







原文:
前言:这篇不是行人轨迹预测的具体方法,算是综述吧~
一、前言
避免涉及行人等弱势道路使用者的事故是自动驾驶车辆的重要目标和挑战,行人轨迹预测是研究热点。现有的行人轨迹预测方法包括基于知识的方法,如常数速度模型 CVM、社会力模型等和基于学习的方法,如 Social - LSTM、Social GAN、Trajectron++、Y - Net、AgentFormer、Social - Implicit 等,但当前的评估方法在量化其对自动驾驶系统的适用性方面存在不足。
于是作者对现有行人轨迹预测方法在生成单条轨迹时的准确性、特征需求和计算效率进行研究评估,为未来算法发展提供指导。
二、本文对比的几个经典模型
1、Social GAN
可以说这是一个基本的GAN的模型,它的生成器、鉴别器是由LSTM组成而已。模型的输入实际上就是一段处理过后的轨迹,先将轨迹映射到高维空间,然后交给生成器的编码器处理,得到每个行人的hidden_state,将hidden_state通过Pooling Module模块,得到的输出与之前的hidden_state、noise_z进行concat后作为生成器的解码器的orignal hidden_state,再得到预测的轨迹;在判别阶段,将生成的轨迹与真实轨迹丢给鉴别器以输出real还是fake。
