




深度解析主流大模型推理部署框架(vLLM、SGLang、TensorRT-LLM、Ollama、XInference)+Qwen3全流程部署、优化、运维案例
随着大语言模型技术和应用的迅速发展,在追求性能和稳定性情况下。作为大模型算法工程师,我将从技术架构、性能表现、适用场景等维度,对当前最主流的vLLM、SGLang、TensorRT-LLM、Ollama和XInference等推理框架进行深度分析,并提供Qwen3-30B-A3B-Instruct模型的实际部署案例。
1. vLLM: 基于PagedAttention的高性能推理引擎
vLLM由伯克利大学团队开发,是当前最受欢迎的开源推理框架之一。其核心创新在于PagedAttention和Continuous Batching技术,解决了大模型推理中的显存效率与吞吐量瓶颈。
地址:https://github.com/vllm-project/vllm.git

1.1 核心技术架构
vLLM的技术架构基于PyTorch深度优化,主要包含以下关键组件:
PagedAttention机制
借鉴操作系统内存分页管理思想,将注意力键值对(KV Cache)存储在非连续显存空间。传统框架需要为每个请求序列分配连续显存块,而vLLM将KV Cache划分为固定大小的"页",实现动态分配和复用。这种设计将显存利用率从传统框架的60%提升至95%以上。
PagedAttention:KV 缓存被划分为块;块在内存空间中不需要连续。
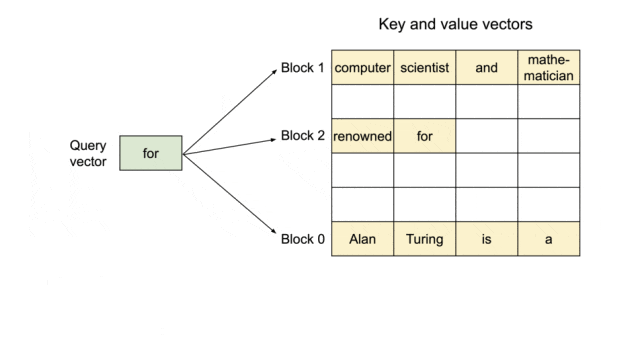
使用 PagedAttention 的请求示例生成过程
Continuous Batching技术
摒弃传统的等待凑批处理模式,能够实时将新请求动态加入处理队列,确保GPU持续处于工作状态。在Llama3.1-170B-FP8单H100测试中,TTFT仅为123ms,显著优于其他框架。
多卡并行优化
支持张量并行和流水线并行,通过NCCL/MPI通信库实现模型权重的智能切分与同步,既优化了内存使用,又提升了整体计算性能。
1.2 性能表现分析
根据最新的基准测试数据,vLLM在多项指标上表现突出:
- 显存利用率: 95%以上
- TTFT (Llama3.1-170B-FP8): 123ms
- 支持并发请求数: 相比传统框架提升5-10倍
- 吞吐量提升: 在高并发场景下提升3-5倍
1.3 适用场景与局限性
适用场景
- 企业级高并发应用(在线客服、金融交易)
- 需要快速响应的实时应用
- 大规模API服务部署
- 多卡集群部署场景
技术局限
- 依赖高端GPU硬件投入成本较高
- 代码复杂度高,二次开发门槛较大
- 分布式调度在超大规模集群中仍需优化
2. SGLang: 基于RadixAttention的高吞吐推理引擎
SGLang同样由伯克利团队开发,专注于提升LLM的吞吐量和响应延迟。其核心技术是RadixAttention,通过高效缓存和结构化输出优化,为高并发场景提供解决方案。
地址:https://github.com/sgl-project/sglang
2.1 核心技术特点
