




动态检索块:根据任务需求灵活调整
在信息检索的世界里,传统的RAG(检索增强生成)堆栈主要针对特定事实的问答,但这只是冰山一角。用户可能会提出各种各样的查询,包括总结、比较和对比等。为了应对这些多样化的需求,我们需要一种能够根据任务动态调整检索策略的方法。本文将介绍如何使用LlamaIndex的核心抽象,如路由模块和数据代理模块,来实现任务特定的检索。
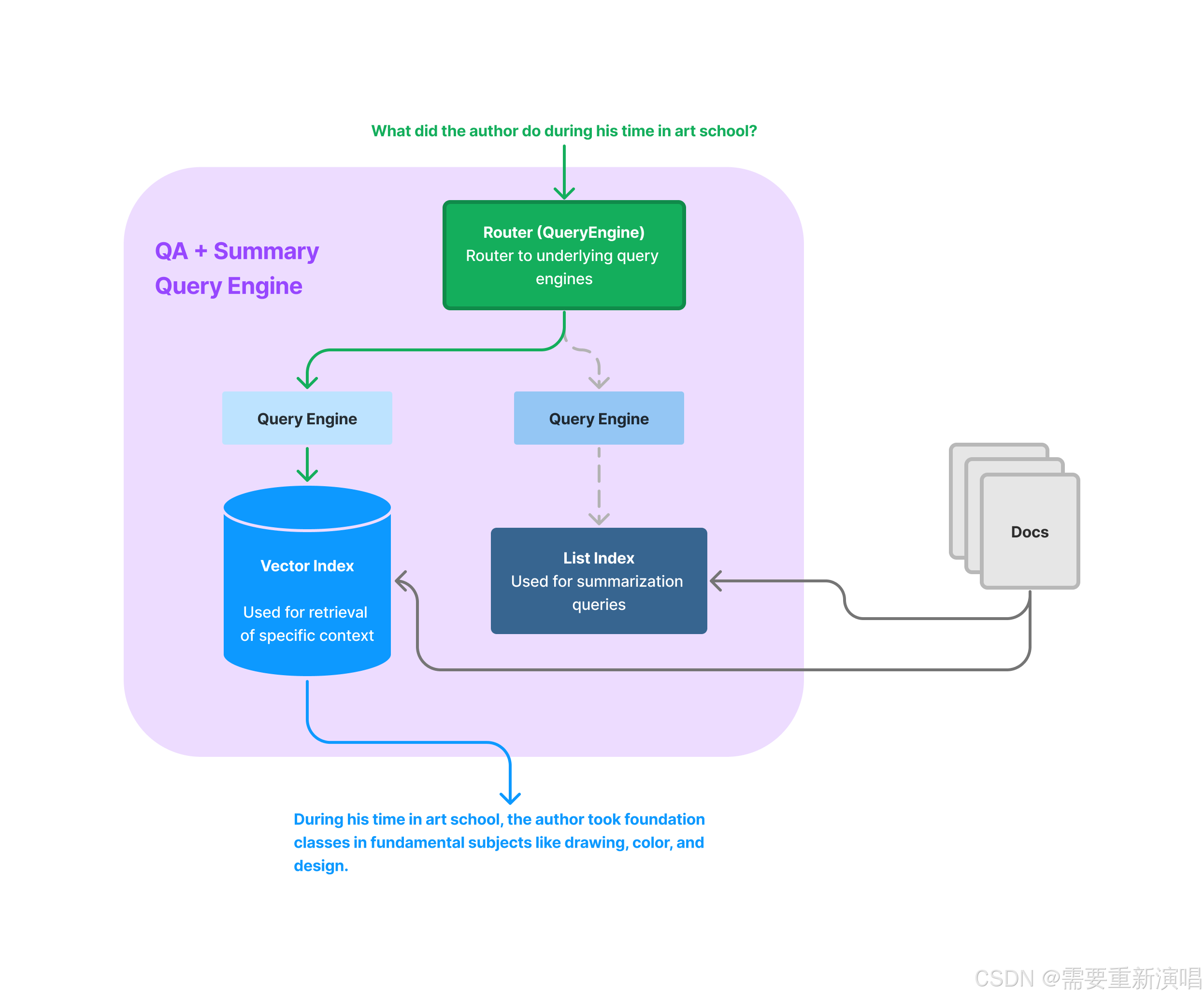
动机
RAG不仅仅是关于特定事实的问答,它还可以处理各种类型的查询。例如:
- 特定事实的问答:“告诉我2023年这家公司的D&I倡议”或“叙述者在Google期间做了什么”。
- 总结:“能给我一个这份文档的高层次概述吗?”