本实验使用没有池化模块的模型,因为原论文也提出,这种模型提供了相同的性能而复杂度更低。

2、Y-Net
默认采样 20 条潜在轨迹的模式包含 TTST 和 CWS,由于聚类不能应用于单轨迹,禁用 TTST 模式以减少推理时间。在限制观察运动历史时,用最早观察值覆盖缺失时间步,因为 Y - Net 使用位置数据将轨迹编码到提供的地图中。
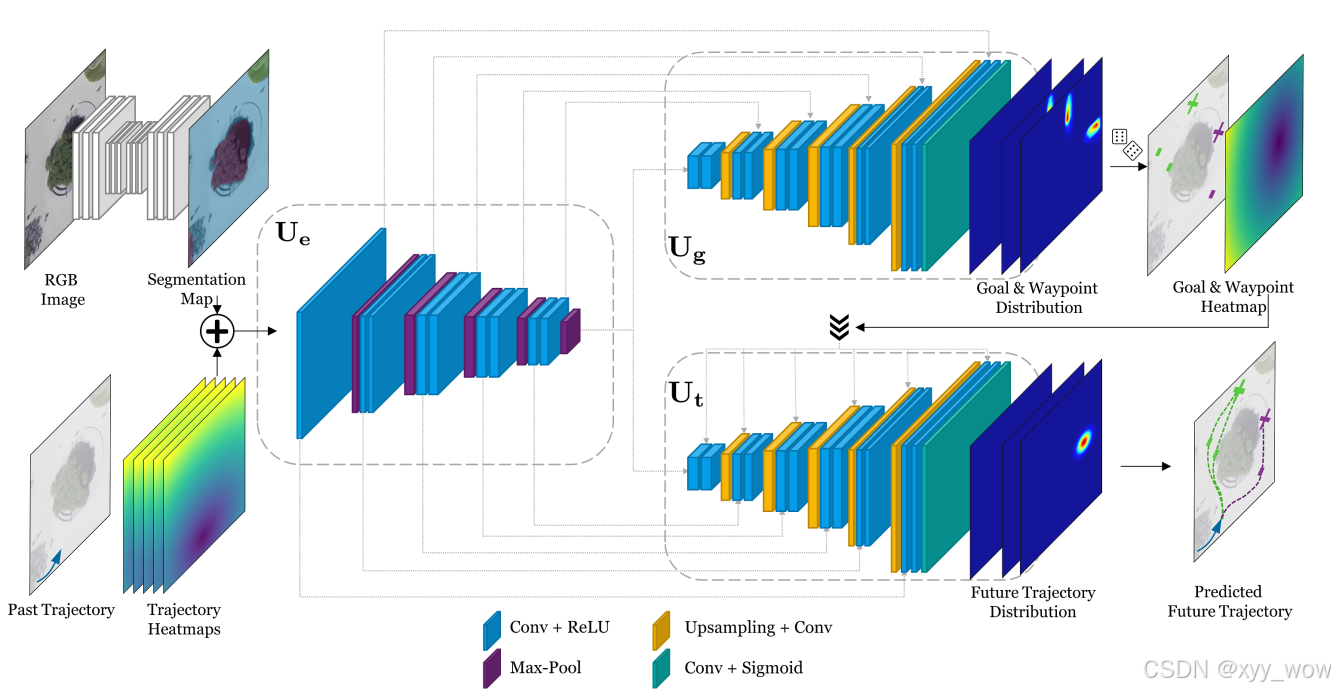
3、Trajectron++
该模型提供不同评估模式,本研究使用 Z - Mode,因其在减少运行时间的同时能提供与论文中 “最可能” 模式几乎相同的结果。

4、Social Implicit
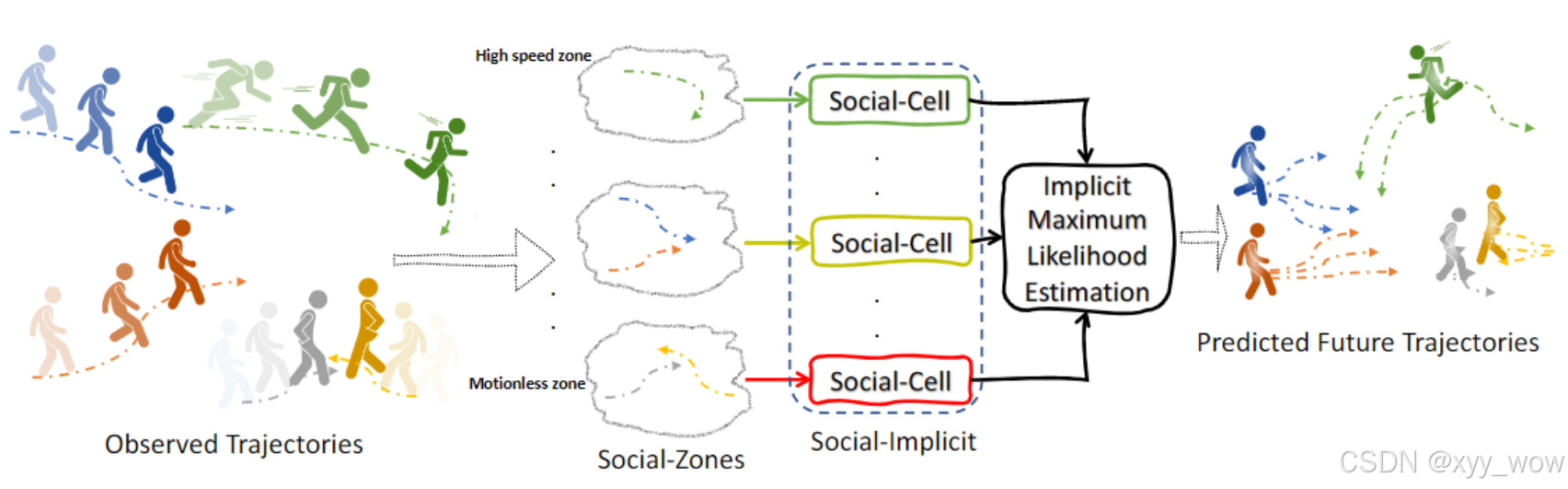
5、AgentFormer

三、实验评估及结果
3.1 评估过程
评估标准有以下三个:准确性、特征需求(限制时间观察步的数量)、运行时间。
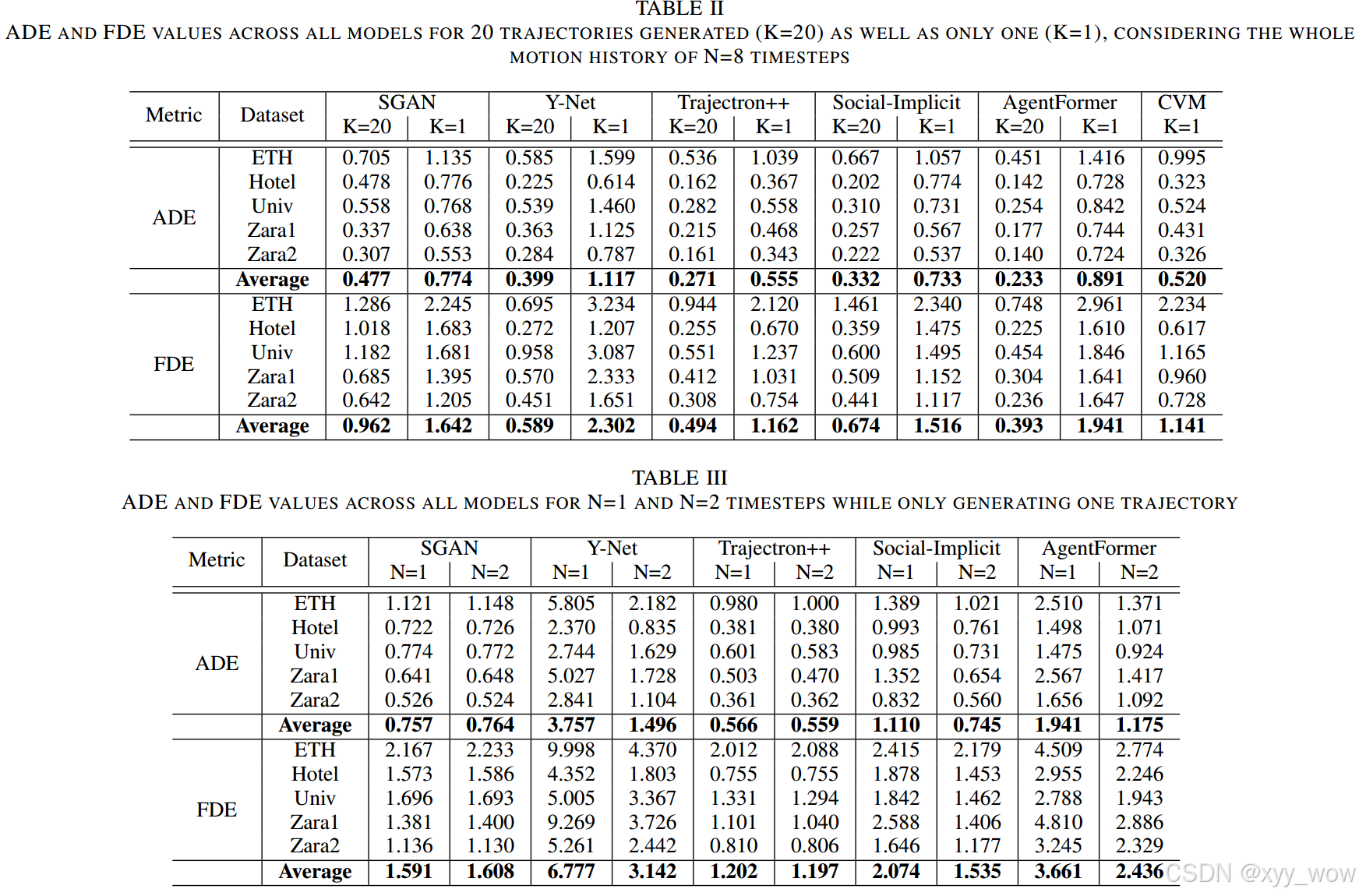
为了进行全面比较,使用各个模型提供的评估脚本来确定ADE和FDE。尽管这些指标在采用 Best - of - N(BoN)评估时存在不足,但在预测单条轨迹时能提供有价值的准确性见解。由于大多数模型具有不确定性,且某些情况下轨迹是随机采样而非选择最可能的轨迹,因此对 ETH/UCY 数据集中的每个场景进行五次评估,然后计算每个场景的平均值,最后汇总得出整体结果。在评估过程中,通过调整相应变量,分别对模型采样一条轨迹和二十条轨迹的情况进行测试,以全面了解模型性能。
