




 超级会员免费看
超级会员免费看
目录
LSTMs: A Step Forward, But Not Far Enough
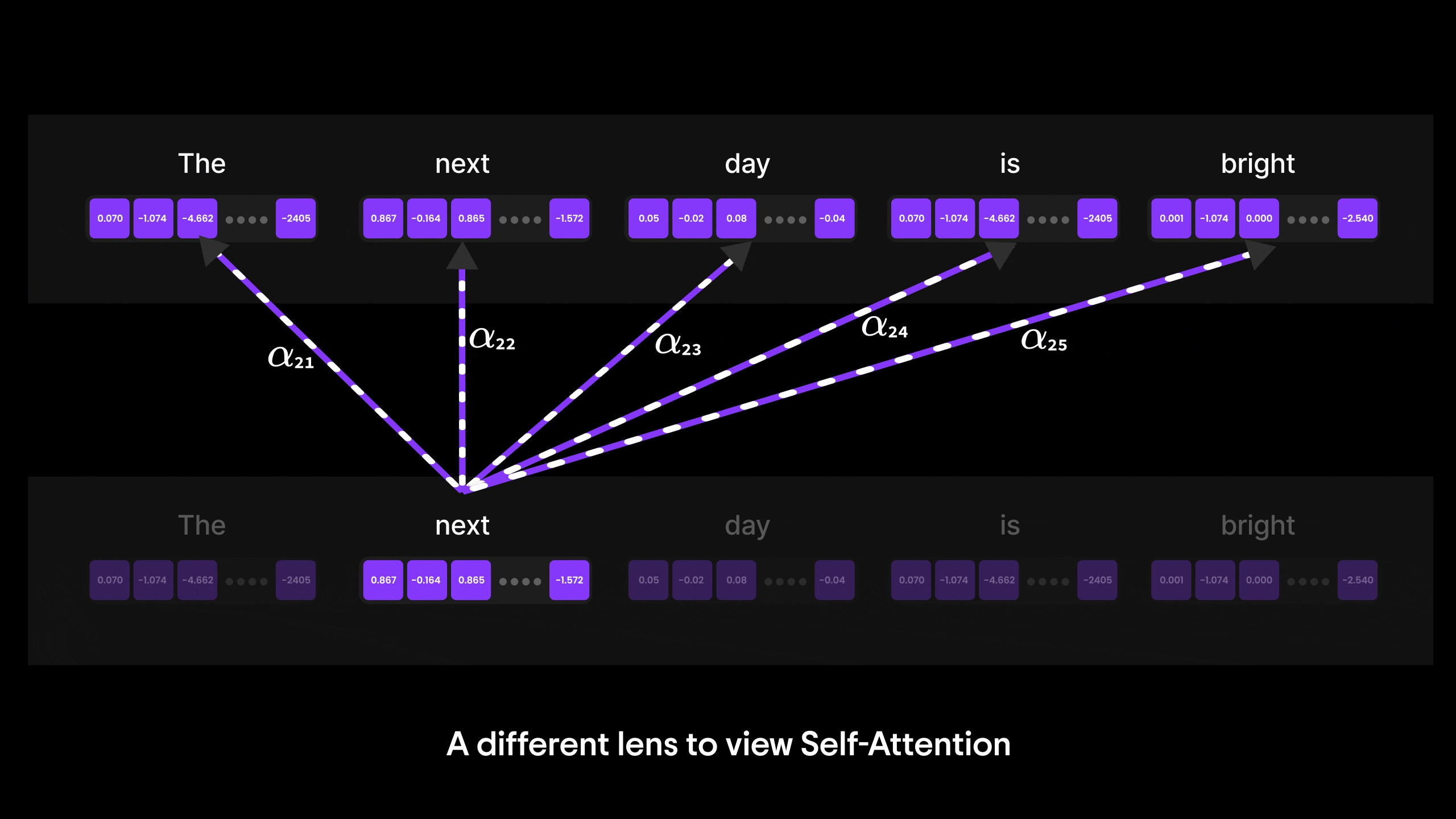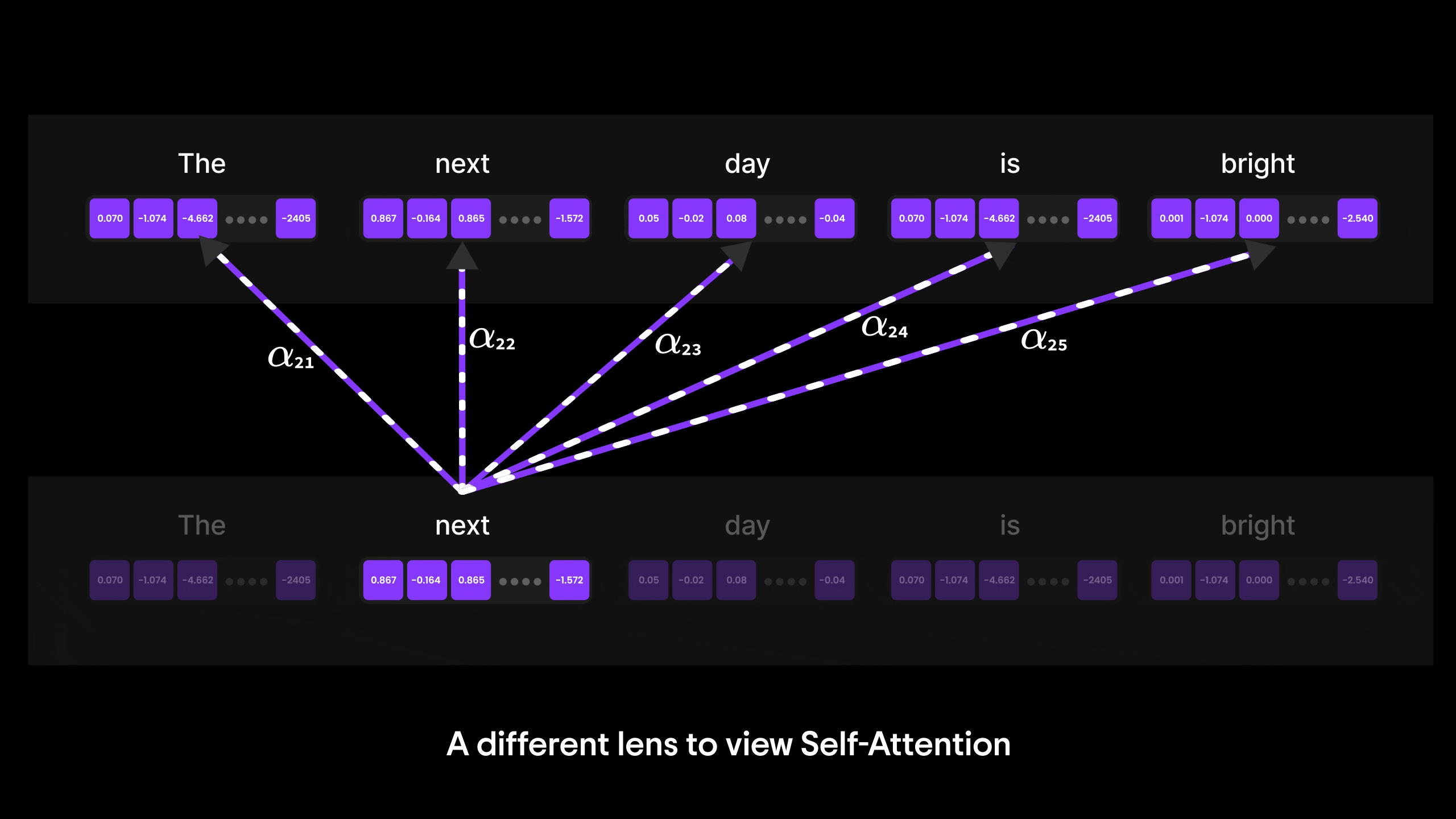