RadixAttention技术
利用Radix树管理KV缓存的前缀复用,通过LRU策略和引用计数器优化缓存命中率。与传统系统在生成完成后丢弃KV缓存不同,SGLang将提示和生成结果的缓存保留在基数树中,实现高效的前缀搜索、重用、插入和驱逐。
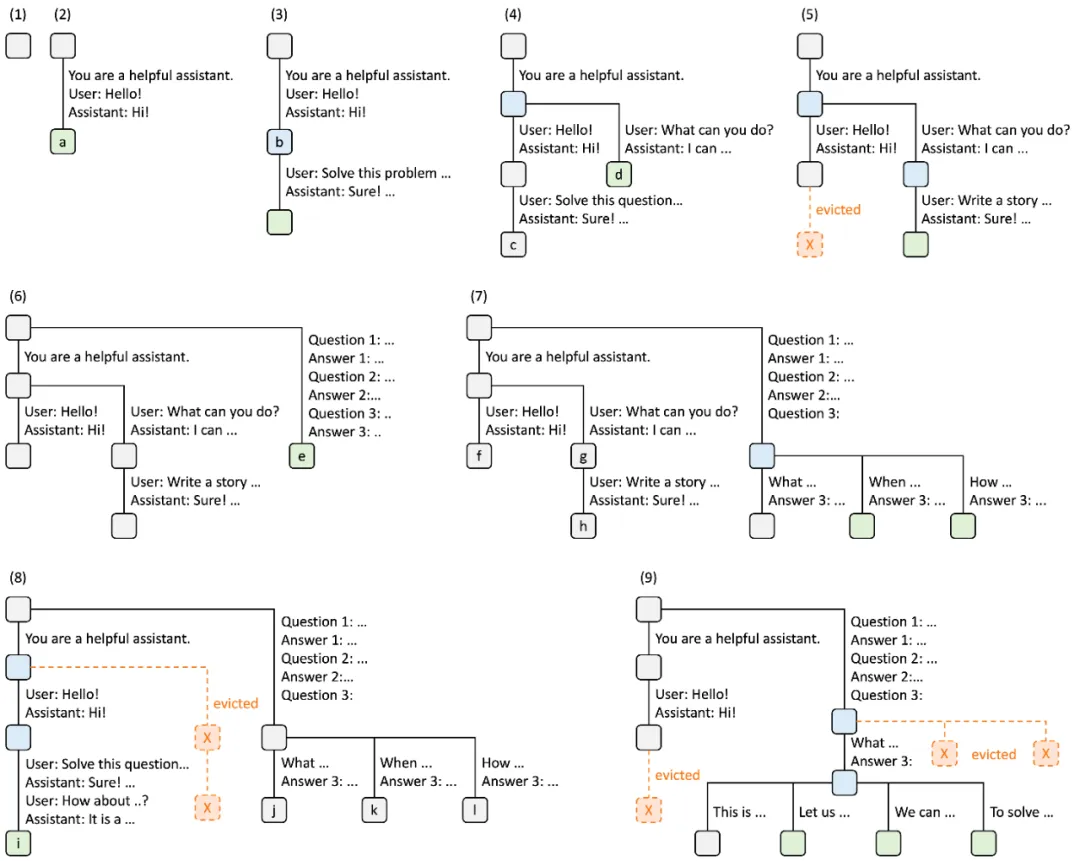
在多轮对话场景测试中,SGLang在Llama-7B上的吞吐量比vLLM高5倍,特别适合需要频繁前缀复用的应用场景。
结构化输出能力
通过正则表达式实现约束解码,可直接输出符合要求的格式(JSON、XML等)。这种机制使SGLang在处理结构化查询时更加高效,减少了后处理工作量。
轻量模块化架构
采用完全Python实现的调度器,虽然代码量较小但扩展性良好。支持跨GPU缓存共享,进一步减少多卡计算浪费。
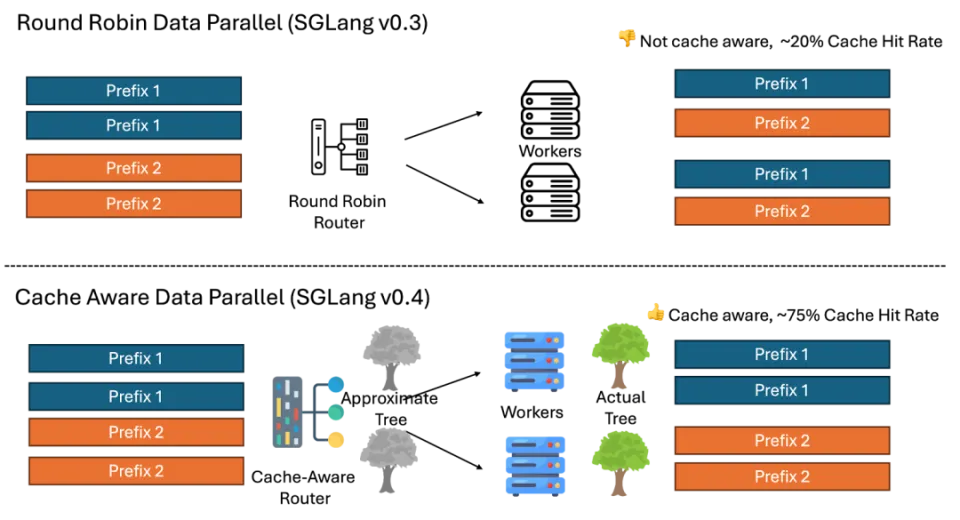
2.2 性能优势
- 多轮对话场景吞吐量提升5倍
- 前缀缓存命中率显著提升
- 结构化输出处理效率优异
- Python实现便于定制开发
2.3 适用场景
- 高吞吐量API服务
- 多轮对话系统
- 结构化数据处理
- 搜索引擎后端服务
3. TensorRT-LLM: NVIDIA深度优化推理引擎
TensorRT-LLM是NVIDIA推出的基于TensorRT的深度优化推理引擎,专为大语言模型设计,旨在充分发挥NVIDIA GPU的计算潜力。
地址:https://github.com/NVIDIA/TensorRT-LLM
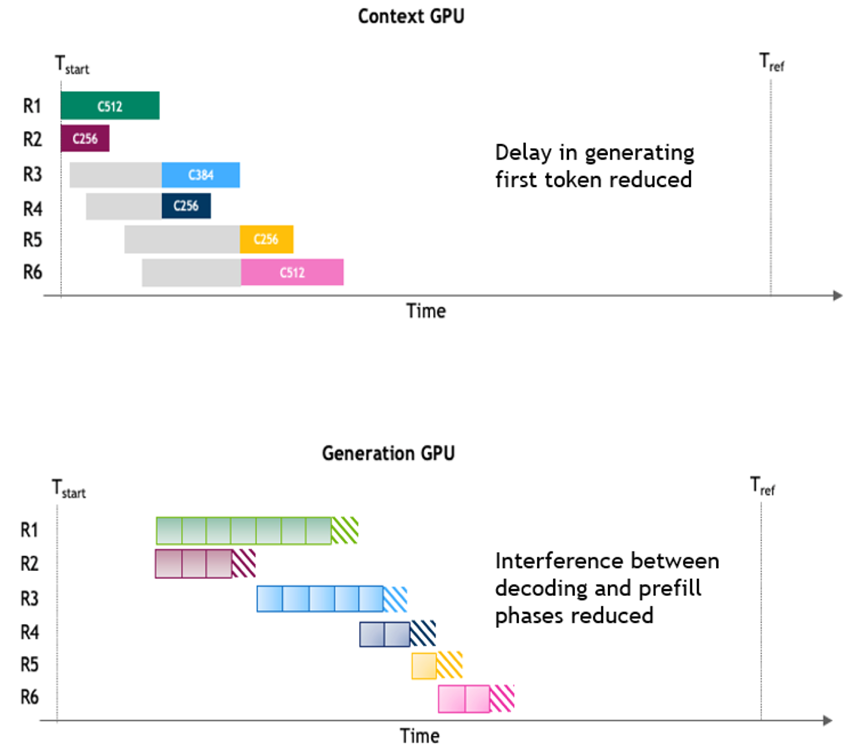
3.1 核心技术架构
预编译优化
通过TensorRT的全链路优化技术,对模型进行预编译,生成高度优化的TensorRT引擎文件。虽然带来冷启动延迟,但能显著提升推理速度和吞吐量。
多精度量化支持
支持FP8、FP4和INT4等多种量化方案。在FP8精度下,TensorRT-LLM能实现接近原生精度的性能,同时显存占用减少40%以上。
内核级优化
针对Transformer架构的各个计算模块进行深度优化,实现高效的CUDA内核。这种优化使TensorRT-LLM在NVIDIA GPU上表现出色。
3.2 性能表现
- 极低延迟,TTFT表现业界领先
- 高吞吐量,适合大规模在线服务
- 充分发挥NVIDIA GPU硬件优势
- 与NVIDIA AI生态无缝集成
3.3 应用场景与限制
适用场景
- 对延迟要求极高的企业级应用
- 实时客服系统
- 金融高频交易
- 需要快速响应的API服务
技术限制
- 仅限NVIDIA CUDA平台
- 预编译过程带来冷启动延迟
- 对非NVIDIA GPU支持有限
- 定制化能力不如开源框架
4. Ollama: 轻量级本地推理平台
Ollama是专为本地部署设计的轻量级推理平台,特别适合个人开发者和研究者使用。
4.1 技术特点
Go语言封装
基于Go语言实现,通过模块化封装将模型权重、依赖库和运行环境整合为统一容器。用户仅需一条命令即可启动模型服务。
地址:https://github.com/ollama/ollama