研究关注输入特征中的时间信息,因为所有算法在场景中都使用了每个行人八个时间步的运动历史。为了探究其影响,通过修改模型输入张量,将可用观察时间步限制为仅最后一个或最后两个,以模拟极端情况并深入了解模型的工作原理。在限制观察时间步的情况下,对模型进行测试并计算相应的 ADE 和 FDE 指标。
使用 PyTorch 的内置 CUDA - API 精确测量每个模型的执行时间,从提供场景输入到接收所有行人预测的整个过程,不包括数据预处理时间,以评估模型在不同场景规模下的计算效率和扩展性。
3.2 数据集
ETH/UCY数据集。
采用留一法交叉验证,将五个场景(Eth、Hotel、Univ、Zara1 和 Zara2)中的四个用于训练,剩余一个用于测试。
3.3 结果分析
3.3.1 结果展示
A. 准确性
运动历史由8个时间步长组成,预测范围为12个时间步长。选择常数速度模型(CVM,即假设智能体在短时间内保持恒定的速度和方向)作为基线,因其在之前研究中表现良好且未被所研究的其他模型用作参考。
当采样20条轨迹(图中深色),所研究的模型在 ETH/UCY 数据集上表现出色,超过了 CVM 基线。AgentFormer 在 Best - of - N 评估中表现最佳,Trajectron++ 紧随其后。然而,作者无法复现 Y - Net 的报告结果,且 Trajectron++ 由于速度和加速度导数问题,值略差。
当仅采样1条轨迹(图中浅色),情况发生变化,所有模型的FDE均超过一米,SGAN 架构受影响最小,AgentFormer 性能显著下降,Trajectron++ 产生的预测最精确。有趣的是,此时没有一个模型超过CVM 的性能。
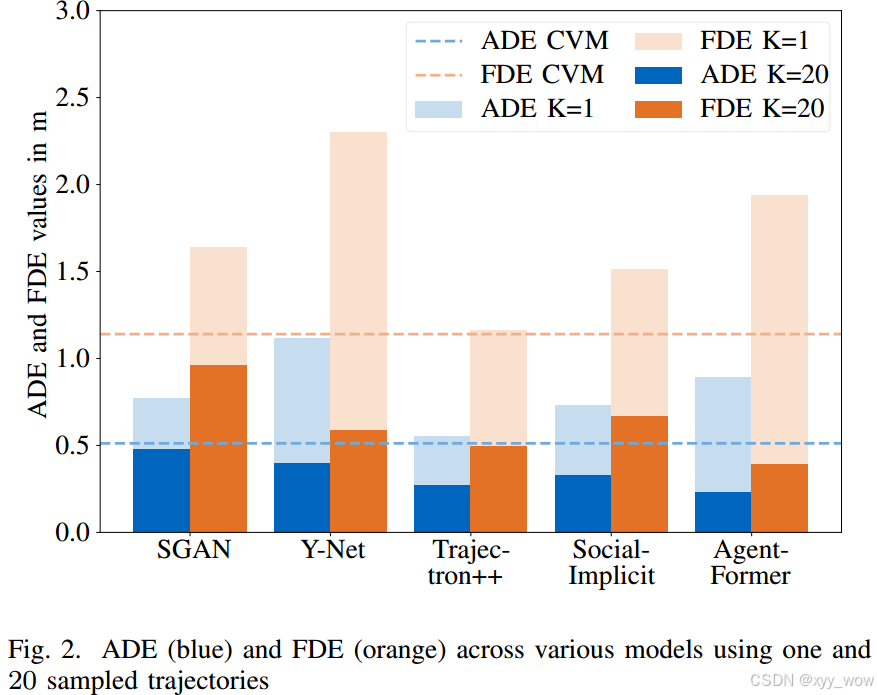
B. 不同的特征需求
为深入了解模型内部工作原理,作者将提供给每个模型的观察时间步限制为一个、两个和八个,以探究运动历史对模型性能的影响。
实验结果表明,ADE和FDE在所有研究方法中呈现相似趋势,即考虑所有时间步时误差最低;当信息减少到一个时间步时,AgentFormer 和 Y - Net 性能下降明显,而其他三个模型在一或两个时间步时性能几乎无差异,当为 AgentFormer 和 Y - Net 提供额外时间步时,两者的ADE、FDE均显著降低;Social - Implicit 在增加一个观察时间步时 ADE 有所改善,而 Trajectron++ 和 SGAN 的准确性变化小于 1 厘米,且与考虑整个运动历史时的位移几乎相同;
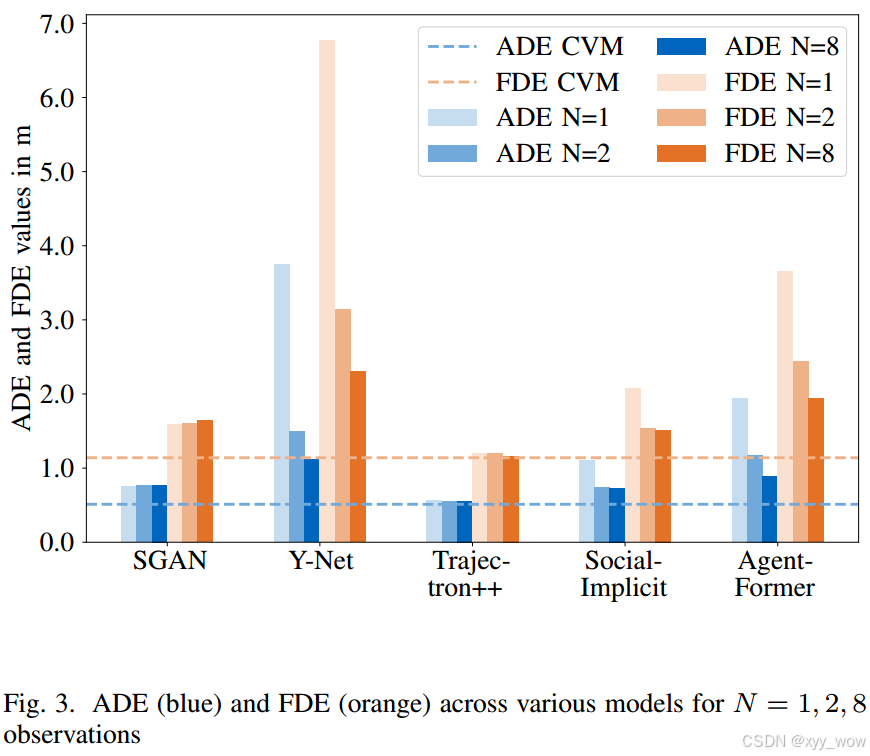
