






一、一个项目的声明周期:
1、背景调研
2、需求分析(项目中最重要的部分)
3、概要设计(模块之间的交互,对整体架构的设计)
4、详细设计(把模块划分为更小的模块(小至函数或者类))
5、编码开发
6、测试
7、发布
二、这个项目的功能:
1、需求
核心功能:聊天
有若干个用户在同一个聊天室中,任何一个用户发言,所有的在线用户都能看到消息。
用户发送的消息中,不光包含发送的信息,还包含了用户的身份(昵称)。不做用户注册和登录功能,客户每次上线的时候,直接在初始页面中输入自己的昵称即可。
存在好友列表:每个在聊天室中发言过的用户,都会被记录到好友列表中,如果用户下线,再次上线之后,好友列表即清空,好友列表会及时更新,有新用户发言就会自动加入到好友列表中;如果好友下线,自动从好友列表中删除。
2、概要设计:
(1)模块划分:
a、客户端(和用户进行交互(通过命令行界面进行交互))
b、服务器(具有具体业务场景(聊天的)服务器)(接收用户的消息并且转发到所有客户端上)
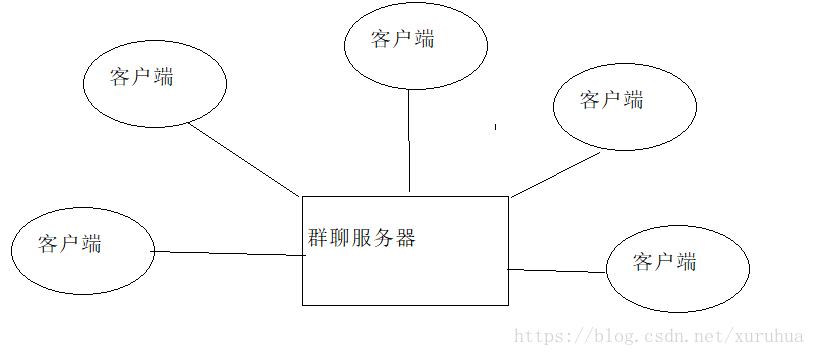
约定客户端和服务器端的交互接口(自定制应用层协议)
(2)自定制协议的步骤:
a、明确交互的信息:
用户发送的消息正文
用户的昵称控制字段:标识当前的数据是正文数据还是控制数据(下线报文是控制数据)
由于这个群聊服务器功能和回显服务器是类似的,所以响应和请求是完全相同的。
b、信息的格式如何组织(序列化和反序列化):
定义一个结构体包含要传递的信息
struct Datta{
std::string name;
std::string msg;//消息正文
std::string cmd;//控制字段(如果cmd=>quit,就标识下线报文)
};序列化方案一:将结构体进行序列化,此法行不通

序列化方案二:显示的指定一些特殊的分隔符作为序列化的方式(可行,但是不够优雅)

序列化方案三、JSON :一种文本文件的格式(数据格式)(用{}将键值对括起来,把键值对通过特定的格式组织在一起:
本质上是表示一个结构化的数据,很方便的进行组织和解析;序列化和反序列化只是json的应用场景之一。
json
{
”名字“:”花木兰“
”技能1“:”踏雪寻梅“
”技能2“:”乘风破浪“
”被动“:”打野“
}
{
"name", "小王",
"msg", "haha",
"cmd", "",
}优点:json可读性更好,通过键值对知道每一个项对应的键值对的含义是什么。