llama.cpp集成
封装了llama.cpp高性能CPU/GPU推理框架,支持多种精度的整数量化(1.5位到8位)。
跨平台支持
全面支持macOS、Windows和Linux系统,特别适合ARM架构设备如苹果M系列芯片。
4.2 优势与局限
优势
- 安装便捷,一键部署
- 低硬件要求,支持消费级设备
- 数据离线保障,隐私安全
- 冷启动速度快,约12秒
局限
- 并发处理能力较弱
- 扩展性和定制能力有限
- 主要支持文本生成类LLM
- 高负载场景性能不足
5. XInference: 分布式推理框架
XInference是高性能分布式推理框架,专注于简化AI模型运行和集成,特别适合企业级大规模部署。
地址:https://github.com/xorbitsai/inference


5.1 核心架构
分层架构设计
- API层: 基于FastAPI构建,提供RESTful和OpenAI兼容接口
- Core Service层: 引入自研Xoscar框架,简化分布式调度
- Actor层: 由ModelActor组成,负责模型加载和执行
分离式部署
将模型的Prefill和Decode阶段分配到不同GPU,利用DeepEP通信库加速KVCache传输,提升资源利用率。
算子优化
在Actor层引入FlashMLA/DeepGEMM算子,适配国产海光DCU和NVIDIA Hopper GPU。
5.2 适用场景
- 企业级分布式部署
- Kubernetes集群环境
- 智能客服系统
- 知识库问答应用
- 多模态任务处理
6. Qwen3-30B-A3B-Instruct模型部署实战
基于以上框架分析,下面提供Qwen3-30B-A3B-Instruct模型在各框架上的详细部署案例。
6.1 vLLM部署案例
环境准备
# 安装vLLM
pip install vllm
# 或使用Docker
docker pull vllm/vllm-openai:latest
单卡部署
from vllm import LLM, SamplingParams
# 初始化模型
llm = LLM(
model="Qwen/Qwen3-30B-A3B-Instruct-2507",
tensor_parallel_size=1,
gpu_memory_utilization=0.9,
max_model_len=32768,
trust_remote_code=True
)
# 设置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=2048
)
# 生成文本
prompts = ["解释什么是人工智能?"]
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {
prompt!r}, Generated text: {
generated_text!r}")
多卡并行部署
from vllm import LLM, SamplingParams
# 4卡张量并行
llm = LLM(
model="Qwen/Qwen3-30B-A3B-Instruct-2507",