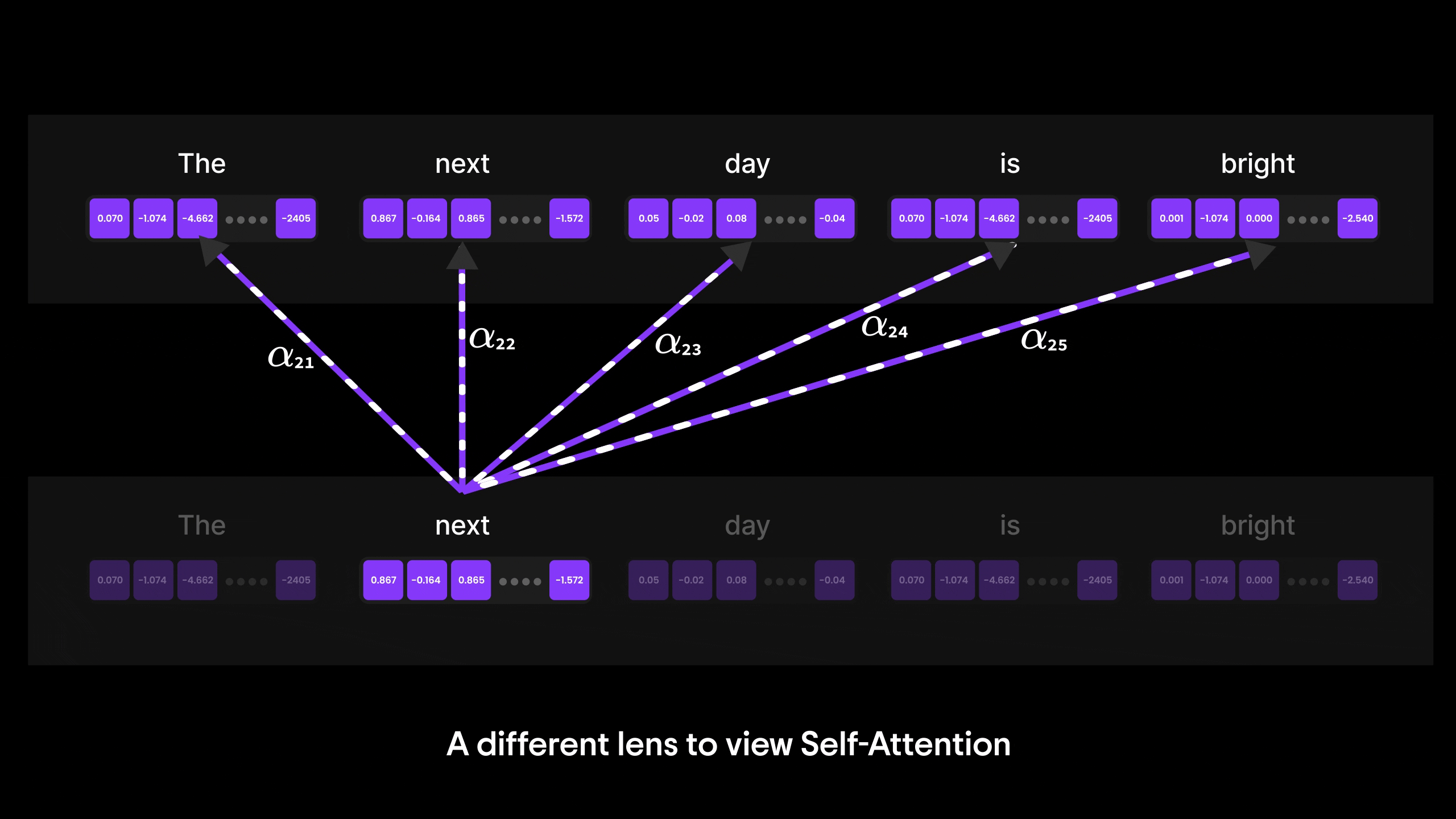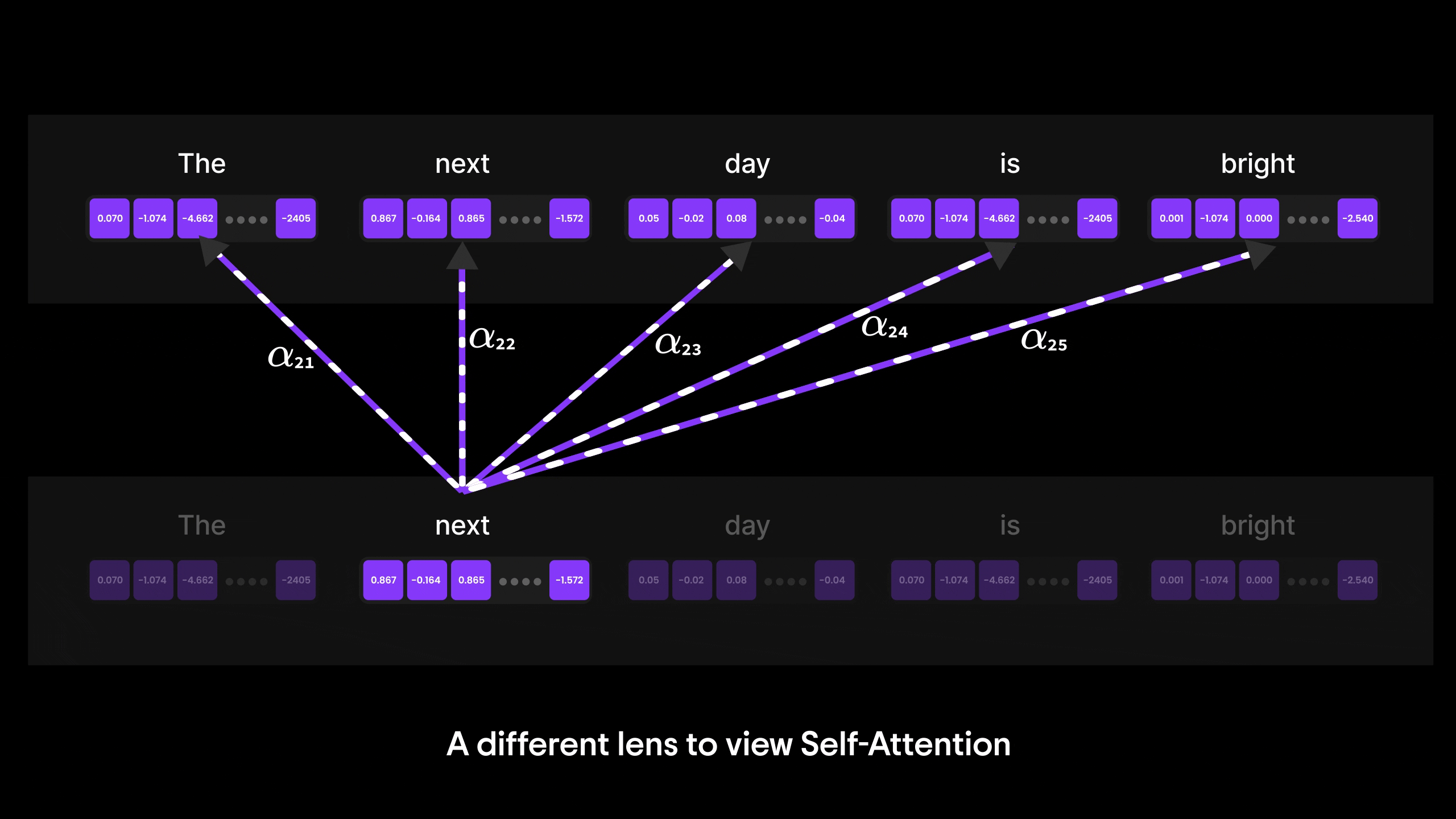
注意力机制的演进:从 Bahdanau 到 Transformer 与 GPT
Introduction
