







 超级会员免费看
超级会员免费看
一、AI 浪潮下的思考
当你与 Siri 轻松对话,让它帮你查询天气、设置提醒时;当你使用抖音,系统精准推送你可能感兴趣的视频时;当你看到特斯拉汽车在智能驾驶系统的操控下自动行驶在道路上时…… 不知你是否想过,这些看似平常却又充满科技感的体验背后,都离不开同一项强大的技术 —— 人工智能(Artificial Intelligence,简称 AI)。
人工智能这个词,如今频繁出现在我们的生活中,无论是科技新闻、商业报道,还是日常闲聊。它被视为改变未来的关键力量,人们对它寄予厚望,也充满好奇。但人工智能究竟是什么?它从何而来,又经历了怎样的发展历程,才一步步走进我们的生活,成为如今不可忽视的存在?今天,就让我们一同深入探索人工智能的世界,揭开它神秘的面纱。
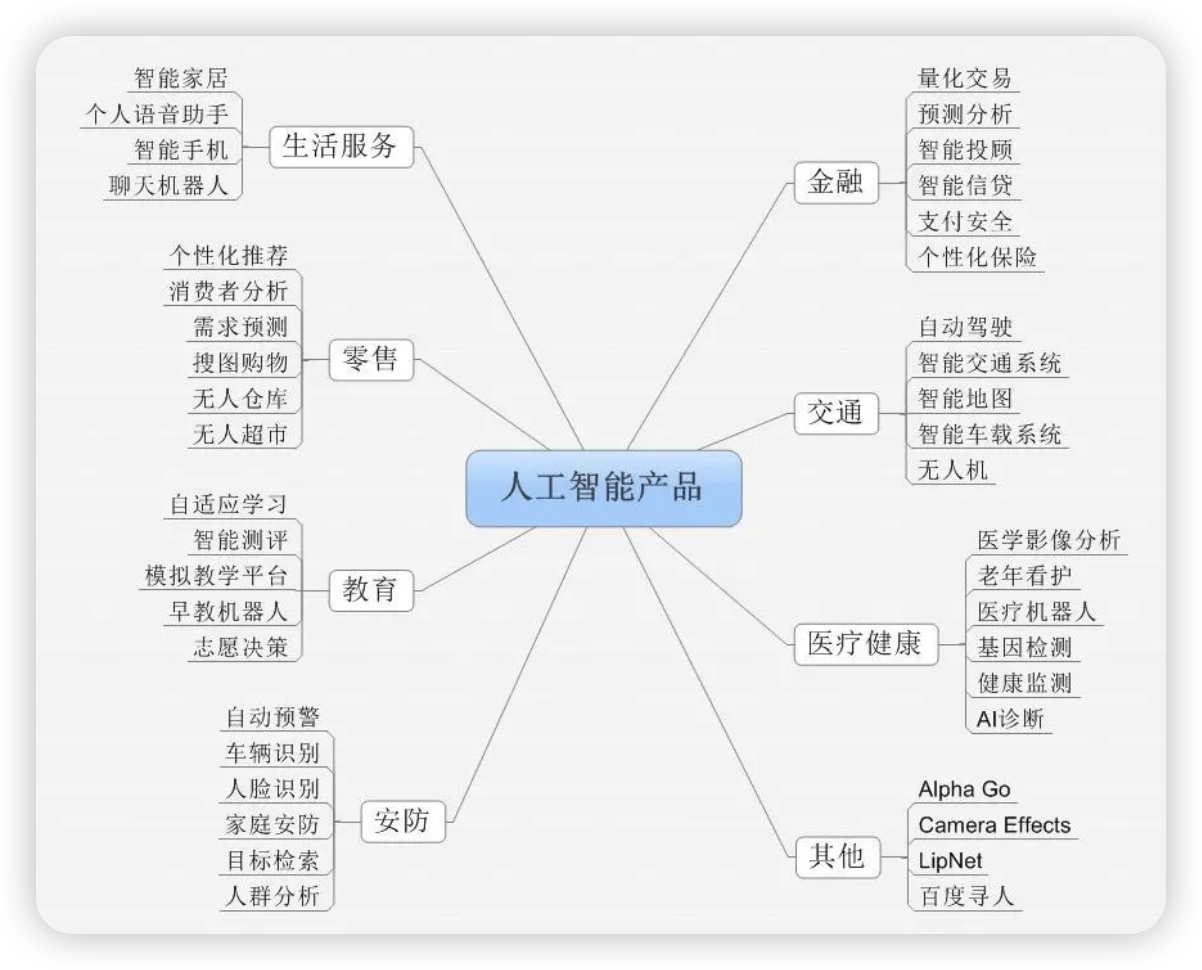
二、什么是人工智能?
