






问题发现:
搭好k8s+kubesphare 一切正常,测试完对应deploy 后没有问题,就忙其他任务去了,过了领导联系我说 ,他在ks上发现,calico 报黄了,并且ks的 AlertManager pod 也报黄了,并且1/2 反复重启,针对此问题进行排查。
排查 AlertManager 1/2 问题 ,
日志报错:
config-reloader 报错
"post /http://localhostL9093/_/reload/" .dial tcp 127.0.0.1:903: connect:connection refuse"如果你没有配置任何的告警模板,那基本问题不是出现在这个pod里。
搞了网上的很多解决办法,没有搞好,即使重新安装ks ,AlertManager 对应的pod 还是没有正常的2/2
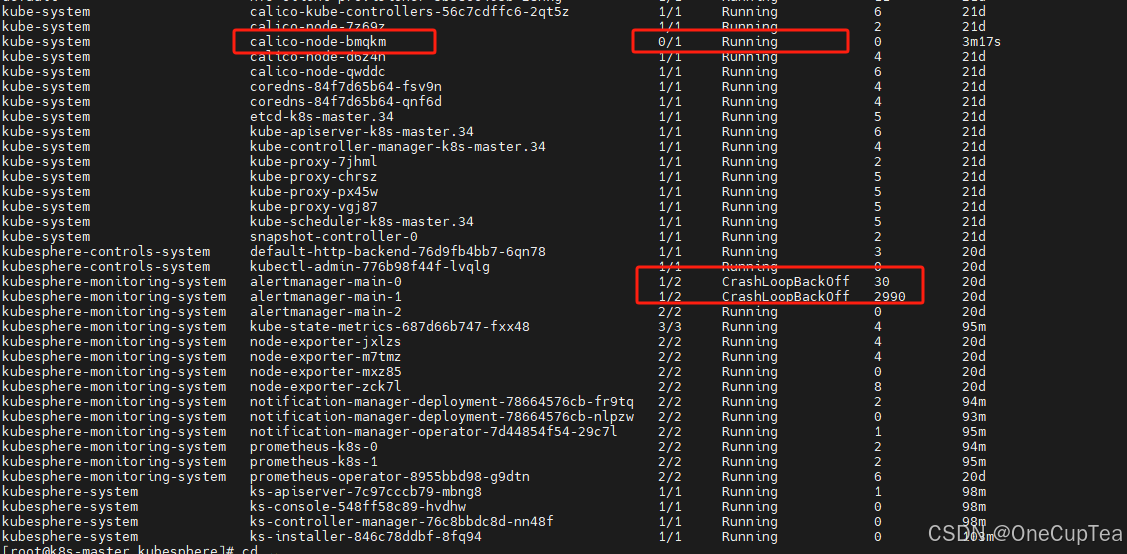
此时 排除ks的问题,应该是其他东西导致的AlertManager无法启动。
此时开始处理 calico 0/1的问题,
Readiness probe failed: calico/node is not ready: BIRD is not ready: BGP not established with xxx.xxx.xxx.xxx, xxx.xxx.xxx
2021-08-17 06:12:41.512 [INFO][209] health.go 156: Number of node(s) with BGP peering establish
查找后问题说是网卡的问题,但是我这台机器上只有一个网卡 ens33 ,然后按照网上的教程
修改calico.yml 部署文件,然后重新启动
# Valid IP address on interface eth0, eth1, eth2 etc.
- name: IP_AUTODETECTION_METHOD
value: "interface=eth.*"
发现没有好使,这个时候问题就已经显现出了,有的服务器的是eth 的 有的是ens的,这个时候 需要根据你的网卡来进行配置,不然还是会用默认的去找网卡。
# Valid IP address on interface eth0, eth1, eth2 etc.
- name: IP_AUTODETECTION_METHOD
value: "interface=ens.*"
修改后重启,发现calico 没有问题了,反过来发现对应的ks的问题也解决了
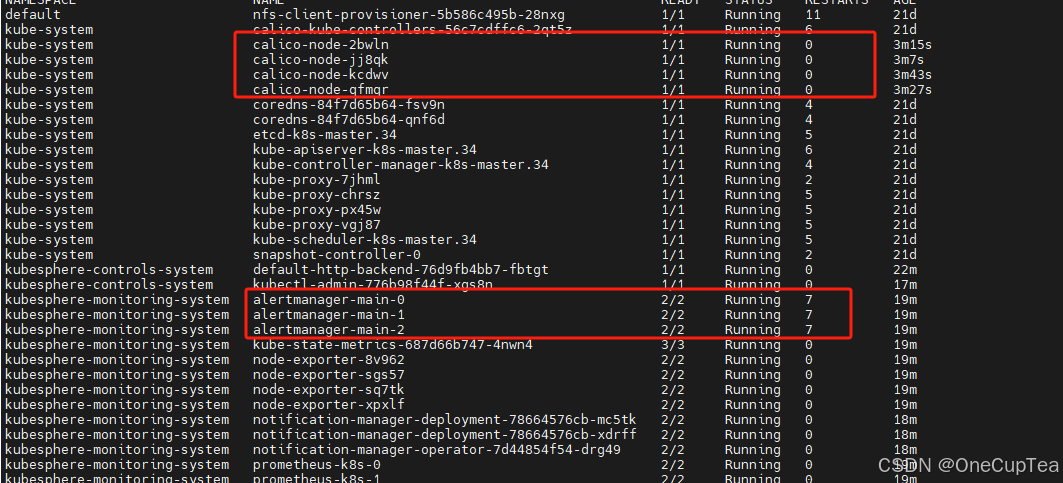
用作记录留坑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









