



 该博客介绍了一个使用Python实现的笔趣阁小说搜索及爬取程序,通过输入关键词搜索小说,选择目标小说后,爬取所有章节并使用多线程进行下载。主要涉及requests、lxml库以及队列和线程池的使用,以提高爬取效率。
该博客介绍了一个使用Python实现的笔趣阁小说搜索及爬取程序,通过输入关键词搜索小说,选择目标小说后,爬取所有章节并使用多线程进行下载。主要涉及requests、lxml库以及队列和线程池的使用,以提高爬取效率。
相关网站:http://www.biquge001.com/
"""
笔趣阁搜索小说关键词,选择一本,爬取所有章节
思路:
1.构建搜索网页,进行请求
2.找到所有匹配后的所有小说名和对应url(xpath)/ 有时会直接跳某本小说的章节页,这种情况不考虑了
3.选取小说,请求url
4.爬取每一章(多线程)(xpath)
----------------------------------------------------------------
"""
import requests
from urllib import request
from lxml import etree
from queue import Queue
from concurrent.futures import ThreadPoolExecutor
import time
#小说下载路径
novel_path = "C:\\Users\\kangheng\\Desktop\\MyNovel\\"
#修改UA,添加代理IP
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:44.0) Gecko/20100101 Firefox/44.0", 'Connection': 'close'}
proxies = {"https": "https://36.57.87.202:9999"}
#根据用户输入获取url,获取搜索页response
def Get_home_response():
keyword = input("请输入要爬取的小说关键词:")
#注意这个keyword先gbk编码
params = {"searchkey": keyword.encode("gbk")}
home_url = "http://www.biquge001.com/modules/article/search.php"
try:
response = requests.get(url, params = params)
return response
except Exception as error:
print(error)
return None
#获取响应
def Get_response(url):
try:
response = requests.get(url, headers = headers, proxies = proxies, verify=False, timeout = 5)
return response
except Exception as error:
print(error)
return None
#得到符合搜索条件的所有小说名和链接,以字典形式返回
def Get_all_novel(response):
all_novel = {}
response.encoding = "gbk"
tree = etree.HTML(response.text)
trs = tree.xpath('//*[@id="content"]/div/table/tr')
for tr in trs[1:]:
each_novel_name = tr.xpath('./td[1]/a/text()')[0]
each_novel_url = tr.xpath('./td[1]/a/@href')[0]
all_novel[each_novel_name] = each_novel_url
return all_novel
#用户选择需要爬取的小说,返回选中的小说url
def User_choice(all_novel):
all_novel_list = list(all_novel.keys())
print("搜索结果如下:")
for i in range(1, len(all_novel_list)+1):