1.1、人工智能定义
人工智能(Artificial Intelligence, AI)是研究开发能够模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的技术科学,其核心目标是使机器具备听、看、说、思考、学习和行动等能力。从技术层面看,AI通过机器学习(尤其是深度学习)实现智能行为,例如图像识别、自然语言处理等。
“百度百科”定义:人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
“维基百科”定义:人工智能(英语:Artificial Intelligence, AI)亦称机器智能,是指由人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序的手段实现的类人智能技术。该词同时也指研究这样的智能系统是否能够实现,以及如何实现的科学领域。
“你的理解?”

人工智能也是计算机科学的一个重要分支 ,一门多学科交叉的前沿领域,融合了计算机科学、数学、统计学、控制论、信息论、神经生理学、心理学、语言学、哲学等诸多学科的知识。
1.1、什么是机器学习?
机器学习是人工智能的核心技术之一,就像是给机器赋予了 “学习能力”。它让机器能够从大量的数据中自动学习模式和规律,而不需要人类为其编写具体的指令。比如,通过对大量图片的学习,机器可以学会识别不同的物体;通过分析海量的文本,机器能够理解语义并进行文本分类。
机器学习又包含监督学习、无监督学习和强化学习等不同的学习方式。监督学习就像有老师指导的学习过程,给机器提供带有标签的数据,让它学习如何对新的数据进行分类或预测;无监督学习则像是机器自己探索数据中的规律,没有预先给定的标签,比如从一堆客户数据中发现不同的客户群体;强化学习则是通过让机器在与环境的交互中不断尝试,根据得到的奖励或惩罚来学习最优的行为策略,就像游戏玩家在游戏中不断尝试不同的操作,以获得更高的分数,AlphaGo 就是通过强化学习算法战胜了人类围棋冠军。
1.2、什么是深度学习?
深度学习则是机器学习的一个分支领域,它基于人工神经网络,通过构建多层的神经网络结构来模拟人脑的学习过程。深度学习模型能够处理和学习十亿到千亿级别参数规模的复杂任务,在图像识别、语音识别、自然语言处理等领域取得了突破性进展。例如,卷积神经网络(CNN)在图像识别中表现出色,循环神经网络(RNN)及其变体长短期记忆网络(LSTM)在语音识别和自然语言处理中发挥着重要作用。
三、人工智能的发展简史
1、萌芽阶段(1950年前)
古希腊神话和中国古籍中已有对智能机械的想象,但受限于技术,这些记载更多是哲学或宗教层面的探讨。在古希腊神话里,工匠之神赫淮斯托斯打造了青铜巨人塔罗斯,它被赋予保护克里特岛的职责,能自行在岛屿周围巡逻,用石头或热金属攻击接近的船只,这可以看作是古人对自动化和机械生命体的幻想,反映了人类早期对非生命体执行复杂任务的期待。