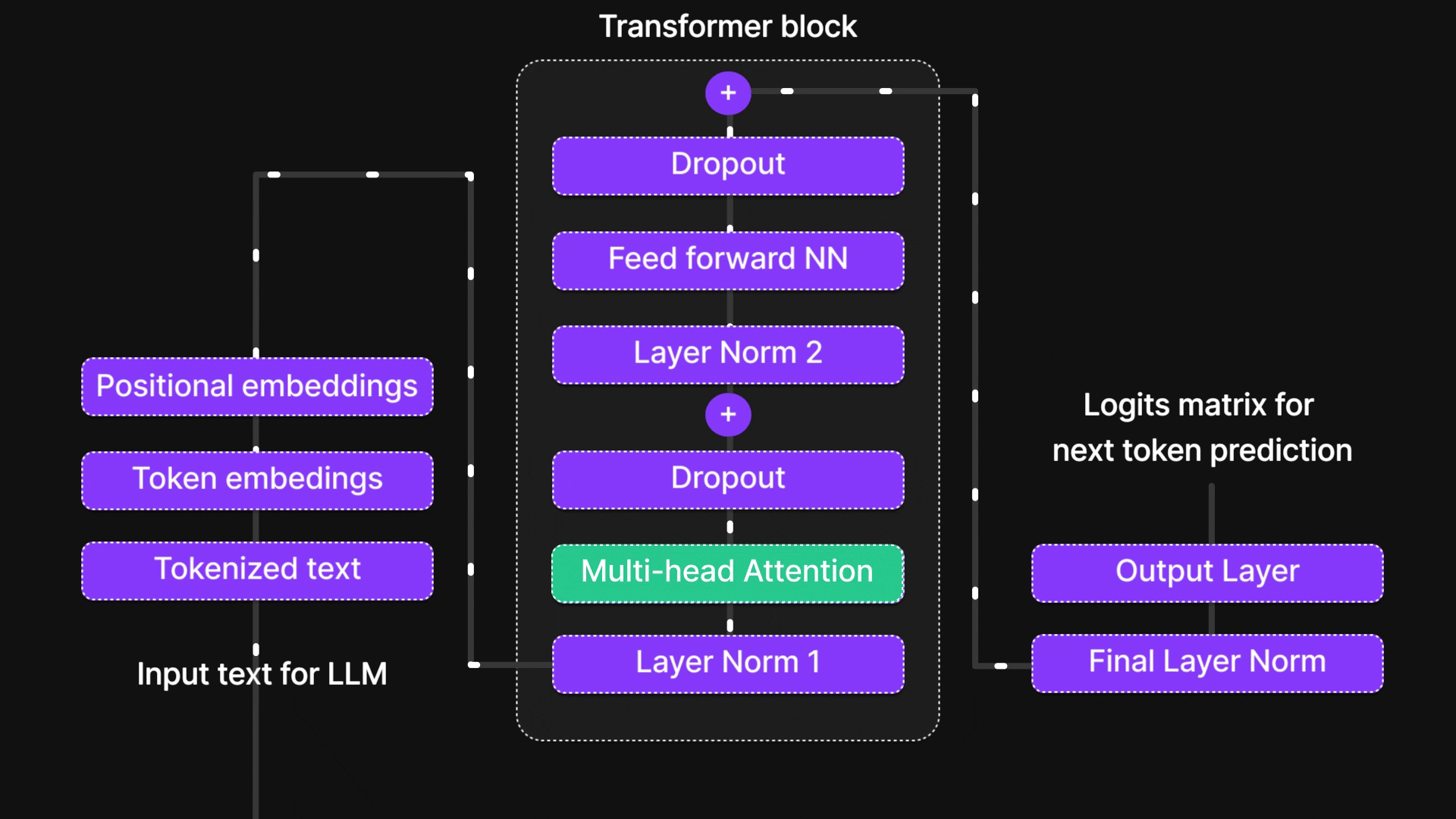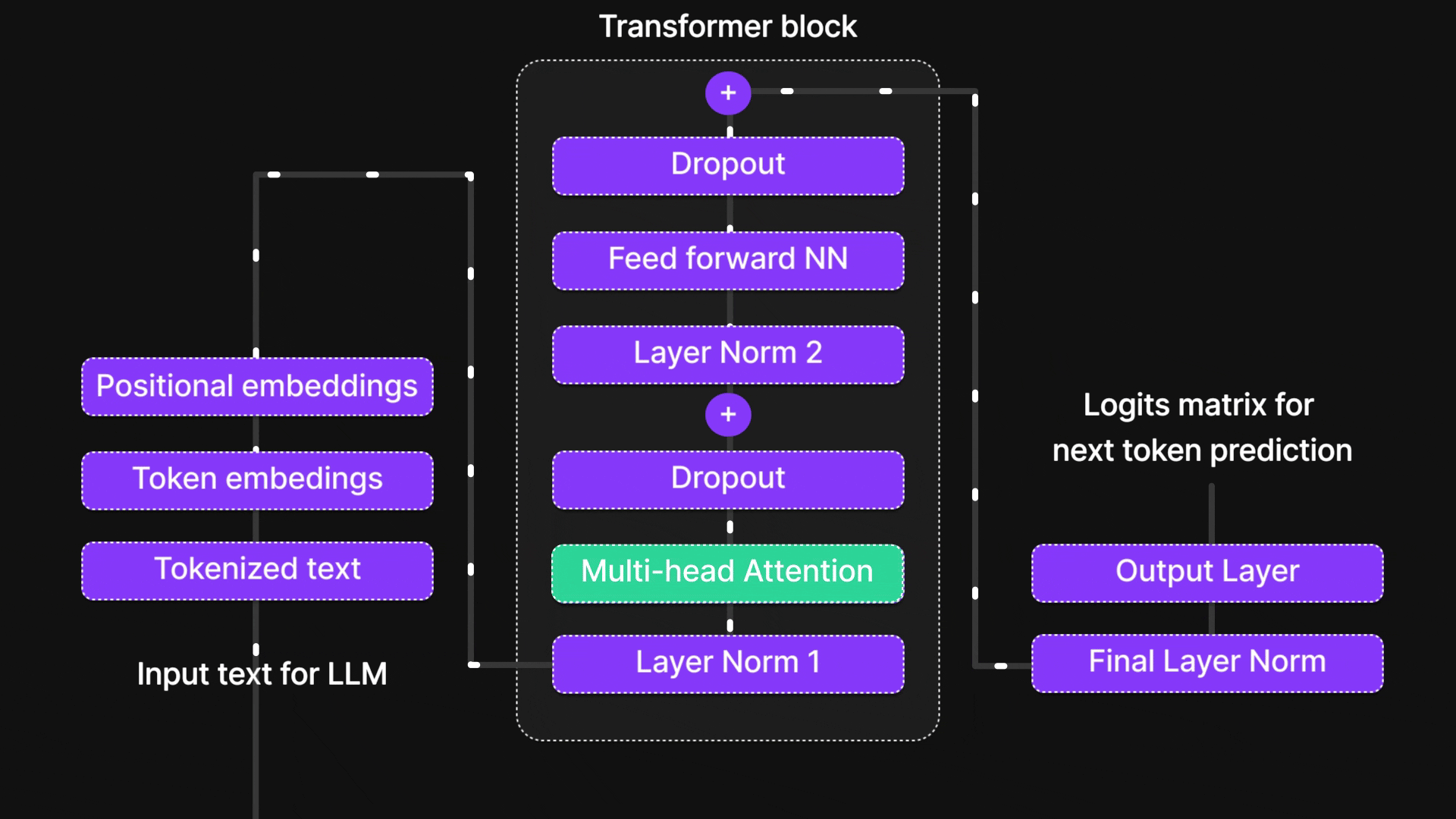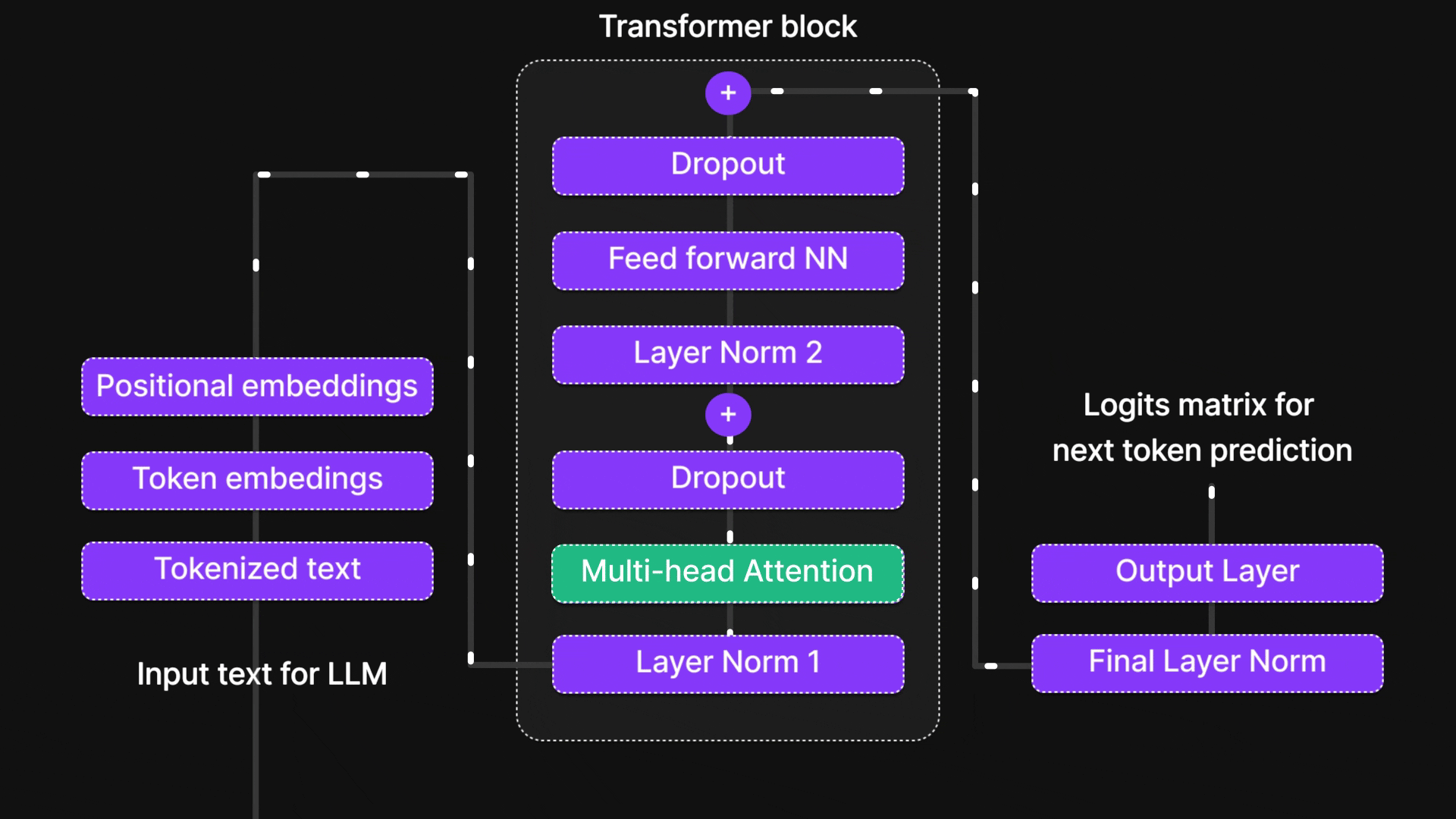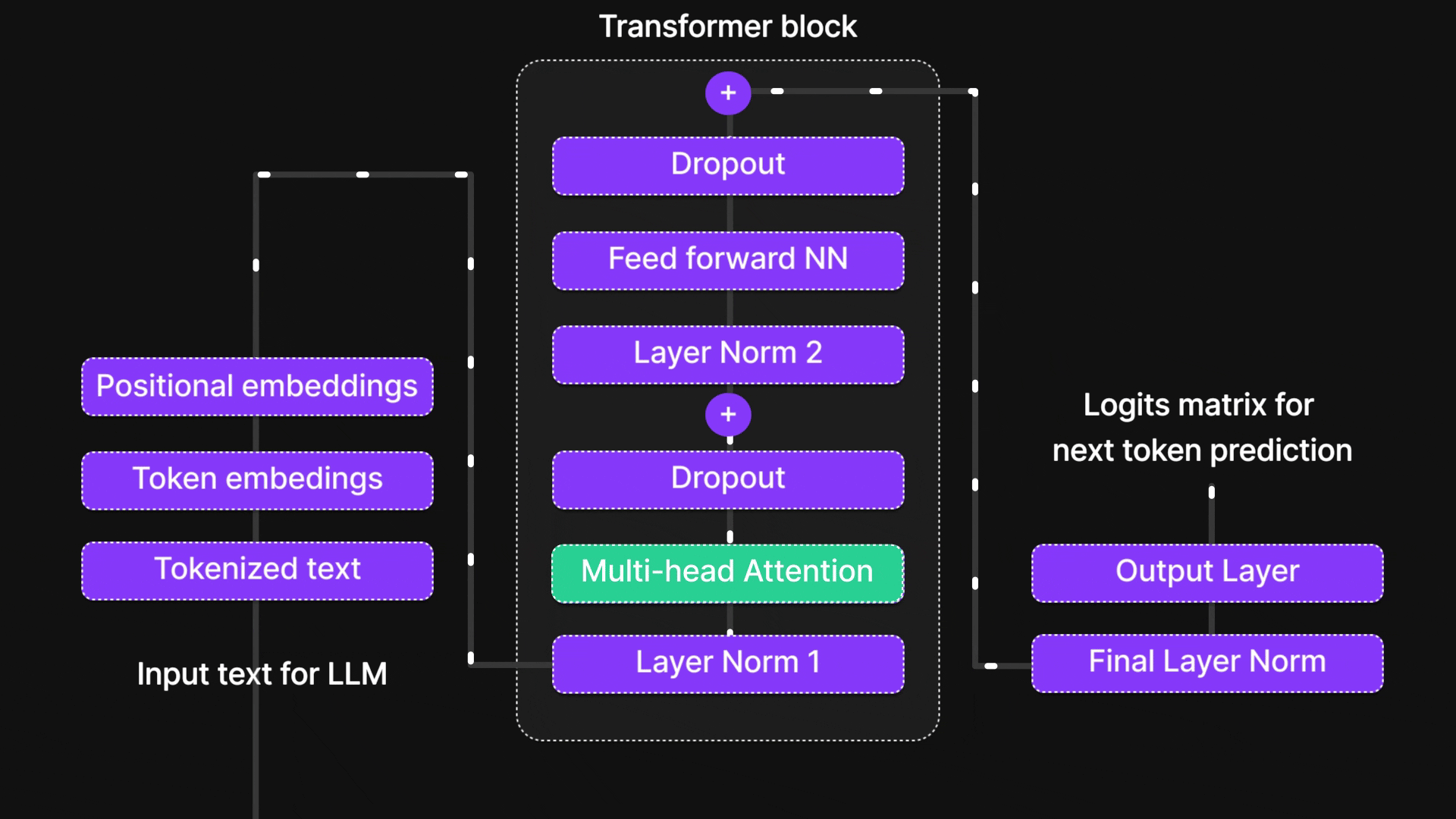
