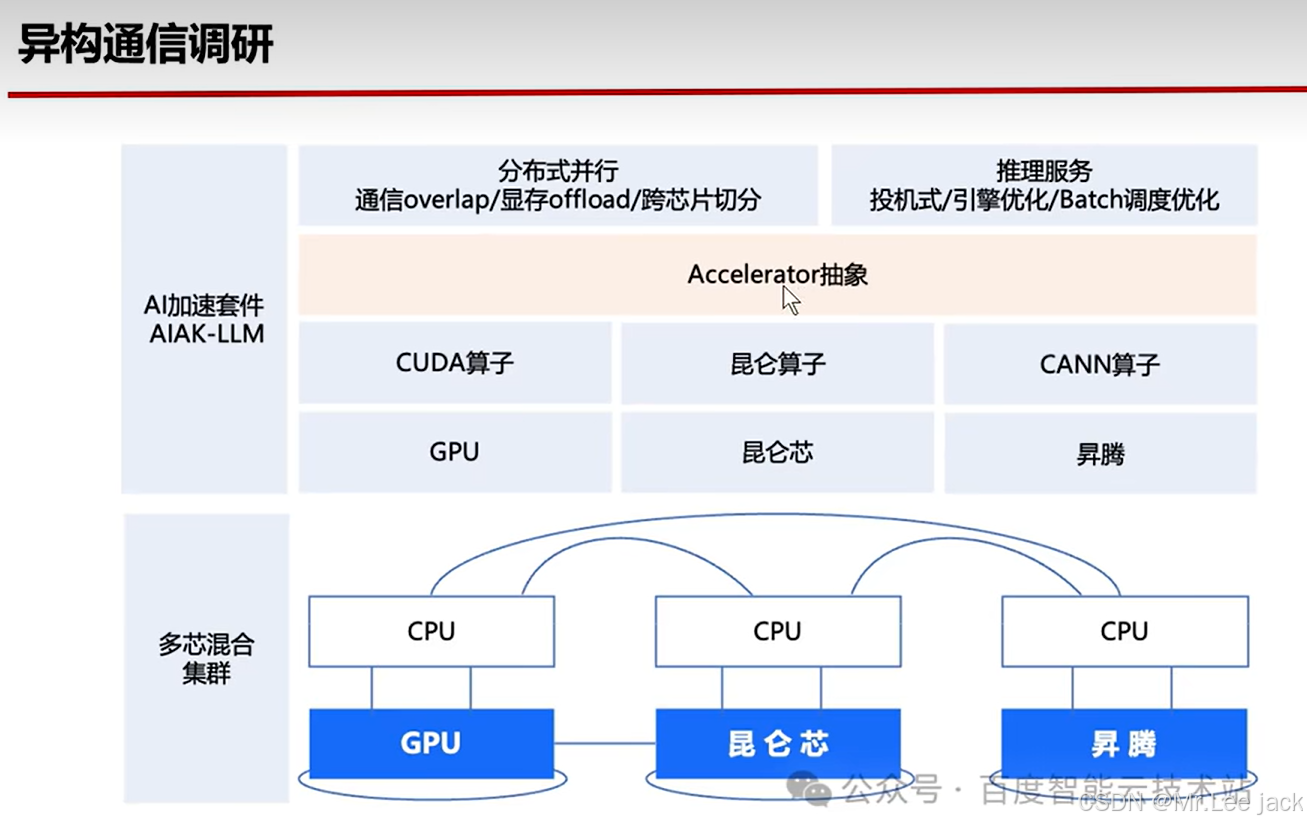
昆仑芯通过领先技术,可实现单机八卡高速互联,带宽达到200GB/s;支持Direct RDMA,可实现跨机间低延时、高速通讯。
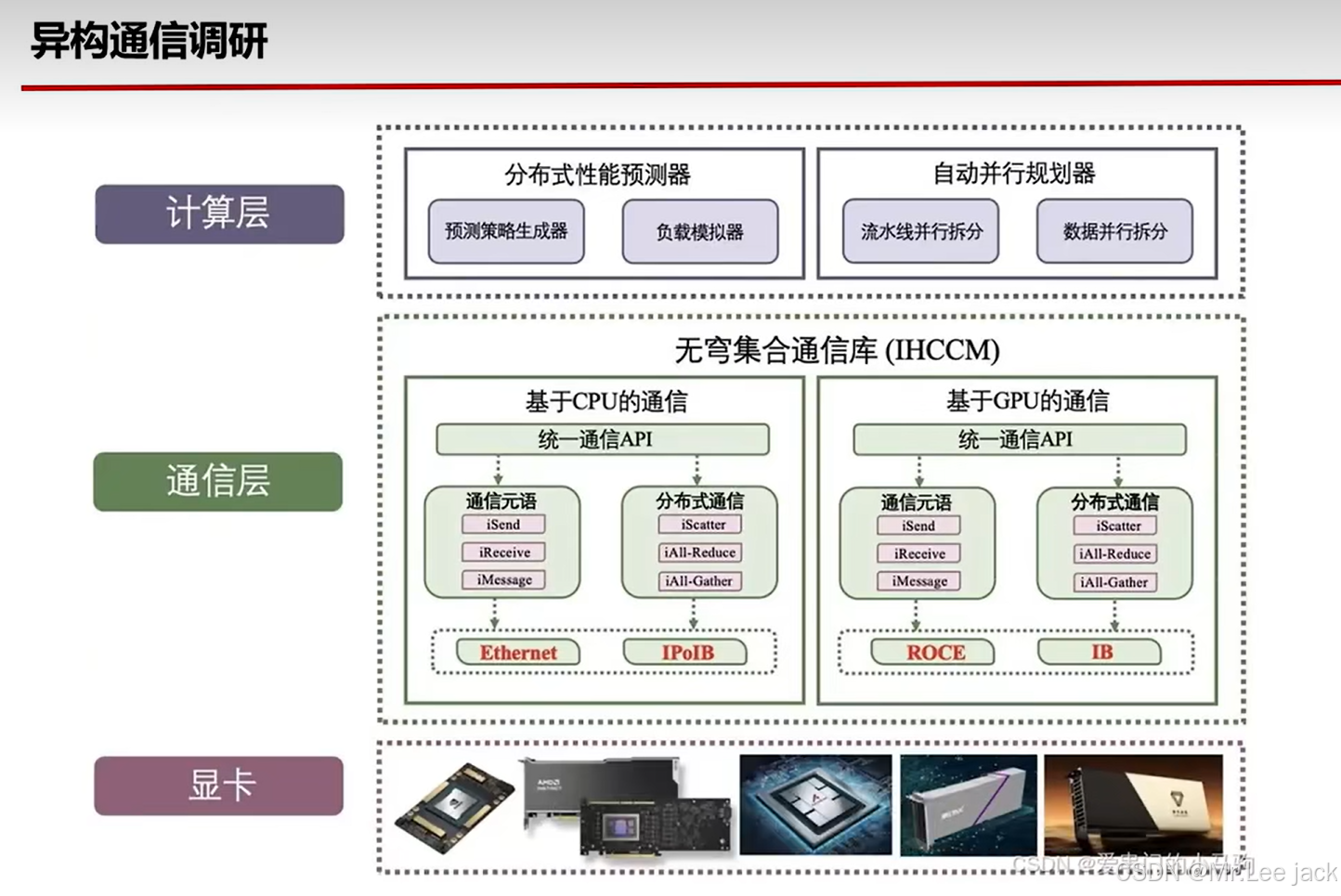
进程通信方式
TCPStore && FileStore
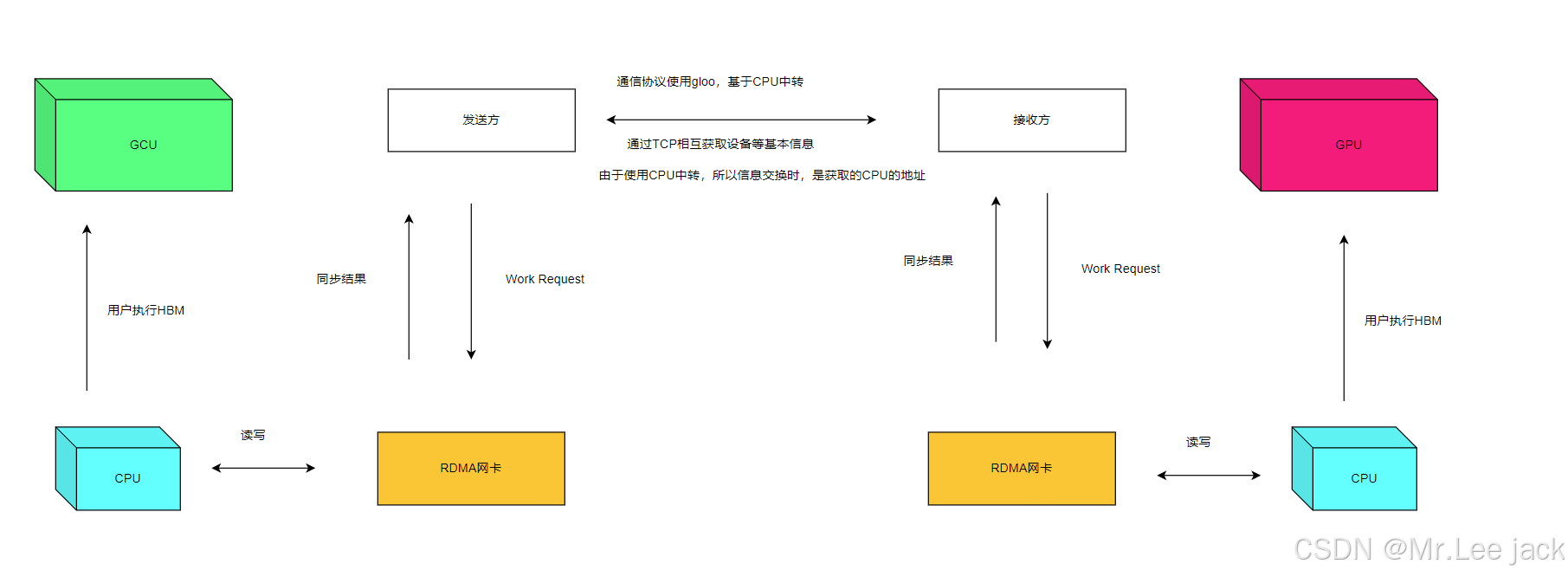
数据交换通信方式
- 以太网:
os.environ['GLOO_SOCKET_IFNAME'] = 'ens6f0' - RDMA网卡:
os.environ['GLOO_SOCKET_IFNAME'] = 'ib0'
以太网
- 以太网socket通信过程
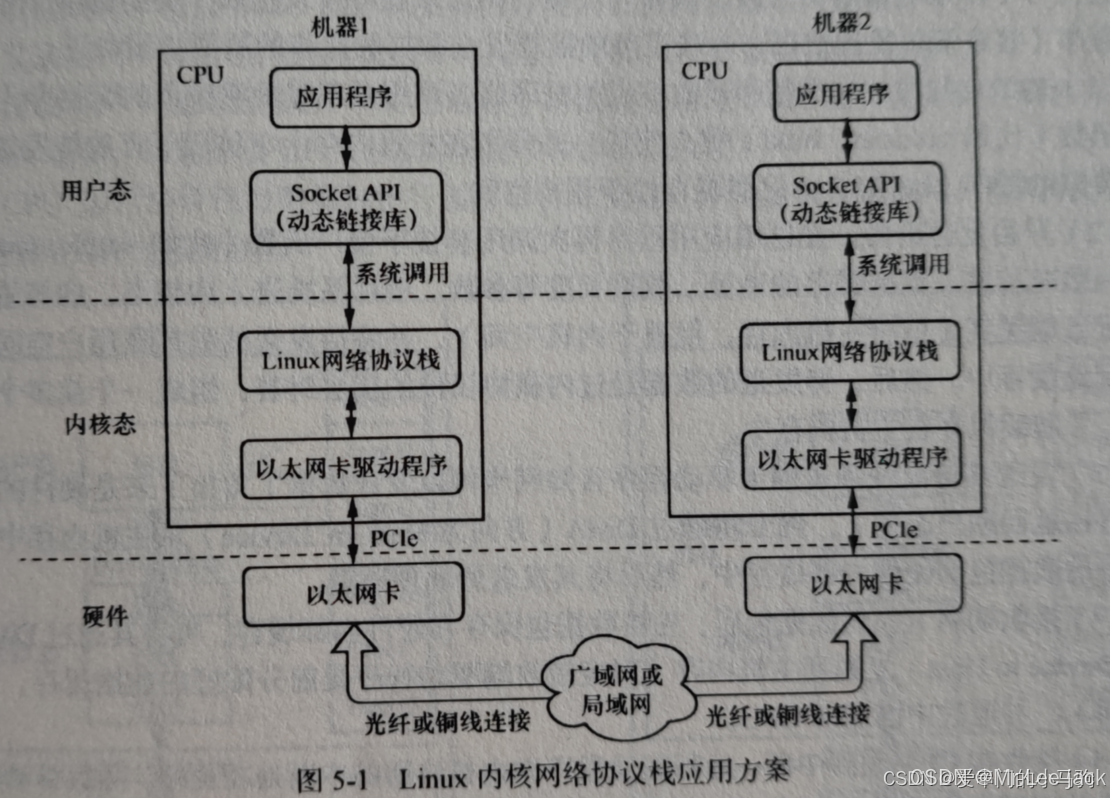
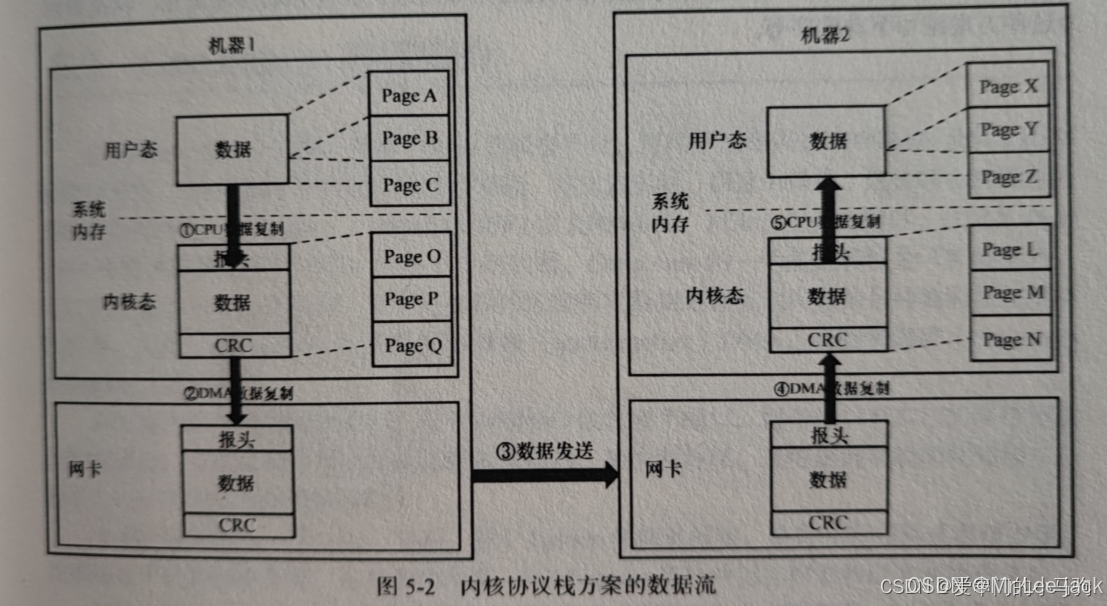
发送端发起一次通信操作,数据由用户空间拷贝到内核空间。拷贝由CPU完成,并且在内核空间总由CPU完成数据封装,添加报头和校验信息。
2、发送端网卡通过DMA由主机内存内核空间复制数据到发送端网卡的内部缓存。
3、发送端网卡通过物理链路发送数据给接收端网卡。
4、接收端网卡,通过DMA将接收端网卡缓存空间的数据拷贝到主机内存的内核空间。
5、CPU对数据进行解析和校验,并将数据由内核空间复制到用户空间
- 以太网socket通信的缺点
1、send/recv等系统调用,导致系统在用户态和内核态间切换,耗时,增加传输延时。
2、发送时数据需要从用户空间拷贝到内核空间(接收时反向拷贝),增加传输延时。
3、CPU全程参与数据包的封装和解析,对CPU造成负担
RDMA
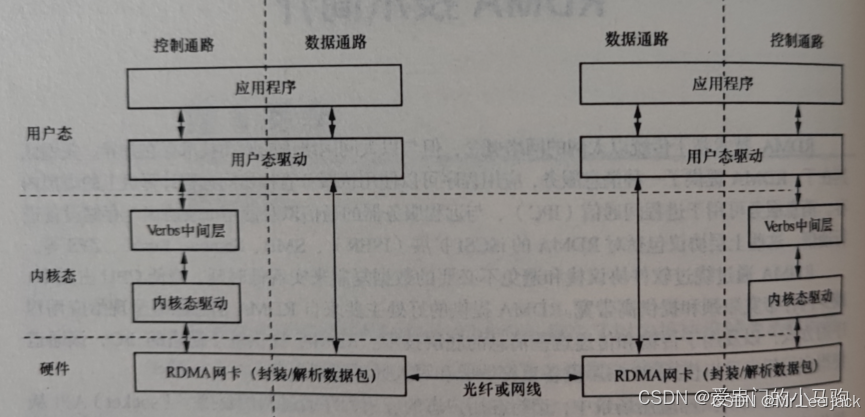