- 比较和对比:“能比较/对比X和Y吗?”
这些用例可能需要不同的检索技术。LlamaIndex提供了一些核心抽象,帮助我们实现任务特定的检索。
关键技术
路由模块
路由模块允许我们根据查询的类型动态选择合适的检索策略。例如,对于总结任务,我们可能需要检索整个文档的摘要;而对于特定事实的问答,我们可能需要检索相关的段落。
from llama_index.core import Router
# 定义不同的查询引擎
summary_query_engine = ...
fact_query_engine = ...
# 定义路由规则
router = Router()
router.add_route("summary", summary_query_engine)
router.add_route("fact", fact_query_engine)
# 根据查询类型选择合适的查询引擎
query_type = determine_query_type(query) # 自定义函数,确定查询类型
response = router.route(query_type, query)
数据代理模块
数据代理模块允许我们在检索过程中动态调用外部数据源或服务。例如,我们可以调用结构化数据库来获取特定数据,或者调用外部API来获取实时信息。
from llama_index.core import DataAgent
# 定义数据代理
data_agent = DataAgent()
# 注册外部数据源
data_agent.register_data_source("database", database_query_function)
data_agent.register_data_source("api", api_query_function)
# 动态调用外部数据源
data_source = determine_data_source(query) # 自定义函数,确定数据源
response = data_agent.query(data_source, query)
高级查询引擎模块
高级查询引擎模块提供了更复杂的检索策略,例如联合问答和总结,或者结合结构化和非结构化查询。
from llama_index.core import AdvancedQueryEngine
# 定义高级查询引擎
advanced_query_engine = AdvancedQueryEngine()
# 联合问答和总结
response = advanced_query_engine.query("联合问答和总结", query)
# 结合结构化和非结构化查询
response = advanced_query_engine.query("结合查询", query)
实际应用示例
假设我们有一个文档集合,用户可能会提出各种类型的查询。我们可以使用上述技术来动态调整检索策略。
from llama_index.core import Router, DataAgent, AdvancedQueryEngine
# 定义不同的查询引擎
summary_query_engine = ...
fact_query_engine = ...
# 定义路由规则
router = Router()
router.add_route("summary", summary_query_engine)
router.add_route("fact", fact_query_engine)
# 定义数据代理
data_agent = DataAgent()
data_agent.register_data_source("database", database_query_function)
data_agent.register_data_source("api", api_query_function)
# 定义高级查询引擎
advanced_query_engine = AdvancedQueryEngine()
# 处理用户查询
def handle_query(query):
query_type = determine_query_type(query) # 自定义函数,确定查询类型
if query_type in ["summary", "fact"]:
response = router.route(query_type, query)
else:
data_source = determine_data_source(query) # 自定义函数,确定数据源
response = data_agent.query(data_source, query)
return response
# 示例查询
query = "告诉我2023年这家公司的D&I倡议"
response = handle_query(query)
print(response)
总结
通过使用LlamaIndex的核心抽象,如路由模块、数据代理模块和高级查询引擎模块,我们可以实现任务特定的检索。这使得我们能够根据用户查询的类型动态调整检索策略,从而提供更准确和高效的信息检索服务。
希望这篇博客能为你带来启发和帮助,让我们在编程的世界里,更加高效地驾驭数据和信息!
参考文献:
扩展阅读:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











