







 本文介绍了数据结构中的基础元素——记录、数组和链表。记录用于组织多个相关属性,数组提供随机访问但插入和删除效率低,而链表在中间插入和删除高效但查找较慢。数组适用于大量查找操作,链表适合频繁的插入和删除。文中详细阐述了数组和链表的操作,包括查找、插入、删除、遍历等,并对比了它们的内存分配和应用场景。
本文介绍了数据结构中的基础元素——记录、数组和链表。记录用于组织多个相关属性,数组提供随机访问但插入和删除效率低,而链表在中间插入和删除高效但查找较慢。数组适用于大量查找操作,链表适合频繁的插入和删除。文中详细阐述了数组和链表的操作,包括查找、插入、删除、遍历等,并对比了它们的内存分配和应用场景。
目录
数据结构代表了有特殊关系的数据的集合,而这些集合能够单独或作为一个整体访问。即是可以把有关系的基础数据类型组合起来取解决负责问题。
记录
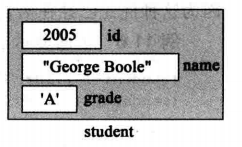
大多数情况下,要描述现实事物需要各种属性,比如要描述学生的成绩,则需要将每一个学生的姓名,学号,等级等属性关联起来。把这些属性当成一个整体,我们使用到了记录。通俗的讲记录就是一个结构体,结构体中有各种数据类型的字段来描述这个事物中我们关注的属性,书中将这些字段称为域。比如下图中student的记录,包含了三个域。
数组
数组是元素的顺序集合,可以存储大量相似的数据,通常这些元素具有相同的数据类型,在这种情形下,数组是一段连续的内存空间,数组中的元素依次排列其中。可以通过从数组开始位置计数的索引来访问每个位置上的元素,比较多的编程语言索引号都是从0开始的。这样可以使用循环很便捷地访问数组中的每个元素。
存储配置
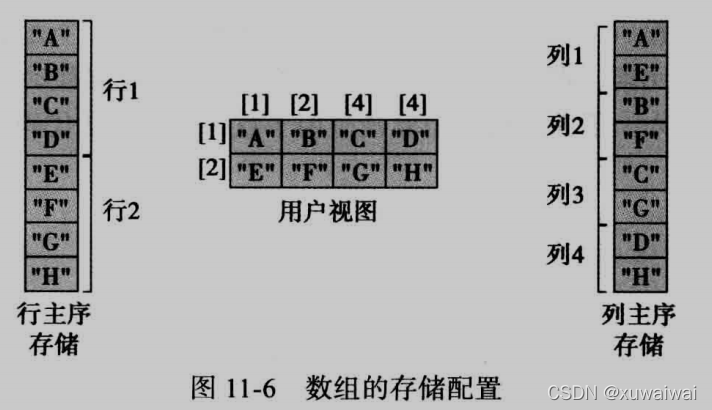
一维数组的索引直接定义了元素在实际存储上的相对位置。但是多维数组有多个维度,而内存是线性的,大多数计算机使用行主序式存储多维数据,即是数组的一个整行存储在下一行之前,所以对于多维数据是将每个元素索引看成一维(特殊处理)的方式顺序存储在内存中。
数组操作
查找、插入、删除、检索、遍历的操作
查找
当知道元素的值时,根据这个值去查找元素所在的位置。对于数组是连续内存空间,可以随机存取元素,对于有序数组可以使用二分法查找,否则只能使用顺序查找。
插入
插入一个元素时,首先要确定插入到数组中的哪个位置上。有时是指定位置,比如首或尾部;有时需要根据元素大小确定位置,比如有序数组中插入元素并确保有序,这是就需要使用到上边的查找。
尾部插入
最简单,直接在把新元素赋值到最后一个元素中。
开始或中间插入
这种情况下需要把插入位置及其之后的元素统一往后移动一个位置(移位时从尾部开始往后移动,以防止元素值的丢失),这样就把插入位置空置出来以容纳新元素。
元素的删除
和插入类似,除了在尾部删除元素不需要移动其他元素位置之外,在其他位置删除元素时都需要把删除位置之后的所有元素往前移动一个位置(删除位置之后的第一个元素开始往前移,以防止元素值的丢失)。
检索元素