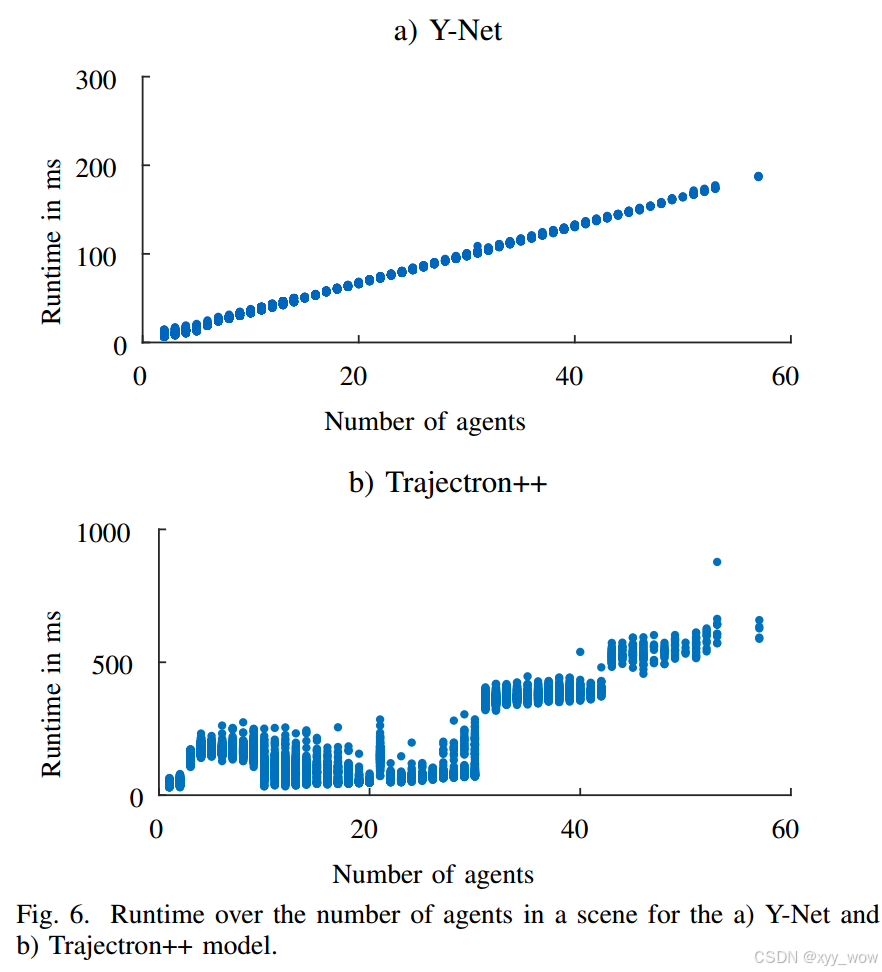
C. 运行时间
每个模型评估五次,计算中位数执行时间和四分位间距(IQR),以衡量运行时间的集中趋势和变异性。
实验结果表明,CVM 运行时间最短,中位数推理时间为 0.15 毫秒,且 IQR 最小,表明其运行时间最稳定。Trajectron++ 运行时间最长,中位数最高,为 131.34 毫秒,且 IQR 也最高,显示其运行时间波动大。Social - Implicit、SGAN 和 AgentFormer 的中位数运行时间分别为 1.69 毫秒、4.02 毫秒和 49.01 毫秒,其中 Social - Implicit 和 SGAN 的 IQR 较低(分别为 0.11 毫秒和 0.22 毫秒),表明其运行时间对场景中行人数量的依赖性较弱,而 Y - Net 中位数运行时间为 82.39 毫秒,IQR 为 96.87 毫秒,与 Trajectron++ 类似,运行时间长且不稳定。相比之下,AgentFormer 的 IQR 为 4.92 毫秒。
值得一提的是,结果显示模型运行时间与达到的 ADE 之间没有直接相关性。因为尽管 CVM 运行时间最短且 ADE 最小,但第二准确的 Trajectron++ 运行时间中位数却最高。
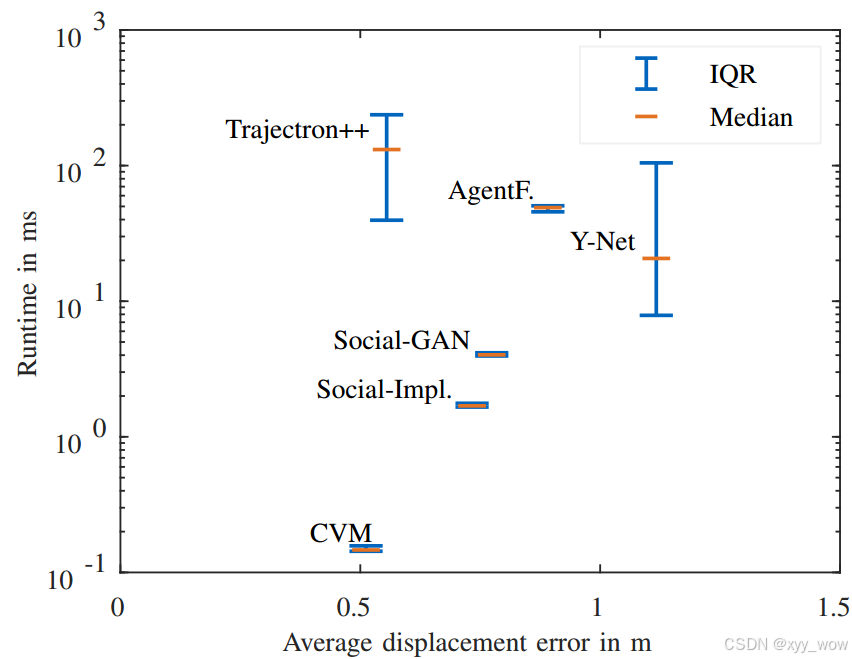