17世纪莱布尼茨等学者提出“推理即计算”的思想,为计算机和AI奠定理论基础。
2、诞生与早期发展(-1970年代)
在近代,数理逻辑和计算机理论的发展为人工智能的诞生奠定了坚实的基础。19 世纪,英国数学家乔治・布尔提出了布尔代数,这是一种基于逻辑的代数系统,通过定义逻辑变量和逻辑运算,将逻辑推理转化为数学运算,使得计算机能够进行逻辑判断和推理。布尔代数为计算机的电路设计提供了理论基础,实现了计算机的基本逻辑功能,就如同为人工智能赋予了 “逻辑大脑”,让机器能够处理和理解逻辑关系,为后续的智能算法和程序设计提供了重要的工具。

1936 年,图灵提出了 “图灵机” 的概念
这是一种抽象的计算模型,由一个无限长的纸带、一个读写头和一组状态转移规则组成。图灵机可以模拟任何算法的操作,它从理论上为现代计算机的发展奠定了基础。
1950年图灵提出“图灵测试”,成为判断机器智能的标准 1956年达特茅斯会议正式确立“人工智能”学科,纽厄尔团队展示首个AI程序“逻辑理论家”

约翰・麦卡锡(John McCarthy)、马文・明斯基(Marvin Minsky)、纳森尼尔・罗切斯特(Nathaniel Rochester)和克劳德・香农(Claude Shannon)这四位在计算机科学、数学、信息论等领域颇具影响力的学者,共同发起了这次会议,他们希望通过汇聚不同领域的专家,系统性地探讨让机器模拟人类智能行为的可能性。
1957 年,弗兰克・罗森布拉特(Frank Rosenblatt)发明了感知机 ,这是一种模拟神经元学习过程的算法,也是最早的人工神经网络之一。
1966年首台聊天机器人ELIZA
1966 年麻省理工学院计算机科学家约瑟夫・维森鲍姆(Joseph Weizenbaum)开发的聊天机器人 ELIZA 具有重要意义 。ELIZA 以心理治疗为场景,通过模式匹配和预先编程的回复来模拟人与人之间的对话。
约翰・麦卡锡发明的 LISP(List Processing)语言也为人工智能的发展做出了重要贡献 。LISP 是一种专门为人工智能研究设计的编程语言,它具有强大的符号处理能力,能够方便地表示和处理知识、逻辑和推理。在早期的人工智能项目中,LISP 被广泛应用于专家系统、自然语言处理、机器学习等领域,成为了人工智能编程的主要语言之一。
1961 年,Unimation 公司推出了第一台工业机器人 Unimate,汉语音译名为“尤尼梅特”
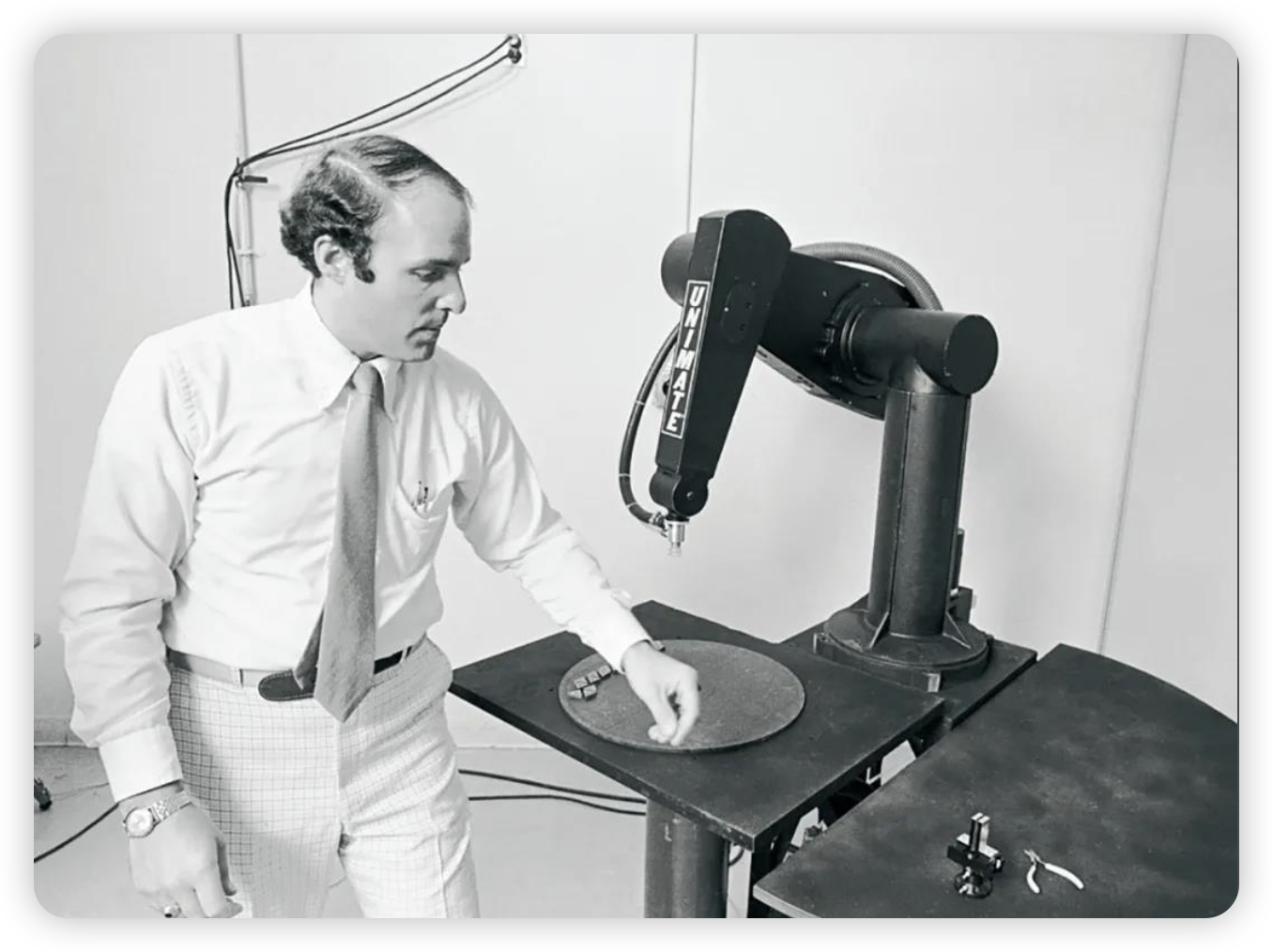
它被安装在通用汽车的生产线上,用于搬运和焊接工作。Unimate 的出现标志着机器人开始进入工业生产领域,开启了智能制造的先河。工业机器人能够按照预设的程序进行重复、精确的操作,大大提高了生产效率和产品质量,降低了人力成本,为现代制造业的发展带来了革命性的变化。
3、AI 发展的寒冬(1970 - 1980)
20 世纪 70 年代,人工智能的发展陷入了困境 。
1)算力不足