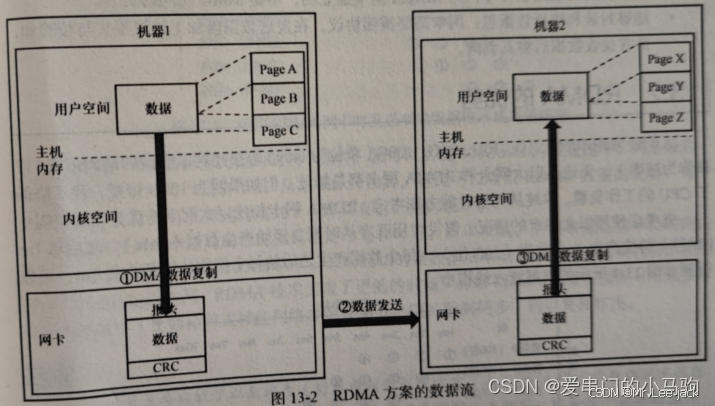
- RDMA数据传输过程
1、发送端网卡,通过DMA,将用户空间的数据拷贝到网卡缓存,对数据进行协议封装,添加各层协议报头和校验信息。
2、发送端网卡通过网线/光纤将封装好的数据发送给接收端网卡。
3、接收端网卡对数据进行解析后,通过DMA将数据拷贝到用户空间。
- RDMA的优点
1、数据传输时没有系统调用,不需要用户态内核态切换,降低通信延迟。
2、省去数据在户空间拷贝到内核空间之间的拷贝,降低通信延迟。(零拷贝)
3、数据包的封装和解析,由网卡完成,降低CPU负载 - RDMA对硬件的新要求
1、网卡能够访问物理地址不连续的用户空间。
2、网卡需要负责数据的封装和解析
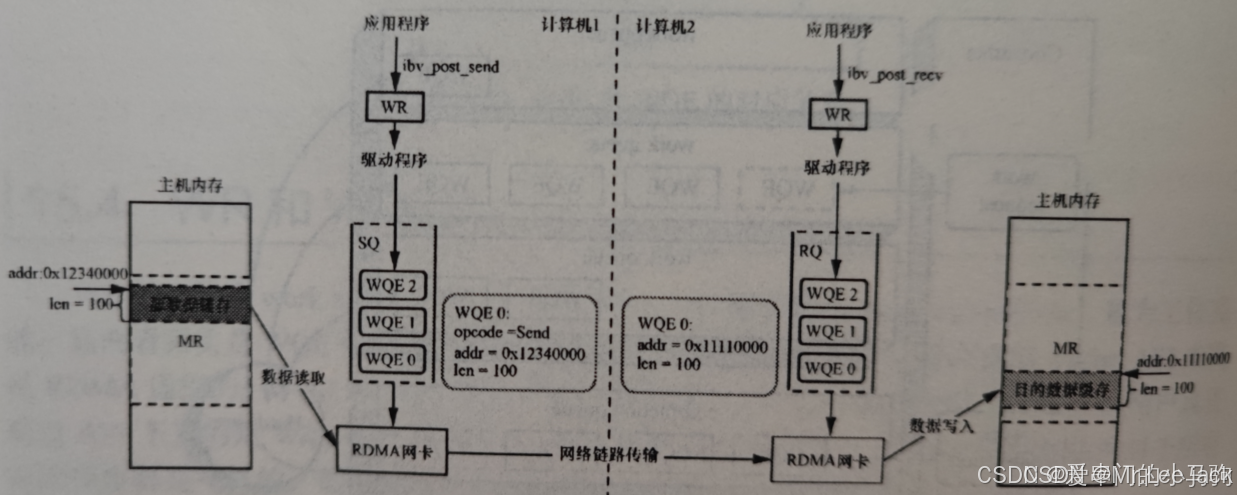
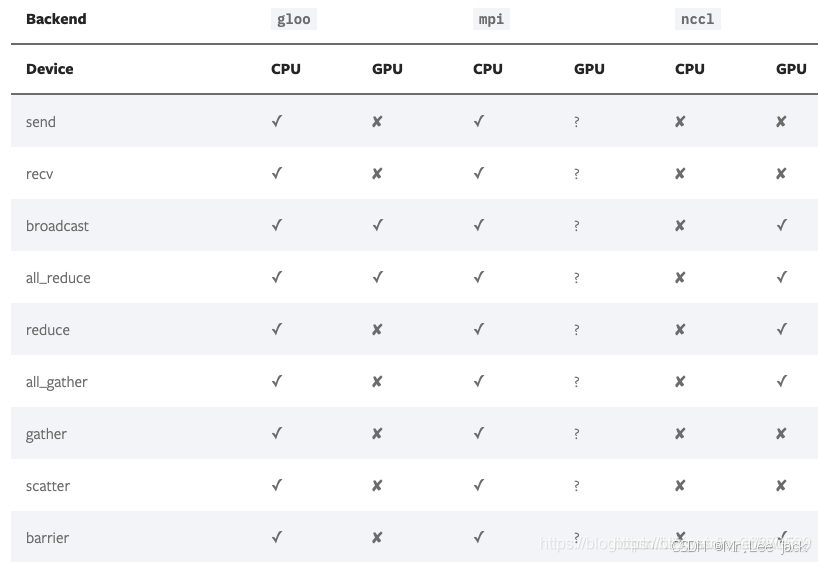
Torch Backends
方案设计
测试通信GCU&&GPU
import torch
import torch.distributed as dist
import os
if torch.cuda.is_available():
pass
else:
try:
import torch_gcu # 导入 torch_gcu
from torch_gcu import transfer_to_gcu # 导入 transfer_to_gcu
except Exception as e:
print(e)
print("torch.cuda.is_available(): ", torch.cuda.is_available())
def init_process(rank, world_size, fn, backend='gloo'):