3.3.2 定量分析
模型准确性分析。AgentFormer 和 Trajectron++ 在 Best - of - N 评估中表现出色,这可能得益于它们采用的条件变分自编码器(CVAE),能生成合理且多模态的轨迹。尽管两者都有注意力机制来编码场景交互,但 AgentFormer 的注意力机制对整体准确性影响不大;仅考虑最可能轨迹时,AgentFormer 准确性大幅下降,而 Trajectron++ 仍领先,这与其采用的高斯混合模型返回最可能路径的评估程序有关。Social Implicit 在没有额外评估步骤时排名第二,两者都使用基于图的网络,显示出该架构在考虑空间交互方面的潜在优势,但时间建模的作用未充分发挥。下图是实验的全部具体数值结果。
模型运行时间分析。Trajectron++ 准确性高但推理时间长,因其依赖 LSTM 架构。Social - Implicit 采用前馈神经网络,推理速度快且扩展性好。Y - Net 虽使用 CNN 但因模型大且逐个预测行人导致运行时间长且扩展性差,AgentFormer 因参数多运行时间高但生成多轨迹时扩展性较好。并行生成轨迹可加快运行时间,但顺序方法在适应预测范围变化时更灵活。综合考虑,CVM 在准确性和运行时间权衡上表现突出,与之前基于 Best - of - N 评估的先进模型表现不同。下图是补充说明模型运行时间在实际应用场景中的变化趋势。