print("{0}.{1}".format(i, all_novel_list[i-1]))
choice = int(input("请输入要爬取的小说的编号(如:5):"))
novel_url = all_novel[all_novel_list[choice-1]]
return novel_url
#爬取章节名和链接,以字典形式返回
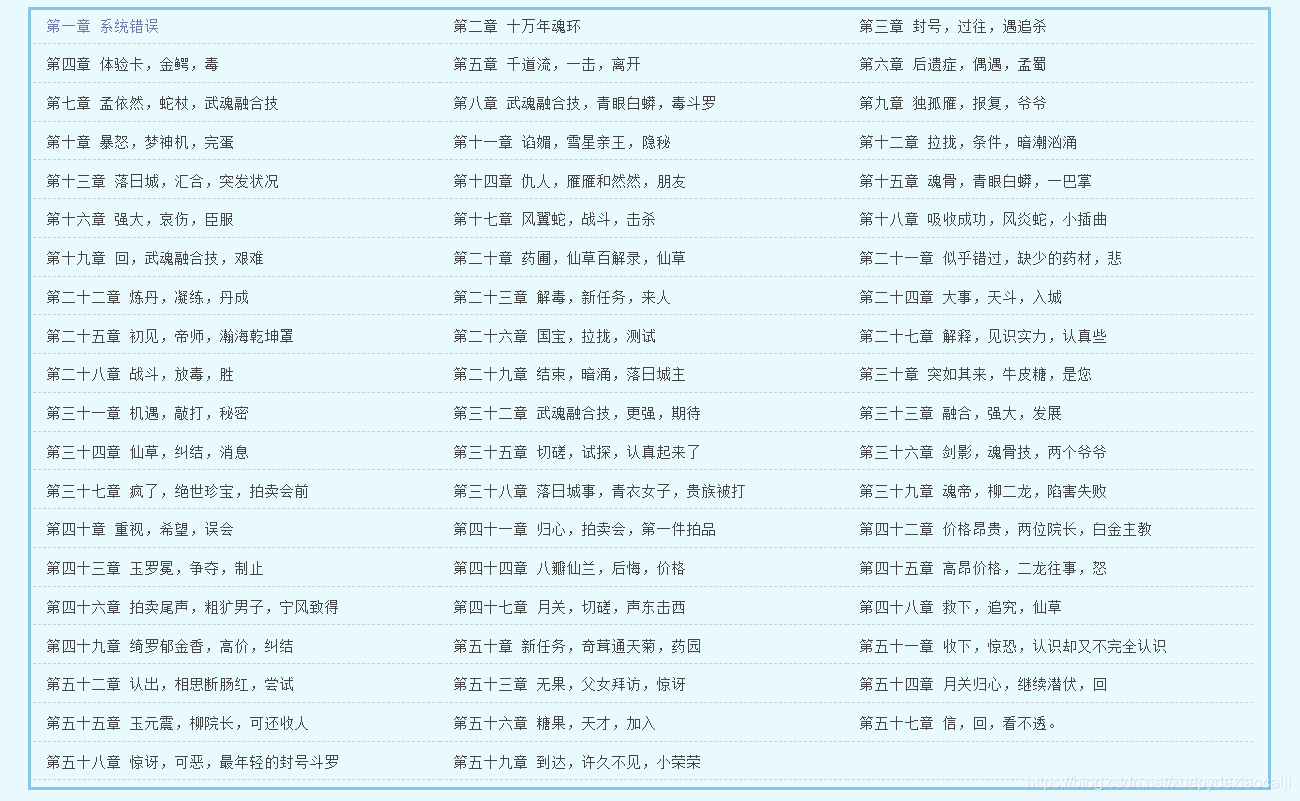
def Get_chapter(response):
all_chapter = {}
response.encoding = "gbk"
tree = etree.HTML(response.text)
dds = tree.xpath('//*[@id="list"]/dl/dd')
#print("章节节点数:", len(dds))
for dd in dds:
try:#消除空节点带来的影响
each_chapter_name = dd.xpath('./a/text()')[0]
each_chapter_url_part = dd.xpath('./a/@href')[0]
each_chapter_url = f"http://www.biquge001.com{each_chapter_url_part}"
all_chapter[each_chapter_name] = each_chapter_url
except:
pass
return all_chapter
#创建队列,进程池处理下载函数
def Get_Queue(chapter):
name_list = list(chapter.keys())
url_list = list(chapter.values())
name_queue = Queue()
url_queue = Queue()
for i in range(len(name_list)):#将每个章节信息依次送入队列
name_queue.put(name_list[i])
url_queue.put(url_list[i])
with ThreadPoolExecutor(30) as t:
for j in range(name_queue.qsize()):
t.submit(lambda p: Download(*p), [name_queue.get(), url_queue.get()])
#下载小说
def Download(name, url):
response = Get_response(url)
response.encoding = "gbk"
tree = etree.HTML(response.text)
content = tree.xpath('//*[@id="content"]/text()')
with open(novel_path+name+".txt", "w+", encoding = "utf-8") as fp:
fp.writelines(content)
def main():
#输入关键词搜索
home_response = Get_home_response()
#得到搜索列表
all_novel = Get_all_novel(home_response)
#选择小说进行爬取
novel_url = User_choice(all_novel)
#获取程序开始爬取的时间戳
start_time = time.time()
#爬取章节链接
all_chapter = Get_chapter(Get_response(novel_url))
#爬取每章内容下载到本地.txt文件
Get_Queue(all_chapter)
#获取程序结束爬取的时间戳
finish_time = time.time()
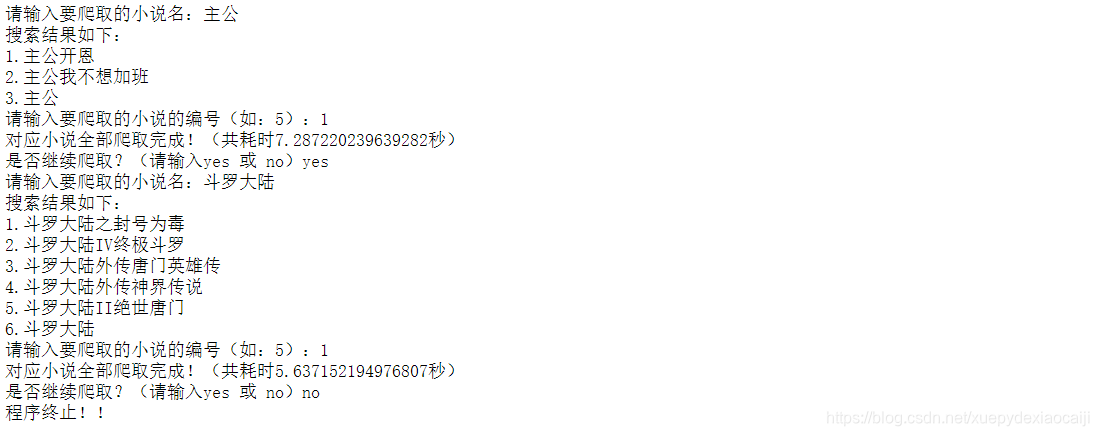
print("对应小说全部爬取完成!(共耗时{}秒)".format(finish_time-start_time))
if __name__ == "__main__":
while True:
main()
input_next = input("是否继续爬取?(请输入yes 或 no)")
if input_next == "no":
print("程序终止!!")
