




 本文介绍了如何确定爬取代理IP的需求,通过谷歌浏览器检查网络请求找到存储数据的URL,并利用requests库进行数据爬取。内容包括分析页面结构,获取数据URL以及爬取到的代理IP列表。
本文介绍了如何确定爬取代理IP的需求,通过谷歌浏览器检查网络请求找到存储数据的URL,并利用requests库进行数据爬取。内容包括分析页面结构,获取数据URL以及爬取到的代理IP列表。
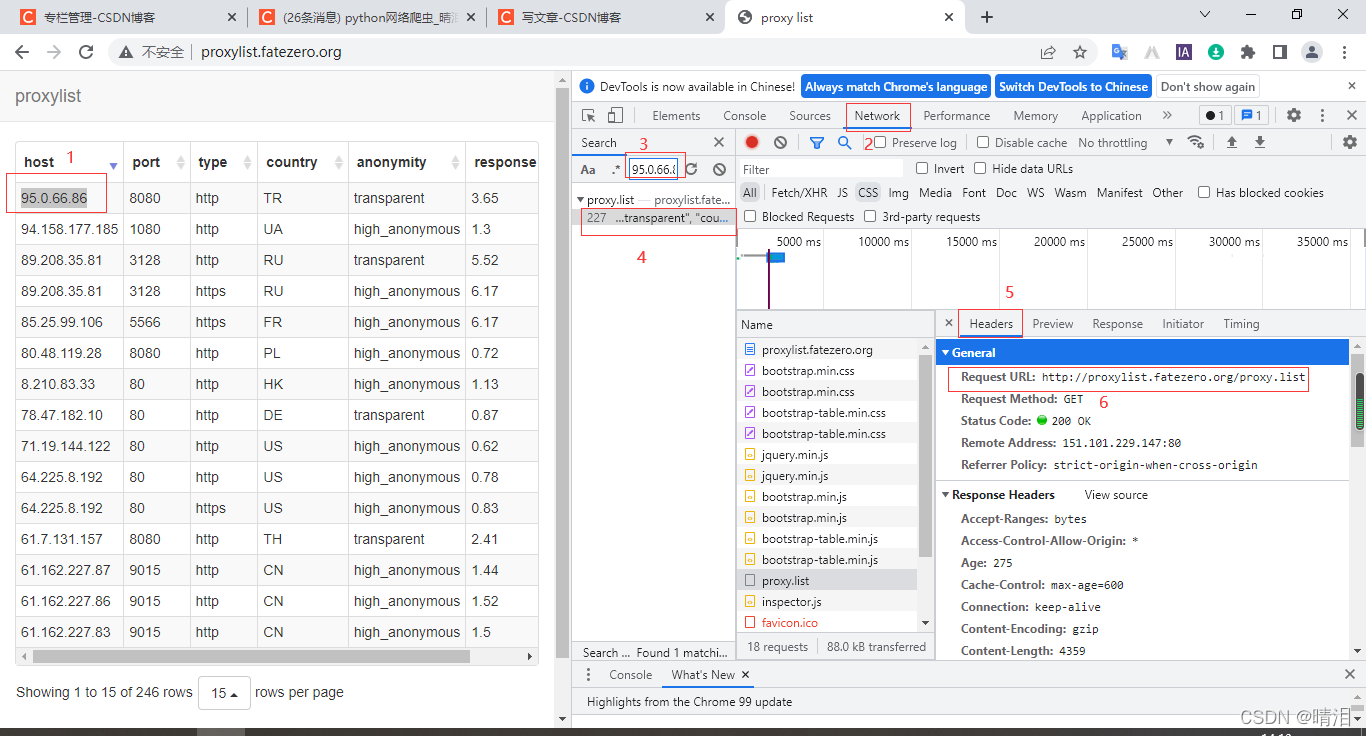
1、确定需求,找到URL
现在很多网站给我们显示的页面是通过两个两个网页来显示的,因此会有两个URL
一个是页面框架,一个是里面的数据,我们可以用谷歌浏览器进入页面
=》右击=》检查=》选择network =》ctrl + f搜索页面中我们需要的数据(95.0.66.86)=》点击资源包 =》选择headers =》Request URL就是存储数据的URL
2、进行数据的爬取
import requests
import os
import time
start = time.time() # 程序开始时间
def check_ip(proxies_list):
# 检测代理的可用性
can_use = []
for proxy in proxies_list:
try:
response = requests.get(url='https://www.baidu.com',proxies=proxy,timeout=2) # 等待时间
if response.status_code == 200:
can_use.append(proxy)
print('当前代理:%s,---检测通过---' % proxy)
except:
print('当前代理:%s响应超时,不合格'%proxy)
return can_use
proxy_list = [] # 接收爬取到的代理ip
# 判断文件是否存在
if not os.path.exists('D:/studySpider/proxys'):
# 创建文件
os.mkdir('D:/studySpider/proxys')
url = 'http://proxylist.fatezero.org/proxy.list' # 准备好url
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'} # 准备好请求头
response = requests.get(url=url,headers=headers).text # 请求
li1 = response.split('\n')
count = 0
for d in li1[1:-1]:
count += 1
dict1 = eval(d) # 字符串转字典
host = str(dict1['host']) # 获取host
port = str(dict1['port']) # 获取port
type = dict1['type'] # 获取type
proxy_dict = {type: host + ':' + port} # 拼接为代理IP
proxy_list.append(proxy_dict) # 追加到列表proxy_list
print('爬取ip代理 {0} 成功,第 {1} 个'.format(proxy_dict,count))
print(proxy_list) # 输出代理列表
can_use = check_ip(proxy_list) # 调用ip检测可用性
with open('D:/studySpider/prox 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