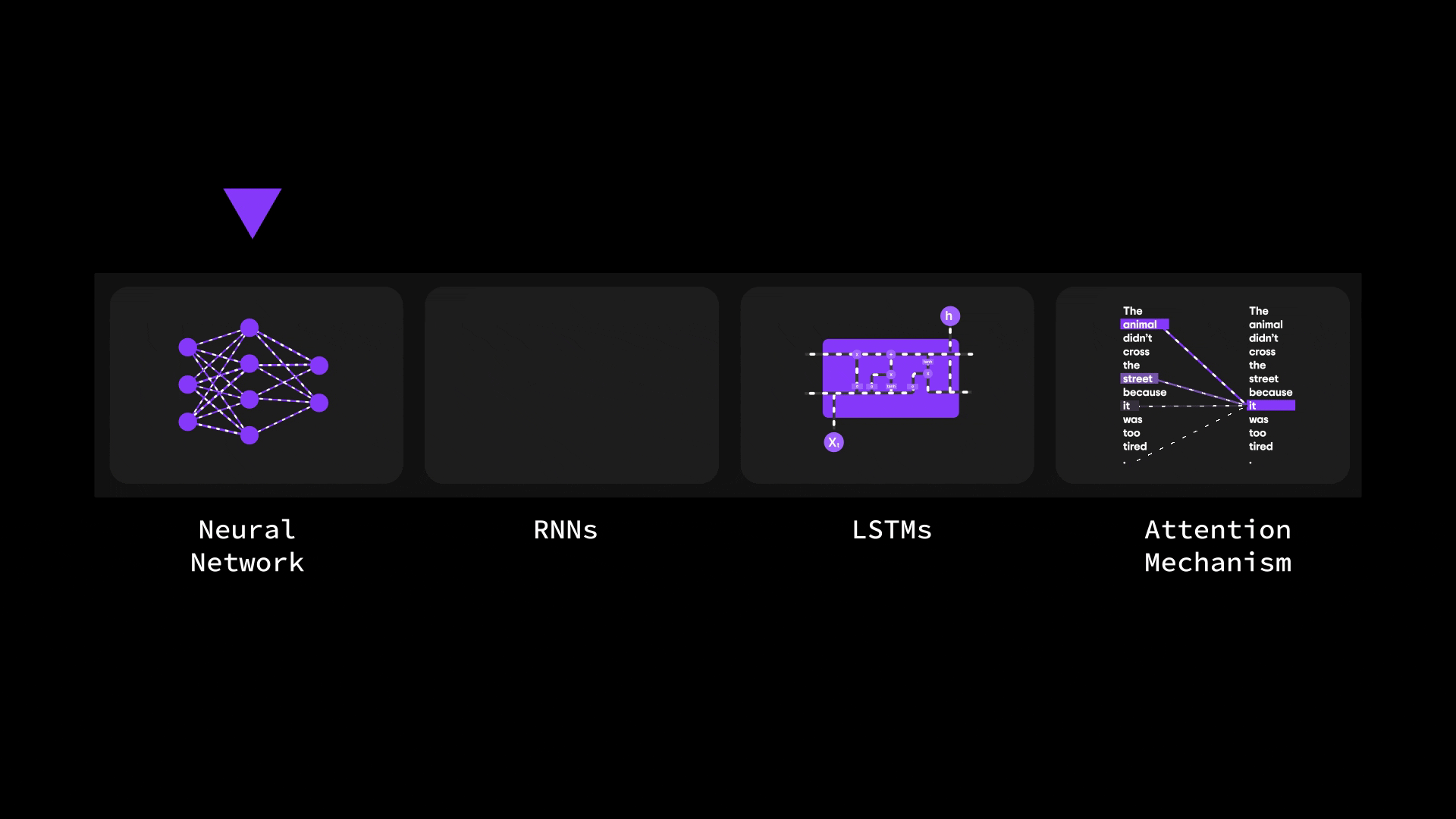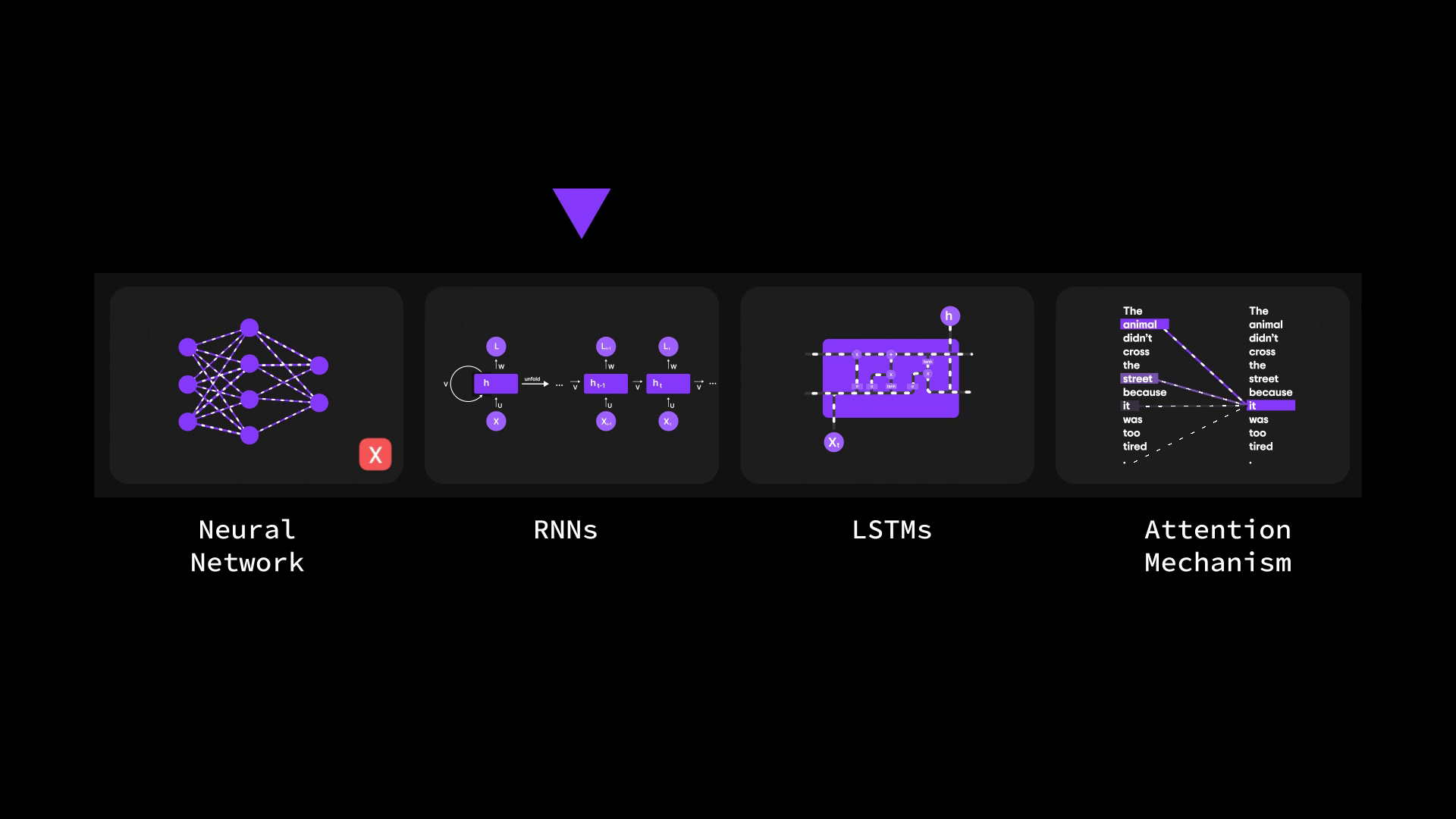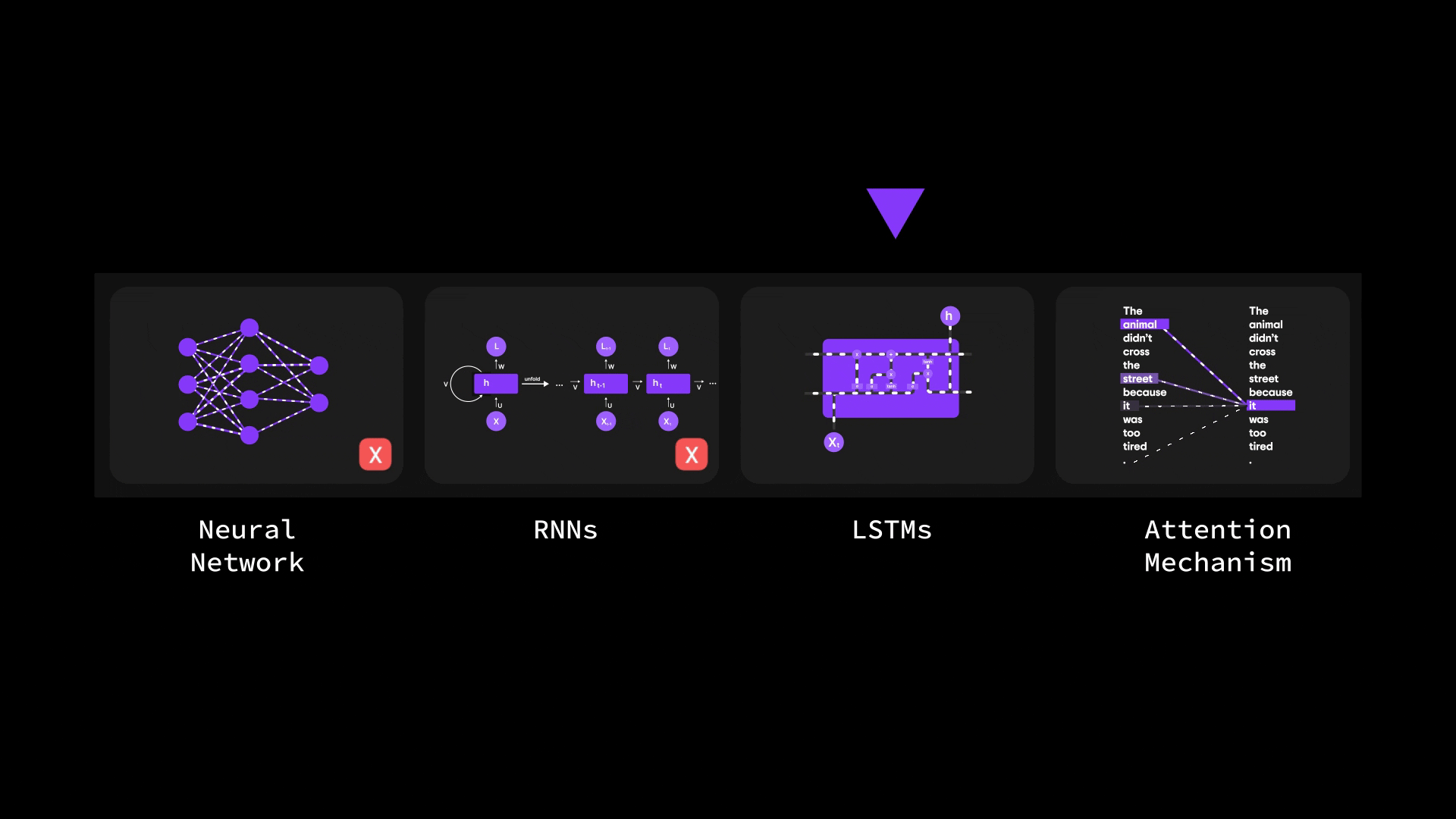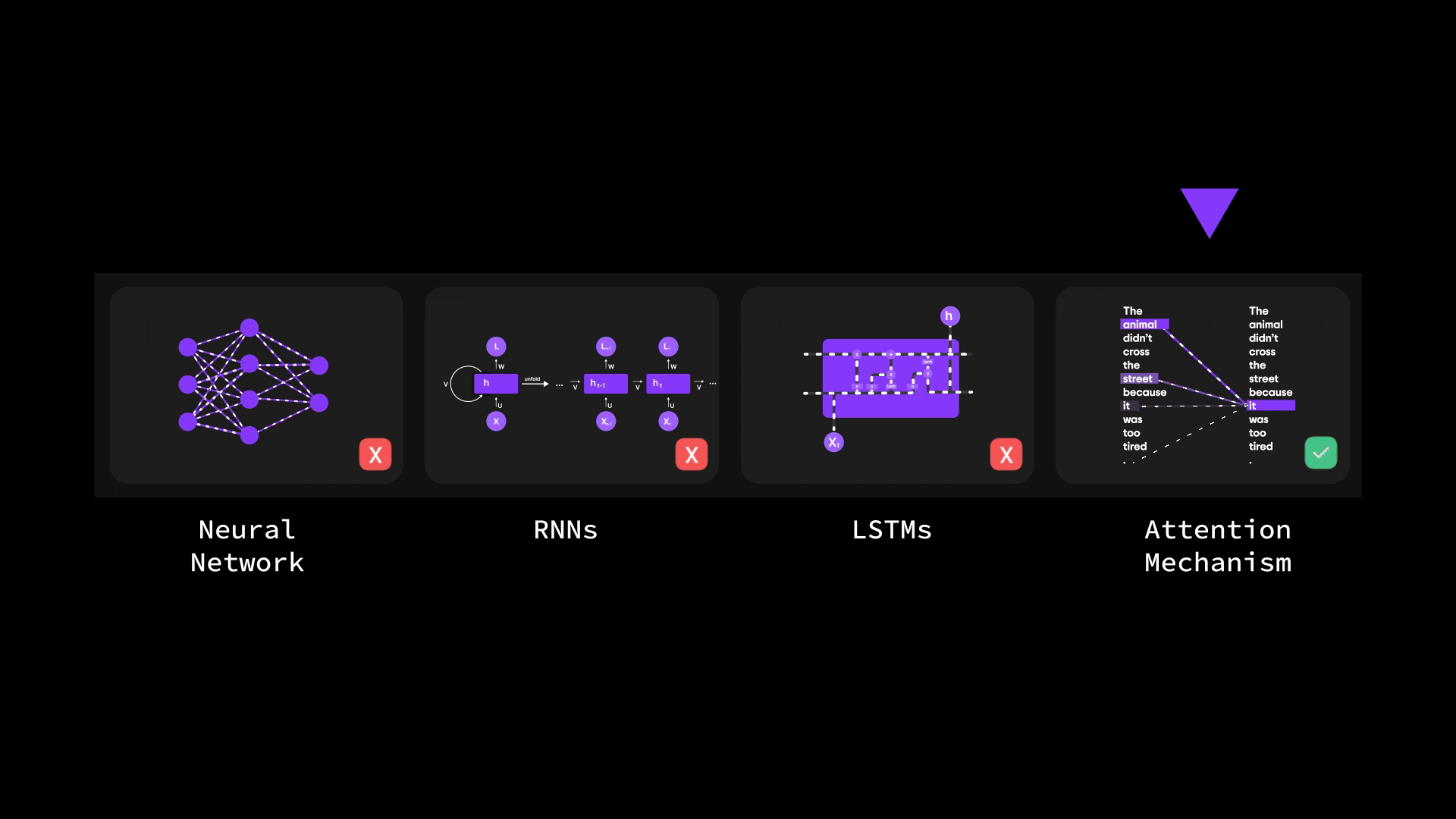
