




 本文详细介绍了OCR(光学字符识别)的基本流程,包括预处理的二值化和方向校正,文字检测中的MSER方法,深度学习和模板匹配在文字识别中的应用,以及语义纠错的HMM模型。重点讨论了预处理的重要性以及深度学习在现代OCR中的角色。
本文详细介绍了OCR(光学字符识别)的基本流程,包括预处理的二值化和方向校正,文字检测中的MSER方法,深度学习和模板匹配在文字识别中的应用,以及语义纠错的HMM模型。重点讨论了预处理的重要性以及深度学习在现代OCR中的角色。
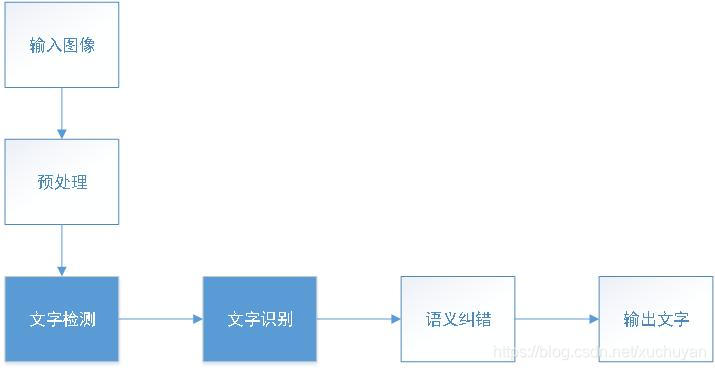
一 OCR背景及基本流程
光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
预处理:包括二值化,噪声去除,倾斜校正等;
文字检测:对图片中的文字进行切割;
文字识别:早期采用模板匹配,后来以特征提取为主,近些年来深度学习在人脸识别、目标检测与分类中达到前所未有的高度,开启了深度学习在文字分类的新浪潮。
语义纠错:根据语言的上下文关系,对识别结果进行校正。
开源OCR框架Tesseract始于1985年,至今仍在不断迭代和优化,4.0版本增加对神经网络的支持。
二 预处理
2.1二值化
实际中的图片大多数都是彩色图像,在文字识别中,多余的色彩是没有意义的,需要对彩色图进行处理,使得图片只剩下前景信息和背景信息,这就叫二值化。
为了减小光线对图片的影响,可以采用自适应二值化方法。
2.2方向校正
在拍摄照片时,会不可避免倾斜,需要对倾斜方向进行校正。常用的校正方法有直线投影,Hough变换法。这些校正方法用在平面的校正时效果好。
三 文字检测
3.1通常的文字检测方法
1基于滑动窗口全图扫描,对每个窗口纹理特征(HOG,Gabor,LBP,Haar)进行二分类,分类器可采用SVM,Adaboost等,确定文字框。该方法对分类器的要求很高,要求能应对各种字体和背景的形式,而且大量的扫描滑动窗口对性能损耗十分严重。
2基于底层规则先分割得到小区域再组合成文字区域,以MSER和S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7006
7006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