dist.init_process_group(backend, rank=rank, world_size=world_size)
fn(rank, world_size)
def send_tensor(rank, world_size, device):
tensor = torch.rand(2, 2).to(device)
print(f"Rank {rank} tensor on {device}:\n{tensor}")
if rank == 0:
for i in range(1, world_size):
dist.send(tensor=tensor.cpu(), dst=i)
else:
received_tensor = torch.empty(2, 2)
dist.recv(tensor=received_tensor, src=0)
received_tensor = received_tensor.to(device)
print(f"Rank {rank} received tensor on {device}:\n{received_tensor}")
def run(rank=0, world_size=2, backend="gloo", master_addr="localhost", master_port=4321, device=None):
os.environ['MASTER_ADDR'] = master_addr
os.environ['MASTER_PORT'] = str(master_port)
os.environ['NCCL_SOCKET_IFNAME'] = 'ens6f0'
os.environ['GLOO_SOCKET_IFNAME'] = 'ens6f0'
if device is None:
device = f"cuda:{rank}" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
init_process(rank, world_size, fn=lambda r, s: send_tensor(r, s, device), backend=backend)
# Usage examples:
# python main.py --rank=0 --world_size=2 --master_addr=localhost --master_port=4321 --device=cuda:0
# python main.py --rank=1 --world_size=2 --master_addr=10.9.112.104 --master_port=4321 --device=cuda:1
# python main.py --rank=2 --world_size=3 --master_addr=localhost --master_port=4321 --device=cpu
if __name__ == "__main__":
from fire import Fire
Fire(run)
- 实验结论


模拟训练通信
import torch
import torch.distributed as dist
import os
import argparse
if torch.cuda.is_available():
pass
else:
try:
import torch_gcu # 导入 torch_gcu
from torch_gcu import transfer_to_gcu # 导入 transfer_to_gcu
except Exception as e:
print(e)