在本篇博客中,我们将层层剖析,探索从基础神经网络到循环神经网络(RNN)、长短期记忆网络(LSTM),最终抵达强大注意力机制的思想演进之路。
您将了解为何传统架构(如 ANN 和 RNN)在处理长序列或复杂输入时会遭遇瓶颈。我们将探讨 LSTM 如何尝试解决上下文信息瓶颈问题(却未能彻底突破),最终揭示 Bahdanau 注意力机制——这种注意力与 RNN 的结合体——如何重塑机器处理序列数据的方式。
阅读结束时,您不仅能理解注意力机制背后的"为什么",更能为下一重大飞跃——自注意力机制与 Transformer 的诞生(当今最强大语言模型的基石)——做好充分准备。
History
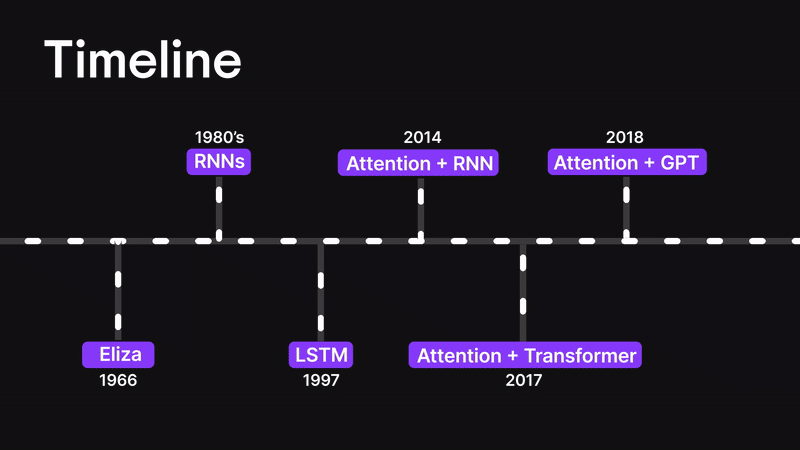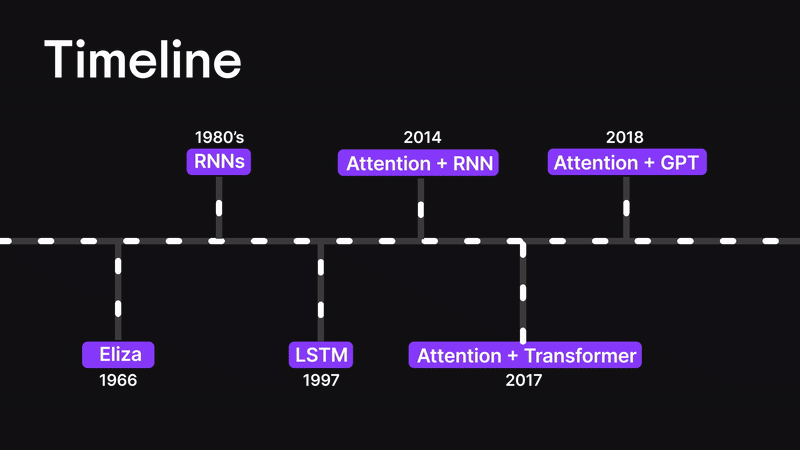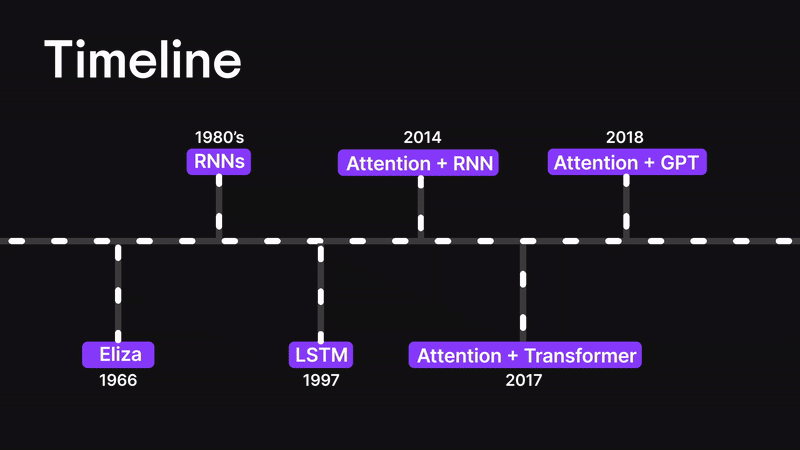