






 这篇博客探讨了机器学习中的基本概念,包括分类任务(如二分类和多分类)和回归任务(预测连续值),并介绍了有监督学习和无监督学习的区别。文中提到了NFL定理,强调了针对具体问题选择合适算法的重要性,同时阐述了归纳偏好中的奥卡姆剃刀原则,提倡简洁有效的解决方案。
这篇博客探讨了机器学习中的基本概念,包括分类任务(如二分类和多分类)和回归任务(预测连续值),并介绍了有监督学习和无监督学习的区别。文中提到了NFL定理,强调了针对具体问题选择合适算法的重要性,同时阐述了归纳偏好中的奥卡姆剃刀原则,提倡简洁有效的解决方案。
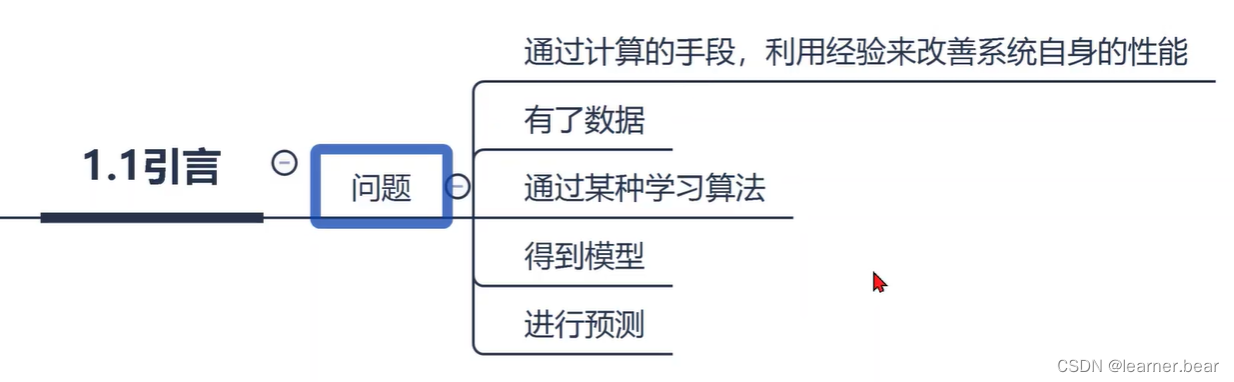
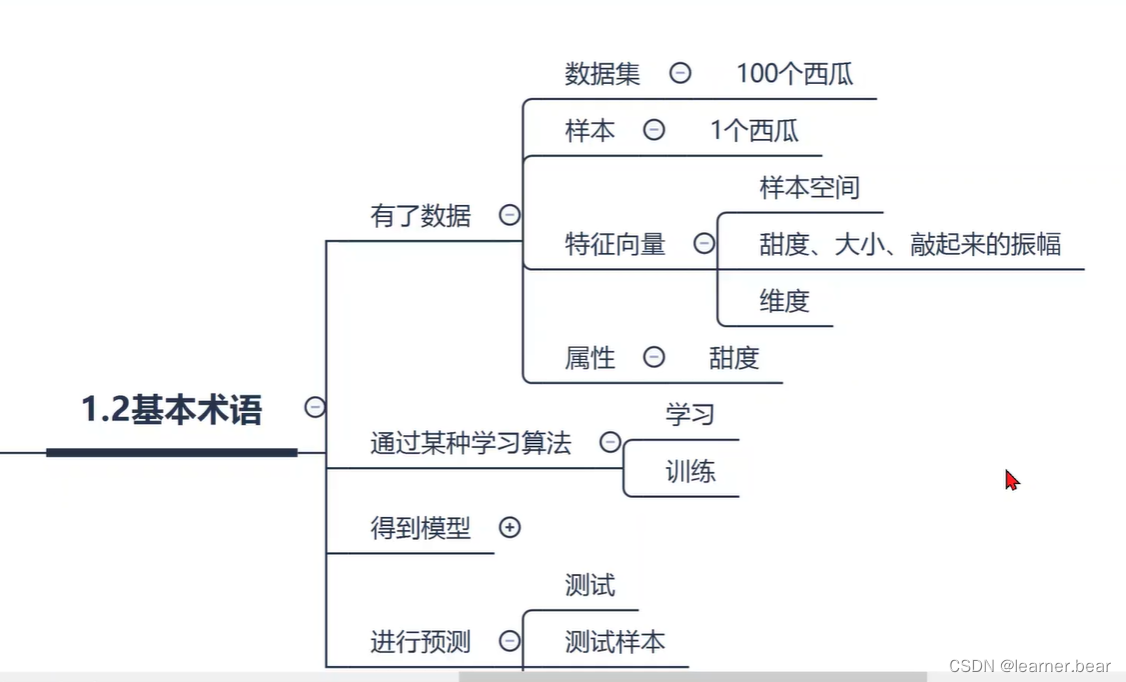
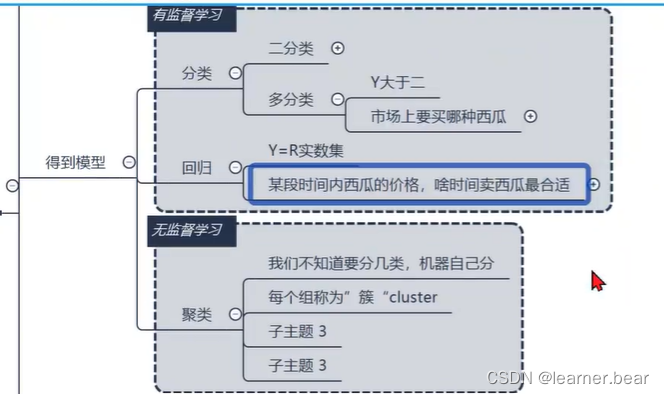