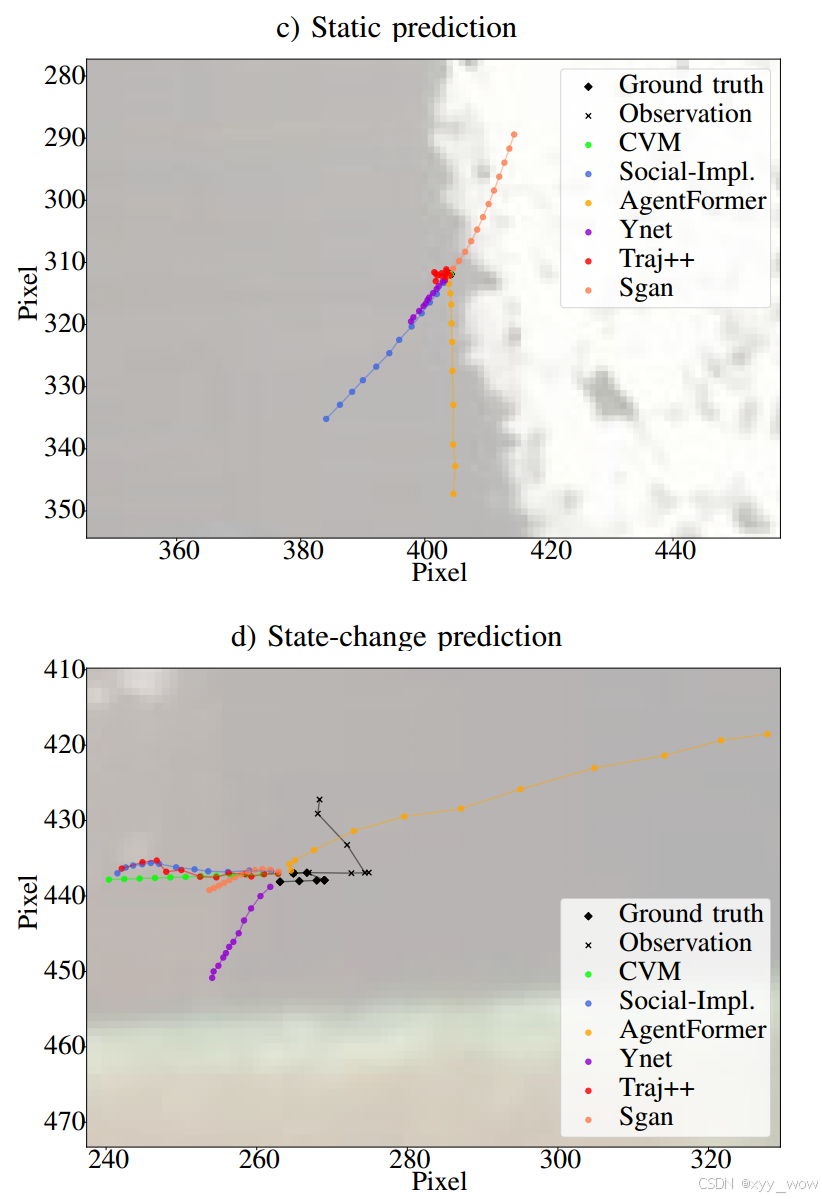
3.3.3 定性分析
- 线性预测场景:行人运动呈线性时,各模型有方向性差异,CVM 和 Trajectron++ 预测较准确,简单 CVM 在此类场景中能提供较好近似,但这类场景在数据集中占比小。
- 非线性预测场景:神经网络在生成非线性轨迹上有优势,但所研究模型都无法完全捕捉场景动态,此类场景存在固有不确定性,改进需考虑行人内部状态,同时环境因素影响决策时神经网络更有优势,且线性预测常能近似非线性情况。
- 静态预测场景:静态行人场景常见于城市环境,是模型性能差异的主要原因之一。所有模型在无位置变化时仍生成轨迹且方向不定,反映出部分模型难以推断行人目标意图,数据集中静态场景代表性不足可能是原因之一,AgentFormer 和 Y - Net 虽考虑更多时间步且 Y - Net 能推理目标,但仍未有效利用信息,CVM 和 Trajectron++ 在此类场景中表现相对较好。
- 状态变化预测场景:行人运动状态在观察和真实情况间变化的场景常见于交通环境,所有研究模型都无法识别行人意图,考虑空间信息虽可能预测但对人类司机也是挑战,此类场景凸显了考虑运动历史和语义线索等额外信息的重要性。

四、总结