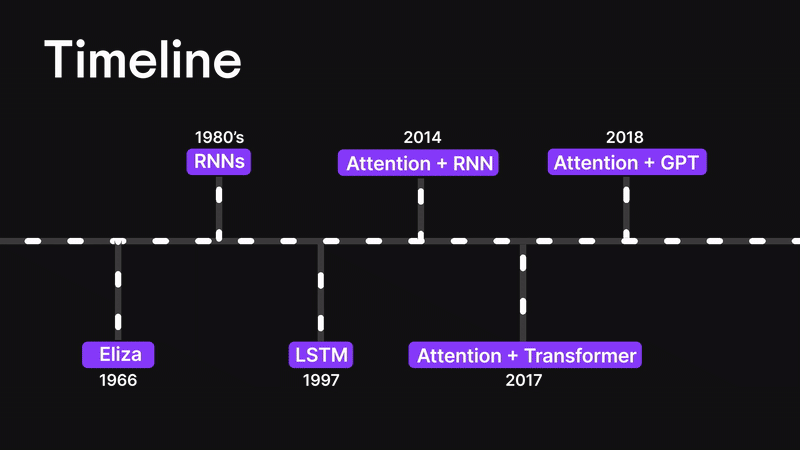
在深入探讨注意力机制之前,让我们先回顾一下背景脉络。

 订阅专栏 解锁全文
订阅专栏 解锁全文





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