从技术层面来看,当时的计算机硬件性能有限,内存较小,计算速度较慢,这严重限制了人工智能算法的运行和应用。例如,早期的神经网络模型由于计算能力不足,无法处理大规模的数据和复杂的任务,导致其在实际应用中效果不佳。数据量有限也是一个重要问题,机器学习算法需要大量的数据来进行训练,以学习到准确的模式和规律,但在当时,数据的收集、存储和整理都面临着诸多困难,数据的匮乏使得机器学习算法难以发挥其优势。
2)算法方面也存在局限
早期的人工智能算法大多基于规则和逻辑推理,缺乏灵活性和适应性,难以应对复杂多变的现实世界。例如,在自然语言处理领域,基于规则的机器翻译系统在处理语言的歧义性、语义理解和上下文依赖等问题时,遇到了巨大的挑战,翻译结果往往不准确,甚至闹出笑话。像 “Time flies like an arrow” 这句话,简单按照规则翻译可能会得到 “时间苍蝇像箭一样” 这样荒谬的结果,因为它没有理解 “time flies” 作为一个整体的含义以及 “like” 在这里表示 “像…… 一样” 的比喻用法。在图像识别中,传统的算法对于图像的特征提取和分类能力有限,无法准确识别复杂背景下的物体,使得图像识别技术的应用范围受到很大限制。
3)缺少政府和组织支持
由于早期对人工智能的过度乐观预期未能实现,人们对人工智能的信心受到了严重打击 。研究进展的缓慢和实际应用成果的有限,使得各国政府和资助机构对人工智能研究的热情大幅下降,纷纷削减相关的研究经费。在美国,国防高级研究计划署(DARPA)对人工智能项目的资助大幅减少,许多依赖政府资金的研究项目被迫停止。例如,卡内基梅隆大学的一个人工智能项目,原本计划开发一个能够自主学习和决策的智能机器人,但由于资金短缺,项目不得不中途夭折,研究人员辛苦积累的成果也付诸东流。
在英国,莱特希尔关于人工智能的报告对人工智能的发展提出了严厉批评,认为当时的人工智能研究没有取得实质性的进展,导致政府停止了对人工智能研究的资助 。资金的削减使得许多人工智能实验室面临生存危机,大量研究人员因无法获得足够的资金支持而被迫转行,离开人工智能领域。
据统计,在这一时期,美国人工智能领域的研究人员数量减少了约一半,许多优秀的人才流失到了其他行业,整个领域陷入了低迷状态,研究工作几乎停滞不前。这一时期被称为人工智能的 “寒冬”,人工智能的发展陷入了前所未有的困境 。
4、复兴(1980-2010年)
1980年代专家系统(如医疗诊断工具)兴起
1997年IBM“深蓝”击败国际象棋冠军,展现机器学习潜力
1)专家系统兴起
20 世纪 80 年代,人工智能迎来了新的发展机遇,专家系统成为这一时期的研究热点 。专家系统是一种基于知识的智能系统,它将领域专家的知识和经验以特定的形式存储在知识库中,通过推理机运用这些知识来解决特定领域的问题,能够模拟人类专家的决策过程,为用户提供专业的建议和解决方案。
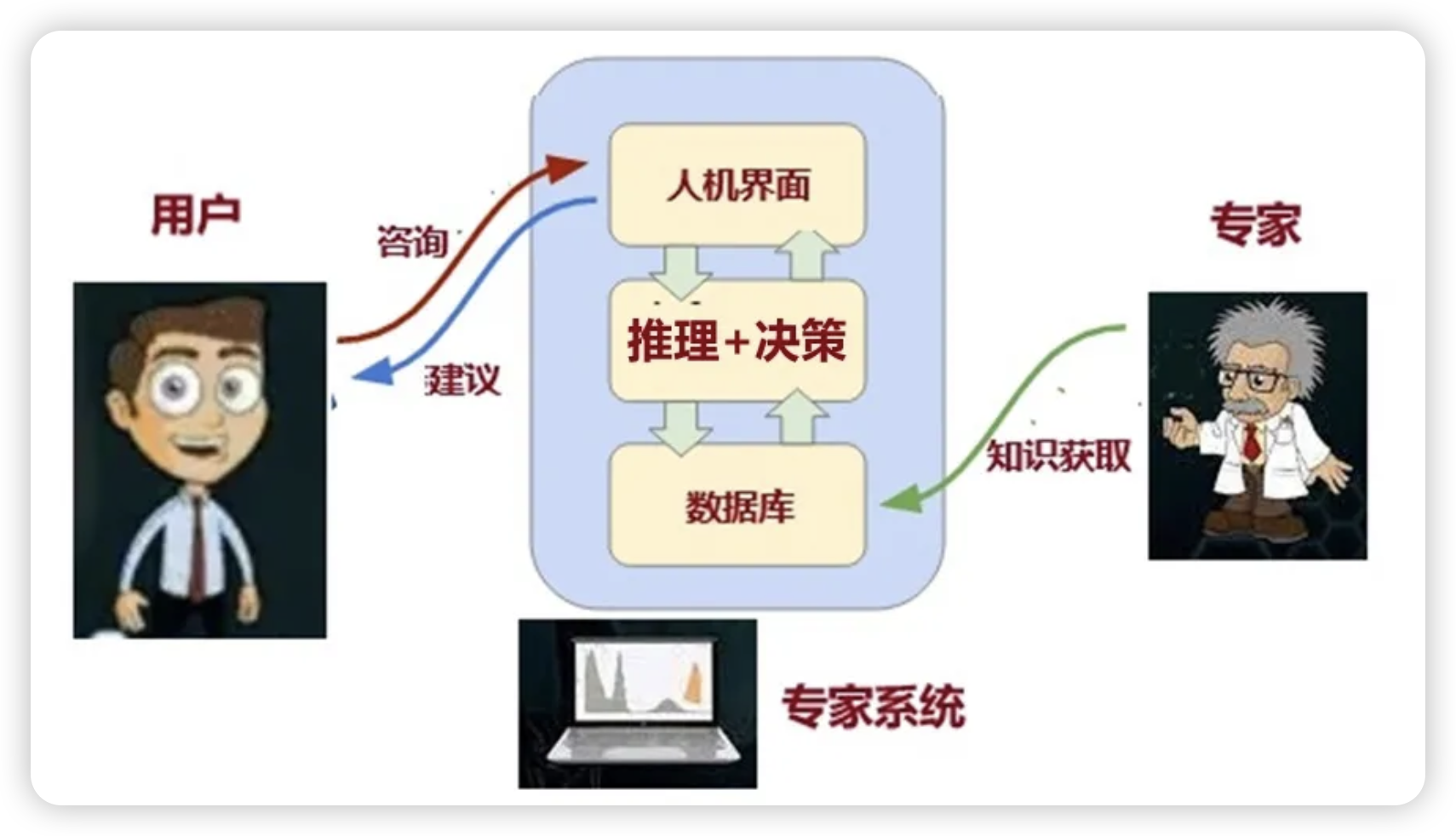