print("torch.cuda.is_available(): ", torch.cuda.is_available())
def init_process(rank, world_size, backend='gloo'):
print("init_process rank: ", rank)
print("init_process world_size: ", world_size)
print("init_process backend: ", backend)
# 初始化分布式环境,使用 gloo 后端
dist.init_process_group(backend, rank=rank, world_size=world_size)
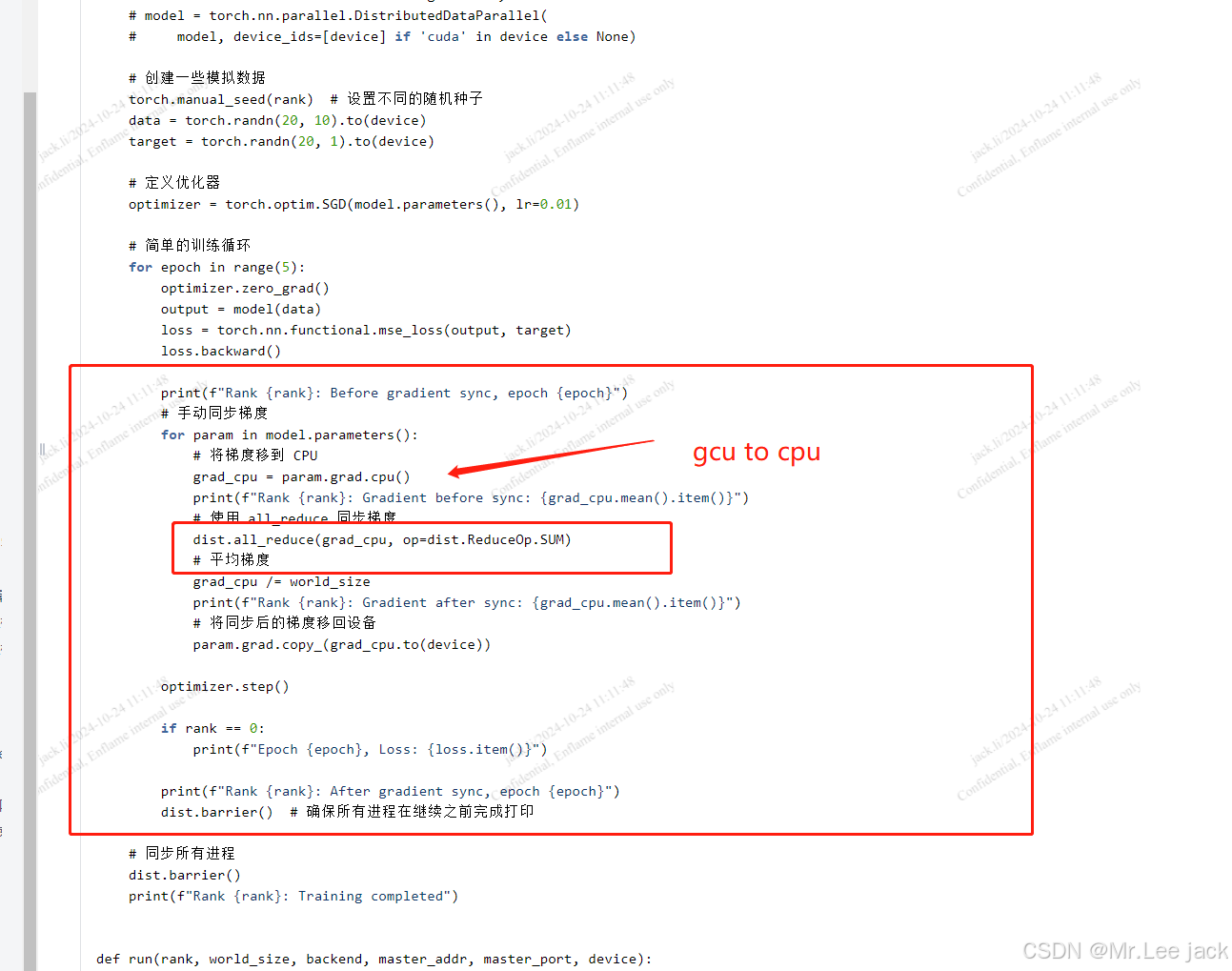
def parallel_training(rank, world_size, device):
# 创建一个简单的模型
model = torch.nn.Linear(10, 1).to(device)
# 将模型转换为分布式数据并行模型,使用 gloo 后端, 自动同步梯度
# model = torch.nn.parallel.DistributedDataParallel(
# model, device_ids=[device] if 'cuda' in device else None)
# 创建一些模拟数据
torch.manual_seed(rank) # 设置不同的随机种子
data = torch.randn(20, 10).to(device)
target = torch.randn(20, 1).to(device)
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 简单的训练循环
for epoch in range(5):