1.预测“离散值”,如“好瓜”,“坏瓜”的学习任务叫做“分类”,预测连续值,如西瓜的熟度,叫做“回归”。
2.根据训练数据是否拥有标记信息,学习任务可分如“监督学习”(有明确的答案)和“无监督学习”(无明确的一个答案)。分类(分为二分类和多分类),回归(对应的正确答案不是明确的,而是一个数集)是前者的代表,聚类(机器自己分类)是后者的代表。
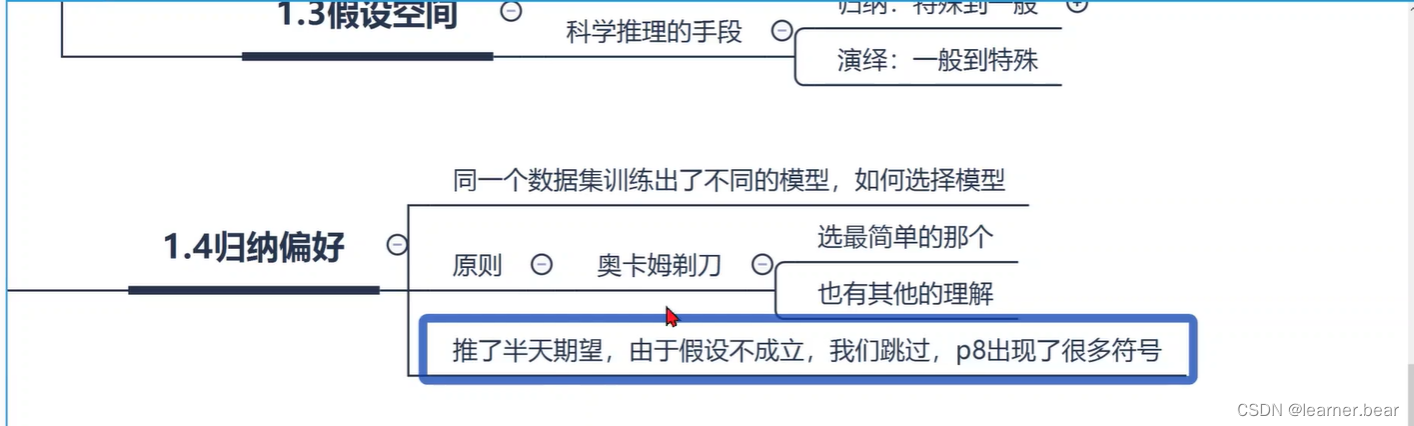
3.NFL定理:我们脱离具体问题,空泛谈论什么“什么学习算法更好”毫无意义,必须要具体问题具体来看。
4.归纳偏好中的奥卡姆剃刀:就是选择更简单,更简洁的做法。

















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