Dendral和MYCIN是那个时期比较有代表性的专家系统之一。
Dendral 是最早也是最著名的专家系统之一 ,由斯坦福大学的爱德华・费根鲍姆(Edward Feigenbaum)等人于 1968 年开发。Dendral 主要用于分析有机化合物的分子结构,它能够根据化合物的质谱数据和化学家的经验知识,推断出可能的分子结构。在当时,确定有机化合物的分子结构是一项复杂且耗时的工作,需要化学家进行大量的实验和分析。Dendral 的出现大大提高了这一工作的效率,它通过将质谱数据与知识库中的规则和模式进行匹配,快速生成可能的分子结构假设,并对这些假设进行评估和筛选,最终得出最合理的分子结构。
MYCIN 则是医疗领域中极具代表性的专家系统 ,由斯坦福大学的布鲁斯・布坎南(Bruce Buchanan)和爱德华・肖特利夫(Edward Shortliffe)于 1972 年开发。MYCIN 旨在帮助医生诊断和治疗细菌感染疾病,它能够根据患者的症状、病史、实验室检查结果等信息,运用知识库中的医学知识和推理规则,判断患者可能感染的细菌种类,并给出相应的治疗建议。MYCIN 的知识库中包含了大量的医学知识,如各种细菌的特征、感染症状、治疗方法等,以及基于这些知识制定的推理规则。当输入患者的相关信息后,MYCIN 会通过推理机对这些信息进行分析和推理,逐步缩小可能的细菌种类范围,最终确定最有可能的致病菌,并根据该病菌的耐药性和患者的具体情况,推荐合适的抗生素和治疗方案。在实际应用中,MYCIN 对一些复杂的细菌感染病例的诊断和治疗提供了有效的支持,展现出了人工智能在医疗领域的潜力。
用于地质勘探的 PROSPECTOR 系统,它能够根据地质数据和专家知识,预测地下矿产资源的分布情况;用于企业管理的 XCON 系统,能够帮助企业进行计算机系统的配置和设计。
2)机器学习的蓬勃发展
在专家系统蓬勃发展的同时,机器学习也在不断演进 。机器学习是人工智能的核心领域之一,它让计算机能够从数据中自动学习模式和规律,而无需人类为其编写明确的规则。早期的机器学习算法相对简单,主要依赖于人工设定的特征和规则,学习能力有限。但随着时间的推移,机器学习算法逐渐从简单的基于规则的学习向数据驱动的学习转变。
20 世纪 80 年代,机器学习领域取得了一些重要进展 。决策树算法在这一时期得到了广泛研究和应用,它通过构建树形结构来对数据进行分类和预测。决策树算法根据数据的特征进行分裂,每个内部节点表示一个特征上的测试,每个分支表示一个测试输出,每个叶节点表示一个类别。例如,在判断水果是苹果还是橙子时,决策树可以根据水果的颜色、形状、大小等特征进行逐步判断。如果颜色是红色,形状是圆形,那么可能是苹果;如果颜色是橙色,形状是圆形且皮比较厚,那么可能是橙子。决策树算法具有直观、易于理解和实现的特点,能够处理分类和回归等多种问题,在数据挖掘、模式识别等领域得到了广泛应用。