研究对自动驾驶系统中的行人轨迹预测方法进行了全面评估,主要关注了三个方面:基于单条轨迹测量ADE和FDE,探究运动历史中单个时间步对预测的影响,以及测量不同场景规模下模型的运行时间。通过这些评估方法,对多种先进的行人轨迹预测模型(包括 SGAN、Y - Net、Trajectron++、Social - Implicit、AgentFormer 以及作为基线的常数速度模型 CVM)在 ETH/UCY 数据集上进行了实验。
准确性方面,利用基于图的交互建模的trajectory ++和Social-Implicit表现最好。运行时间方面,Social - Implicit 在准确性和运行时间的权衡中总体表现最佳,仅次于 CVM 在 ETH/UCY 数据集上的表现。
本研究也具有局限性:(1)研究结果的普适性存疑,不确定能否推广到其他数据集(如 SDD 或 nuScenes),因为上下文信息在决策中起重要作用,预计 CVM 在更复杂交通环境的非线性场景中表现会更差。(2)ETH/UCY 数据集仅含行人数据,实际应用需考虑其他道路使用者和基础设施,非均匀运动的处理仍是挑战和开放研究课题。(3)留一法交叉验证与实际应用不符,实际仅用一个模型,且预测方法跨场景和数据集的转移性仍是挑战。

















 3993
3993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