break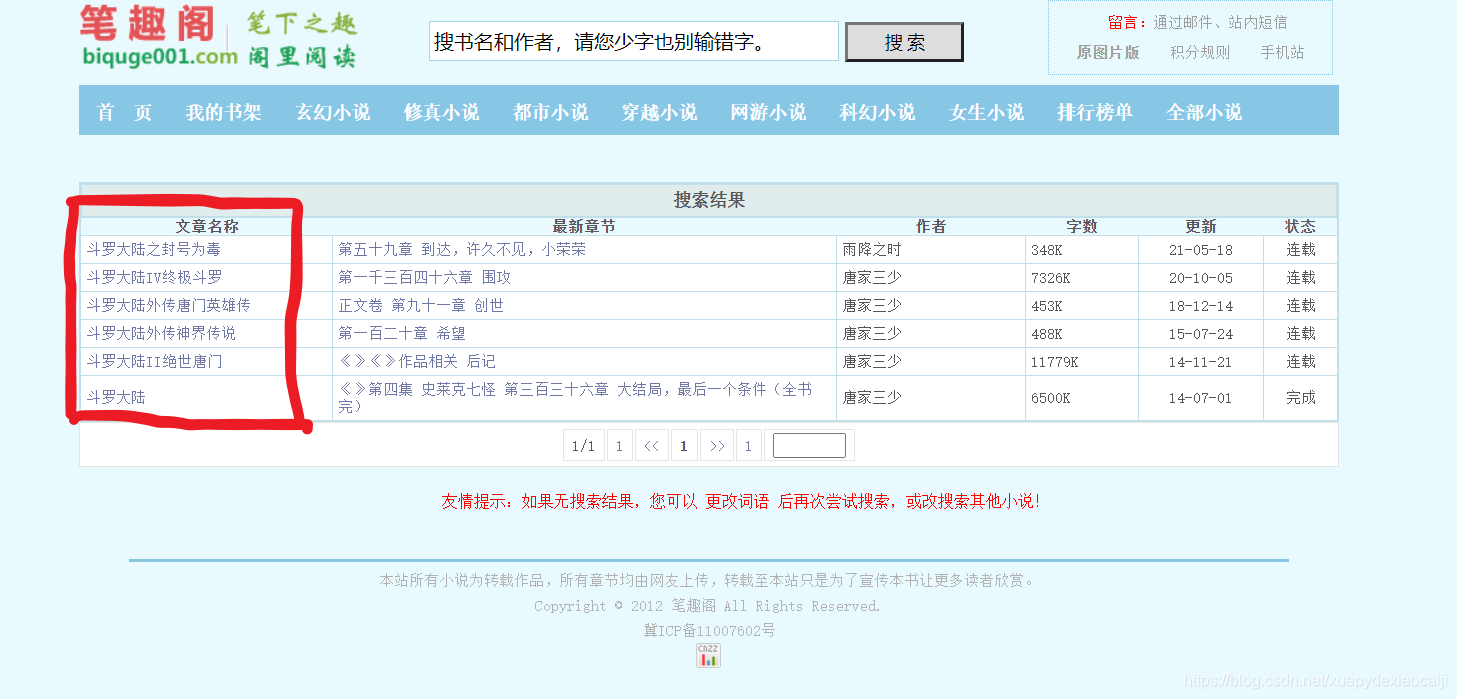
运行结果:

















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