神经网络在这一时期也迎来了复苏 。在经历了 70 年代的低谷后,随着计算能力的提升和算法的改进,神经网络重新受到关注。1986 年,大卫・鲁梅尔哈特(David Rumelhart)、杰弗里・辛顿(Geoffrey Hinton)和罗纳德・威廉姆斯(Ronald Williams)提出了反向传播算法(Backpropagation Algorithm),这一算法解决了多层神经网络的训练难题,使得神经网络能够处理更复杂的任务。反向传播算法通过计算输出层与期望输出之间的误差,并将误差反向传播到网络的每一层,来调整神经元之间的连接权重,从而使网络的输出更接近期望输出。例如,在手写数字识别中,通过大量的手写数字图像数据对神经网络进行训练,反向传播算法不断调整网络权重,使得网络能够准确识别不同的手写数字。反向传播算法的提出,为神经网络的发展注入了新的活力,推动了神经网络在图像识别、语音识别、自然语言处理等领域的应用。
到了 90 年代,机器学习算法进一步发展 ,支持向量机(Support Vector Machine,SVM)等新的算法被提出。支持向量机是一种基于统计学习理论的分类算法,它通过寻找一个最优的分类超平面,将不同类别的数据分开。支持向量机在处理小样本、非线性分类问题时表现出色,具有良好的泛化能力和鲁棒性。例如,在文本分类中,支持向量机可以将不同主题的文本准确地分类到相应的类别中。SVM 的出现,为机器学习领域提供了一种强大的工具,进一步拓展了机器学习的应用范围。
这一时期,机器学习在图像识别、语音识别等领域开始得到初步应用 。在图像识别方面,机器学习算法可以通过对大量图像数据的学习,识别图像中的物体、场景等。例如,通过训练一个基于机器学习算法的图像识别系统,可以让它识别出照片中的动物是猫还是狗。在语音识别领域,机器学习算法能够将人类的语音信号转换为文本,实现语音到文字的转换。虽然当时的图像识别和语音识别技术还不够成熟,准确率有待提高,但这些初步的应用为后续的发展奠定了基础,展示了机器学习在感知领域的潜力 。
3)深蓝战胜卡斯帕罗夫
1997 年,一场举世瞩目的人机大战吸引了全球的目光,IBM 的深蓝计算机(Deep Blue)与国际象棋世界冠军加里・卡斯帕罗夫(Garry Kasparov)展开了一场激烈的对弈 。深蓝是一台专门为下国际象棋而设计的超级计算机,它拥有强大的计算能力,能够在短时间内分析大量的棋局变化。在这场六局的对抗赛中,深蓝充分发挥了其计算速度快的优势,通过对海量棋局数据的分析和评估,制定出最优的下棋策略。

4、深度学习时代(2011年-至今)
2010年后GPU和大数据推动神经网络突破,AlphaGo(2016年)和Transformer模型(2017年)成为里程碑 当前大语言模型(如GPT系列)推动通用人工智能(AGI)探索,同时引发伦理争议
1)深度学习的突破:神经网络的快速发展