数组是随机存取结构,可以使用索引和简便的获取到改位置上的元素。
遍历
因为可以随机检索元素,可以使用不断增长的索引值来获取到每个元素。
数组应用
由上面数组的操作可知,数组随机读取很高效,但是在中间插入和删除元素则较为低效,所以当需要进行的插入和删除操作数据较少,而需要大量的查找和检索操作时,数组是合适的结构。
链表
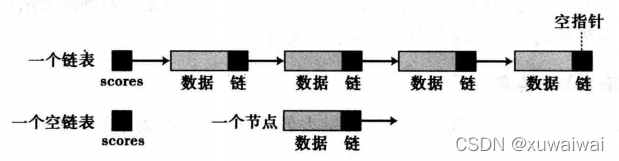
链表中每一个元素中处理有自己存储的数据外还有存有下一个元素的地址,即每个元素包含数据和指针形成的链。链表中的节点习惯上称为节点,下图为一个链表中各节点的关系。
链表操作
查找
链表是通过各节点指针关联的,只能是顺序查找。要查找到某一个元素,则需要先找到前一个节点,以此类推,则需要从头节点开始往后一个节点一个节点的比较以找到我们需要的元素的节点。
插入
需要先确定插入的位置。
空表中插入
如果 list==null,是空表,直接将新数据作为第一个节点插入, list = new;
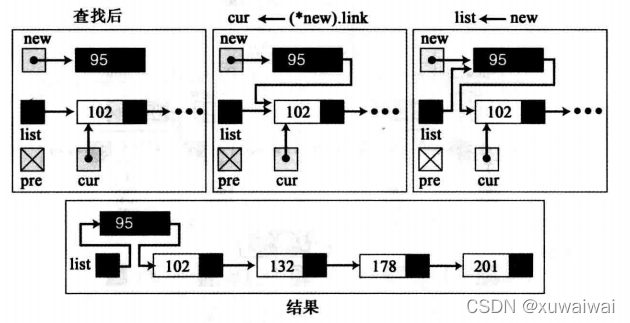
表的开始位置插入
不是空表,cur为第一个节点, 则将新节点插入在cur节点之前,需要将新节点的指针指向cur节点,同时将新节点的地址赋值给list(两个步骤的顺序不能交换), new->link = cur; 和 list = new;下图是在表开始位置插入元素的演示。
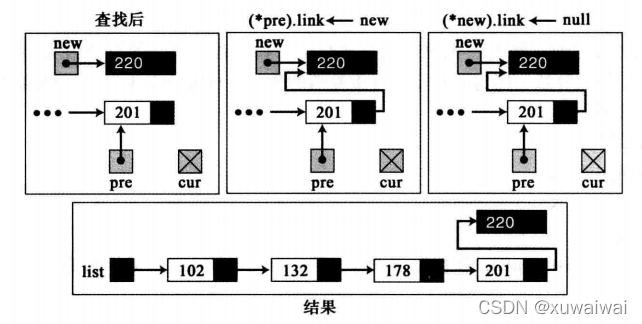
表的末尾位置插入
不是空表,cur为最后一个节点, 则将cur节点的指针指向新节点,同时新节点的指针赋值为null(两个步骤的顺序可以交换) ,cur->link = new; 和 new->link = null;看下图演示
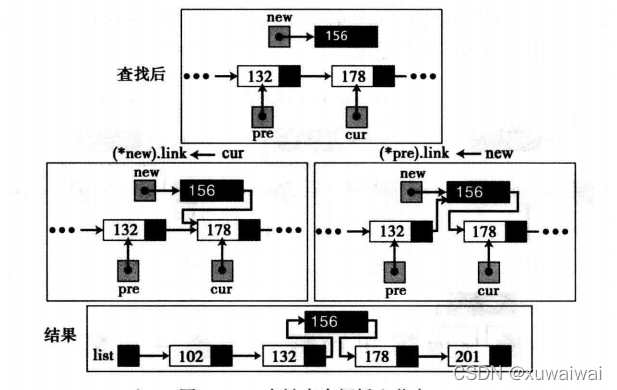
表中间插入
不是空表,cur为插入位置,pre为插入位置的上一个位置, 则 先将新节点的指针指向cur, 再将pre节点的指针指向新节点(步骤不能交换), new->link = cur; 和 pre->link = new;
删除
删除和插入类似,也需要先查找到需要删除节点的位置,然后再将此节点的前节点指向此节点的下一个节点,如有比较还需要将此节点的内存释放掉。
遍历
从头结点顺序遍历直到某一个节点的指针为空。
链表的应用
链表的存储方式决定了在中间插入和删除很是高效,但是查找只能是顺序遍历则比较低效,所以如果需要大量的插入和删除中间元素,那么链表是合适的选择。
以上是三种常见的基础数据结构,可以把记录作为数组或是链表的元素。
下图为数组和链表内存的区别,数据每个元素是内存无间隔的,通过索引可以快速的检索到元素,链表理论上各元素的内存是有间隔的,不连续的,每个节点通过指针关联,这样在链表中中间插入和删除时就不需要移动后面元素。

凡是过往,即为序章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