optimizer.zero_grad()
output = model(data)
loss = torch.nn.functional.mse_loss(output, target)
loss.backward()
print(f"Rank {rank}: Before gradient sync, epoch {epoch}")
# 手动同步梯度
for param in model.parameters():
# 将梯度移到 CPU
grad_cpu = param.grad.cpu()
print(f"Rank {rank}: Gradient before sync: {grad_cpu.mean().item()}")
# 使用 all_reduce 同步梯度
dist.all_reduce(grad_cpu, op=dist.ReduceOp.SUM)
# 平均梯度
grad_cpu /= world_size
print(f"Rank {rank}: Gradient after sync: {grad_cpu.mean().item()}")
# 将同步后的梯度移回设备
param.grad.copy_(grad_cpu.to(device))
optimizer.step()
if rank == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
print(f"Rank {rank}: After gradient sync, epoch {epoch}")
dist.barrier() # 确保所有进程在继续之前完成打印
# 同步所有进程
dist.barrier()
print(f"Rank {rank}: Training completed")
def run(rank, world_size, backend, master_addr, master_port, device):
os.environ['MASTER_ADDR'] = master_addr
os.environ['MASTER_PORT'] = str(master_port)
# os.environ['NCCL_SOCKET_IFNAME'] = 'ens6f0'
os.environ['GLOO_SOCKET_IFNAME'] = 'ens6f0'
init_process(rank, world_size, backend)
parallel_training(rank, world_size, device)
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Distributed training example")
parser.add_argument("--rank", type=int, default=0,
help="Rank of the current process")
parser.add_argument("--world-size", type=int, default=2,
help="Total number of processes")
parser.add_argument("--backend", type=str, default="gloo",
choices=["gloo"], help="Backend for distributed training")
parser.add_argument("--master-addr", type=str,
default="localhost", help="Master node address")
parser.add_argument("--master-port", type=int,