进入 21 世纪第二个十年,人工智能迎来了爆发式增长 ,而深度学习的突破是这一时期的关键驱动力。2012 年,由杰弗里・辛顿(Geoffrey Hinton)团队开发的 AlexNet 在 ImageNet 大规模视觉识别挑战赛(ILSVRC)中夺冠,这一事件成为了深度学习发展的重要转折点 。ImageNet 是一个拥有超过 1400 万张带标签图像的大型数据库,涵盖了 2 万多个不同的类别,ILSVRC 则是计算机视觉领域极具影响力的国际竞赛,吸引了全球众多顶尖科研团队和企业参与。在当年的竞赛中,AlexNet 以远超第二名的成绩脱颖而出,其错误率比第二名降低了近 10 个百分点,展现出了深度学习在图像识别任务上的强大能力。
在语音识别领域,深度学习也取得了重大突破 。传统的语音识别系统主要依赖于高斯混合模型 - 隐马尔可夫模型(GMM - HMM),但这种方法在处理复杂语音环境和大规模语音数据时存在一定的局限性。随着深度学习的发展,基于深度学习的语音识别模型逐渐取代了传统模型。深度神经网络(DNN)、循环神经网络(RNN)及其变体长短时记忆网络(LSTM)等被广泛应用于语音识别中。这些模型能够自动从语音信号中学习到更有效的特征表示,从而提高语音识别的准确率。
在自然语言处理领域,深度学习同样带来了革命性的变化 。传统的自然语言处理方法主要基于规则和统计模型,在处理语义理解、上下文依赖等复杂问题时面临挑战。深度学习的发展为自然语言处理带来了新的思路和方法,神经网络语言模型(NNLM)、循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)等被广泛应用于自然语言处理任务中。2017 年,谷歌团队提出了 Transformer 架构,这一架构在自然语言处理领域引起了巨大的轰动 。Transformer 摒弃了传统的循环和卷积结构,采用了自注意力机制(Self - Attention),能够更好地捕捉文本中的长距离依赖关系,大大提高了自然语言处理任务的性能。基于 Transformer 架构,谷歌推出了 BERT(Bidirectional Encoder Representations from Transformers)模型,它通过在大规模语料上进行预训练,学习到了丰富的语言知识和语义表示,在多个自然语言处理任务上取得了当时的最优成绩,如文本分类、命名实体识别、情感分析、问答系统等。
OpenAI 基于 Transformer 架构开发的 GPT(Generative Pretrained Transformer)系列模型,在自然语言生成任务中表现出色,能够生成高质量的文本,如文章、对话、代码等,引发了全球对生成式人工智能的关注和研究热潮 。
2)生成式人工智能的崛起
生成式人工智能是人工智能领域近年来的重要发展方向,它能够根据给定的输入或条件,生成全新的内容,如文本、图像、音频、视频等 。生成式人工智能的核心技术包括生成对抗网络(GAN)、变分自编码器(VAE)和生成式预训练 Transformer(GPT)等。
