



1.数据集准备
在魔搭社区下载开源的中国诗词数据集
git clone https://www.modelscope.cn/datasets/modelscope/chinese-poetry-collection.git
数据预览
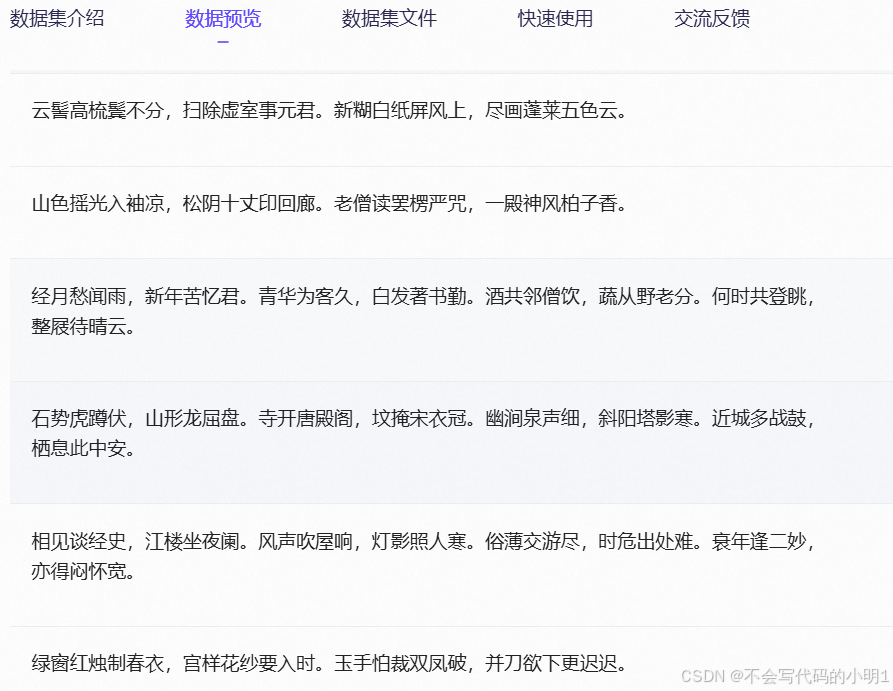
该数据集仅有一列,且为csv格式,目前LLaMA-Factory微调仅支持alpaca格式和sharegpt格式,参考示例数据集中的c4_demo.json格式,因此首先对数据做预处理,代码如下:
import json
import pandas as pd
def csv_to_json(input_csv_path, output_json_path):
# 读取CSV文件
df = pd.read_csv(input_csv_path)
# 将DataFrame转换为包含字典的列表,每个字典只有一个键'text'
json_list = [{'text': row['text1']} for index, row in df.iterrows()]
# 写入JSON文件
with open(output_json_path, 'w', encoding='utf-8') as json_file:
json.dump(json_list, json_file, ensure_ascii=False, indent=4)
# 设置输入CSV路径和输出JSON路径
input_csv_path = '' # 替换为你的CSV文件路径
output_json_path = '' # 替换为你想要保存的JSON文件路径
# 调用函数进行转换
csv_to_json(input_csv_path, output_json_path)
转换后格式如下:

上传到LLaMA-Factory/data文件夹后进行数据注册,打开dataset_info.json,添加内容:

2.训练
启动LLaMA-Factory可视化界面后,选择参数如下:
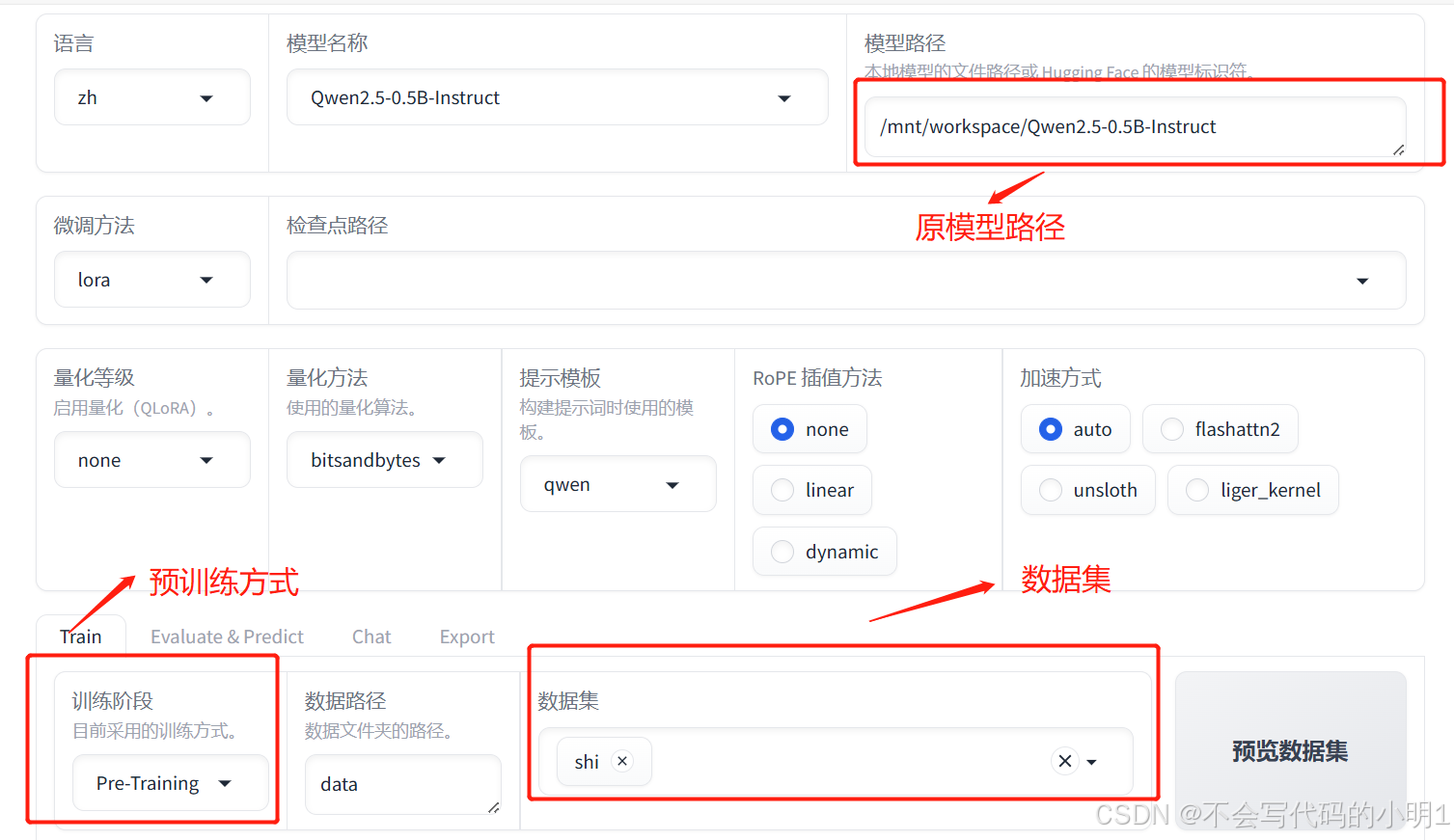
然后开始训练即可
3.推理




















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