default=12355, help="Master node port")
parser.add_argument("--device", type=str, default="cuda:0",
help="Device to use (e.g., cuda:0, cuda:1)")
args = parser.parse_args()
run(args.rank, args.world_size, args.backend,
args.master_addr, args.master_port, args.device)
# Usage examples:
# On node 1:
# python main.py --rank=0 --world-size=2 --backend=gloo --master-addr=10.9.112.104 --master-port=4321 --device=cuda:0
# On node 2:
# python main.py --rank=1 --world-size=2 --backend=gloo --master-addr=10.9.112.104 --master-port=4321 --device=cuda:0
- 实验结论
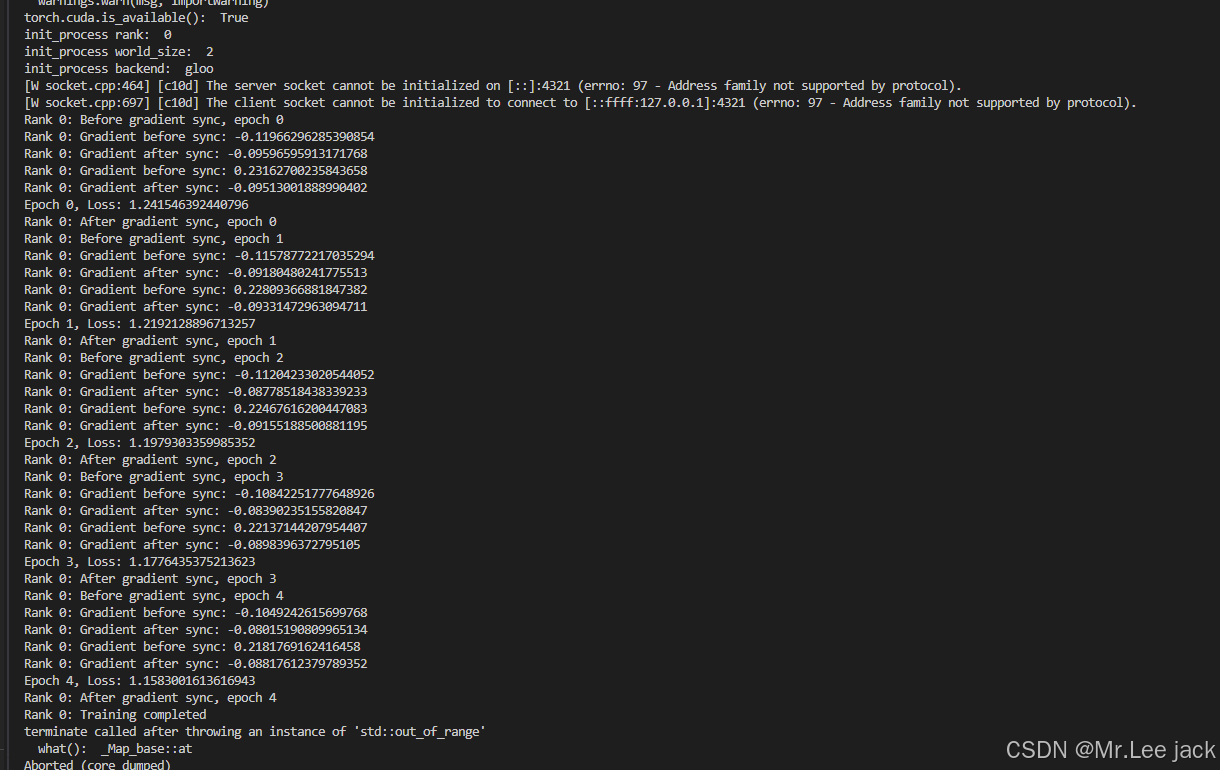
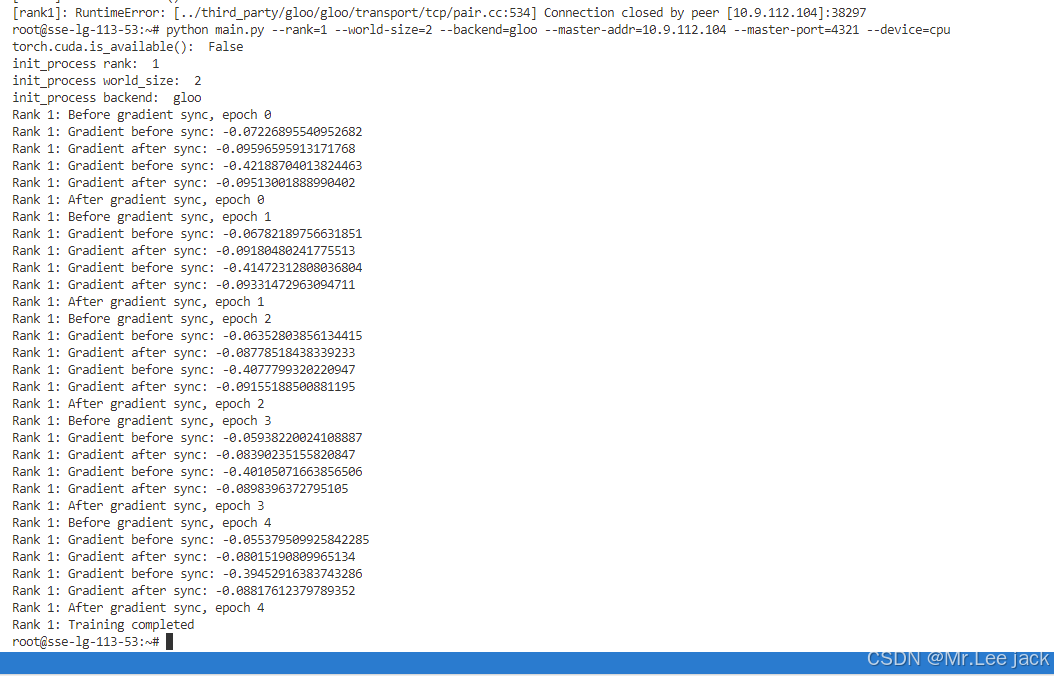
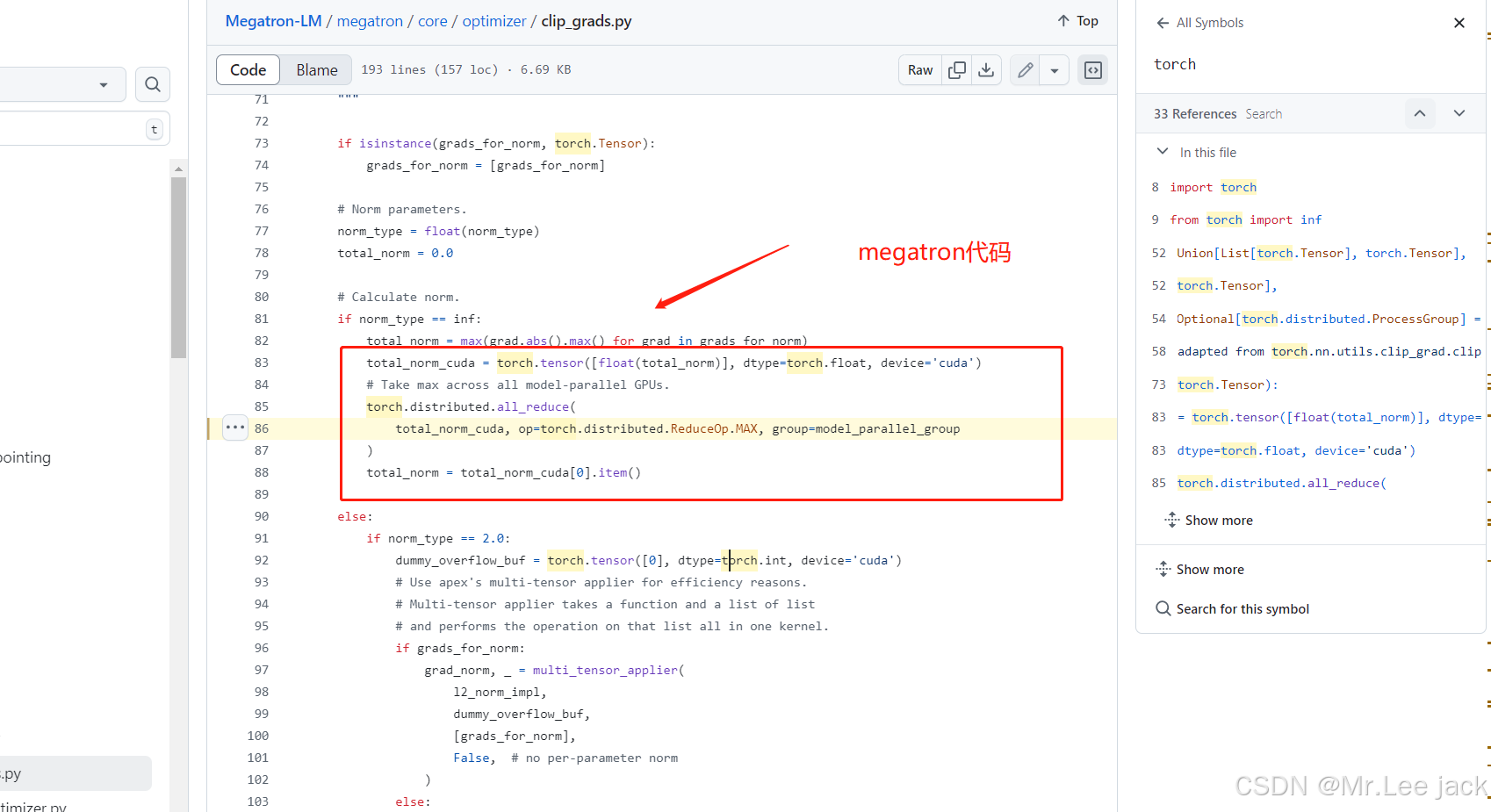
Megatron cuda 代码片段

















 1686
1686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