缺点:为了使可读性更好,会增加一些额外的开销,占用空间较大。
我们一般使用第三方的json库帮助我们完成json的构造和解析=>jsoncpp
序列化方案四:序列化的方案库:google protobuf:调用两个接口就可以进行序列化,序列化的格式由库的结构决定。
优点:占用空间小;缺点可读性差【按照二进制的方式进行序列化】
4、详细设计:
服务器模块:
UDP服务器结合生产者、消费者模型
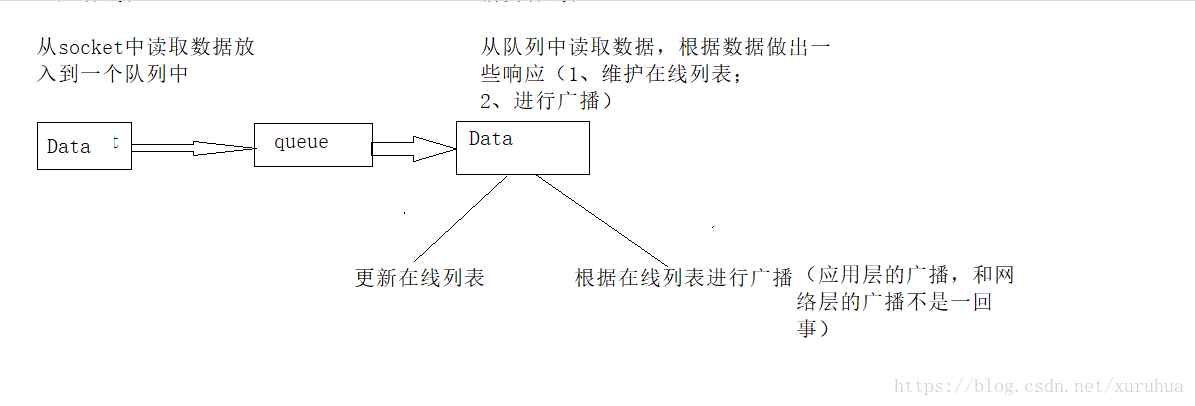
c++中的模板不支持分离、编译模型,声明和函数的定义必须写到函数的头文件中,不能分开来写
安装jsoncpp:
root用户下:yum list | grep jsoncpp安装带devel的包(一般是开发包)
yum install 带devel的包
把标准错误重定向到某一个文件里面:find -name jsoncpp 2>/dev/null:只保留想要看到的错误
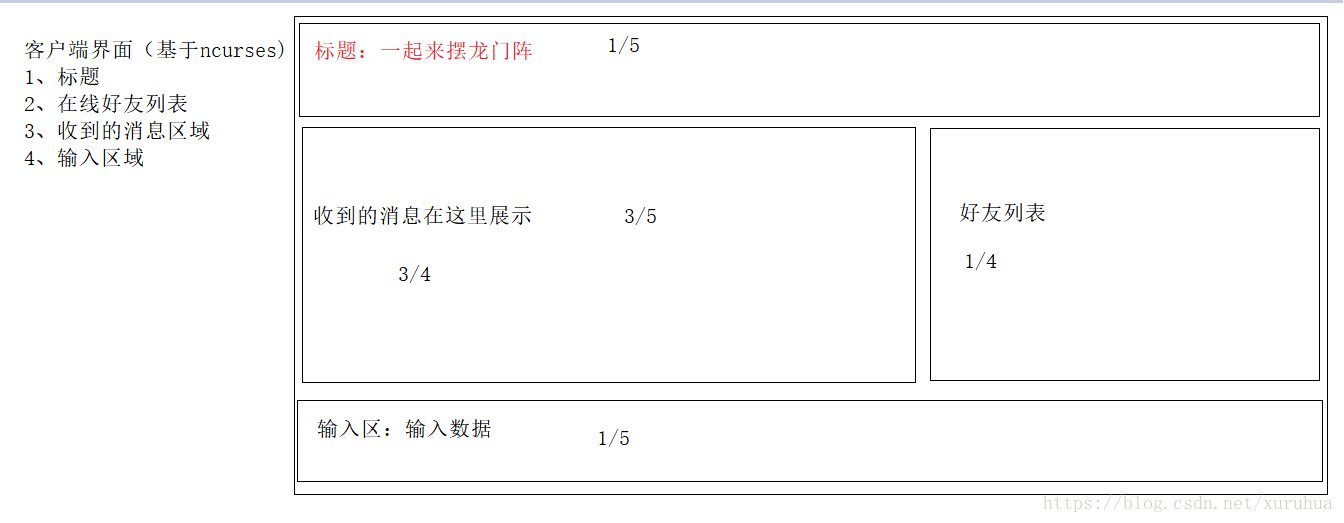
5、界面设计
(1)ncurses命令行下设计界面的库:
A、安装:ncurses库:root用户下:yum list | grep ncurses查看ncurses库对应的包(ncurses-devel.x86_64安装devel的包)
基于库进行开发需要安装-devel库【32位系统只能装i686;64位系统可以装x86_64】
yum install ncurses-devel.x86_64
B、常用api:头文件:# include<ncurses.h>
初始化和销毁:WINDOWS *initscr(void)用内置的结构体返回一个窗口
销毁:int endwin(void)
客户端模块:
1、客户端核心类(负责和服务器交互)
2、客户端界面(基于ncurses)


















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