生成对抗网络(GAN)由伊恩・古德费洛(Ian Goodfellow)于 2014 年提出 ,它由生成器和判别器组成。生成器负责生成新的数据样本,判别器则用于判断生成的数据样本是真实的还是生成的。生成器和判别器通过不断地对抗训练,使得生成器生成的数据越来越逼真,判别器越来越难以区分真实数据和生成数据。GAN 在图像生成领域取得了显著的成果,能够生成高质量的图像,这些图像几乎与真实照片无异,甚至在一些图像生成竞赛中,StyleGAN 生成的图像能够骗过人类评委,被误认为是真实照片。
生成式人工智能在图像生成领域也取得了长足的发展 。除了前面提到的 GAN 和 VAE,近年来,扩散模型(Diffusion Model)成为了图像生成领域的研究热点。扩散模型通过在数据上逐步添加噪声,然后再通过反向过程从噪声中恢复出原始数据,从而学习到数据的分布,实现图像生成。
StableDiffusion 和 Midjourney 是基于扩散模型的代表性图像生成工具,它们能够根据用户输入的文本描述生成高质量、富有创意的图像。用户只需输入简单的文字,如 “一幅未来城市的科幻画,有飞行的汽车和闪耀的摩天大楼”,这些工具就能快速生成符合描述的精美图像,在艺术创作、设计、广告等领域得到了广泛应用 。
3)人工智能的广泛应用
如今,人工智能已经广泛应用于各个领域,深刻地改变着社会经济和人们的生活 。
在自动驾驶领域,特斯拉的 Autopilot 和英伟达的 DRIVE 等自动驾驶系统,通过摄像头、雷达、激光雷达等传感器收集车辆周围的环境信息,然后利用深度学习算法对这些信息进行分析和处理,识别道路、车辆、行人、交通标志等物体,并做出决策,控制车辆的行驶速度、方向和制动,实现自动行驶。
医疗诊断是人工智能应用的重要领域之一 ,IBM Watson for Oncology 能够分析患者的病历、症状、检查结果等数据,为医生提供癌症诊断和治疗建议;谷歌的 DeepMind Health 开发的 AI 系统可以通过分析眼底图像,检测出糖尿病视网膜病变、青光眼等眼部疾病,其准确率与专业眼科医生相当;国内的推想医疗利用人工智能技术,在胸部 CT 影像诊断中,能够快速检测出肺部结节、肺炎等疾病,并提供风险评估和诊断建议,辅助医生进行决策 。
金融风控是金融行业的关键环节,蚂蚁金服的风险大脑利用机器学习算法,实时监控和分析海量的交易数据,能够快速识别出欺诈交易、信用风险等异常情况,保障金融交易的安全;一些量化投资公司利用人工智能技术构建投资模型,通过对市场数据的实时分析和预测,制定投资策略,实现资产的优化配置和风险控制 。
在教育领域,松鼠 AI 的智适应学习系统通过对学生答题数据的分析,能够精准定位学生的知识薄弱点,为学生推送个性化的学习内容,帮助学生提高学习效率;一些在线教育平台利用人工智能技术实现了智能批改作业、智能答疑等功能,减轻了教师的工作负担,提高了教学质量 。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