tensor_parallel_size=4,
gpu_memory_utilization=0.85,
max_model_len=32768,
trust_remote_code=True
)
API服务部署
# 启动vLLM OpenAI兼容API服务
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen3-30B-A3B-Instruct-2507 \
--tensor-parallel-size 4 \
--gpu-memory-utilization 0.85 \
--max-model-len 32768 \
--trust-remote-code \
--port 8000
客户端调用
import openai
client = openai.OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123"
)
completion = client.chat.completions.create(
model="Qwen/Qwen3-30B-A3B-Instruct-2507",
messages=[
{
"role": "user", "content": "介绍一下深度学习的核心概念"}
],
temperature=0.7,
max_tokens=2048
)
print(completion.choices[0].message.content)
6.2 SGLang部署案例
环境安装
# 安装SGLang
pip install sglang[all]
# 或从源码安装最新版本
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
启动SGLang Runtime
# 单卡启动
python -m sglang.launch_server \
--model-path Qwen/Qwen3-30B-A3B-Instruct-2507 \
--port 30000 \
--trust-remote-code
# 多卡并行启动
python -m sglang.launch_server \
--model-path Qwen/Qwen3-30B-A3B-Instruct-2507 \
--tp-size 4 \
--port 30000 \
--trust-remote-code
Python客户端使用
import sglang as sgl
# 设置默认后端
sgl.set_default_backend(sgl.Runtime(model_path="Qwen/Qwen3-30B-A3B-Instruct-2507"))
@sgl.function
def multi_turn_question 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2613
2613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









