







一、了解深度学习
1.预测期(神经元)
是要输入x,就会得到y,中间过程由自己完成。
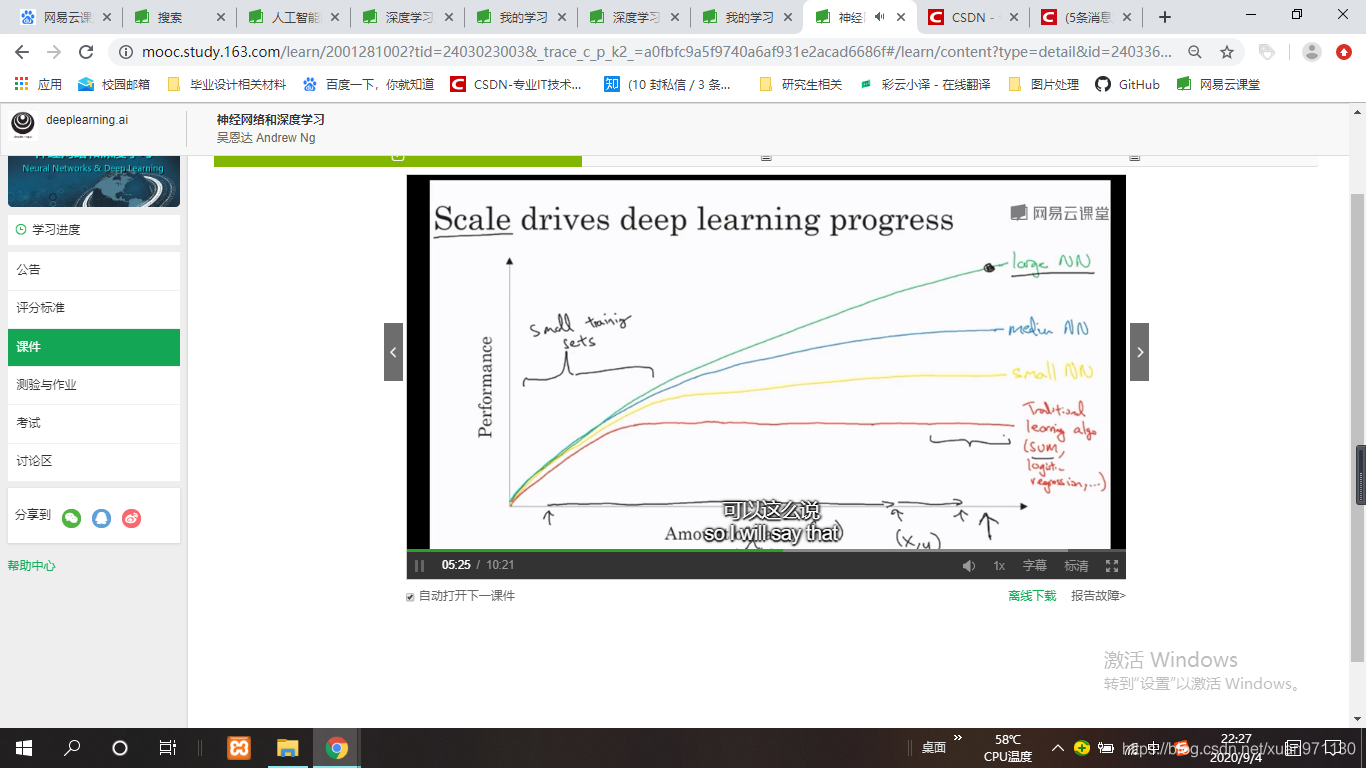
2.(1)规模一直在推动人工智能学习的进步。
说到规模,我们需要一个有许多隐藏单元的神经网络,许多参数,许多连接。
在今天,我们要获得一个性能比较好的神经网络,要么训练一个更大的神经网络,要么需要更多的数据。
数据足够大时,模型才比较稳定。
Sigmoid函数:S型函数
Relu函数:激活函数,修正线性单元ReLU
(2)计算速度的提升促进了计算机深度学习的发展。
二、神经网络编程的基础知识
1.logistic回归是一个用于二分分类的算法
问题:给出一个图片,如何快速实现该图片的特征标签。是猫输出1,不是输出。
用y来表示输出的结果标签。
(1)来看看一张图片在计算机中是如何保存的。
通常要保存3个独立的矩阵。(红绿蓝三个颜色通道(像素亮度值))
要把这些像素亮度值都放到一个特征向量中,要把这些像素值都提出来,放入一个特征向量x
(如果图像的像素是64*64,那么向量x的维度就是64*64*3(因为是3个矩阵的元素向量)),用n或者nx来表示输入的特征向量的x的总维度。
在二分分类问题中,目标是训练出一个分类器,它以图片的特征向量x作为输入,预测输出的结果标签y是1还是0.也就时预测图片中是否是猫。
(2)后续学习中用到的一些符号。
用一对(x,y)来表示一个单独的样本,x是nx维的特征向量,标签y值为0或1,训练集由m个训练样本构成。
(x^(1),y^(1))表示样本一的输入和输出。用小写m表示训练样本的个数。m_train和m_test分别表示训练样本和测试样本的个数
(3)y = wx+b
为了定义w和b,我们需要定义一个成本函数(cost函数)
定义损失函数为y帽和y的差的平方。或者他们差的平方的二分之一。(但一般不这么做,因为在后期寻找最优的时候,会发现该函数为非凸的,有许多个最优解(波浪形)。利用梯度下降法,可能找不着最优解。)
我们用损失函数来衡量预测输出值y帽和y的实际值有多接近,误差平方不能用梯度下降法。
因此我们定义一个不同的损失函数,它其起这与误差平方相似的作用。这些会给我们一个凸的最优化问题。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









