






认识同级文件下utls.py(setting.py中的指定的主路由配置文件)中
1、path函数

route:请求路径 如:/index/1,/page/2003 等后缀
views:路径中你定义的视图处理函数的名称,一般在同级文件中新创一个py文件写入函数,并在urls.py中引用,
form . import viewsname:地址别名,方便键入,类似于小红小明等别称。
运行过程:path函数先根据键入的url找对应的route,若找到则浏览器对对应的视图函数发请求,得到响应,若没有找到对应的route则浏览器界面返回404.
2、视图函数
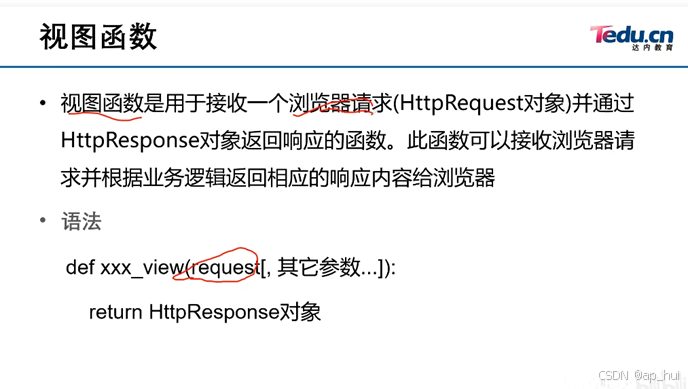
用于接受浏览器请求并返回相应内容给浏览器,其中括号中的request必不可少,而且return的也一定是HttpResponse(变量)这样的格式。
2.1 练习:尝试写入/index,/page/1,/page/2 三个界面。
在urls.py文件中增添三个path函数,调用界面对应的视图函数,切记视图函数后不加(),因为如果加括号只是引用运行结果,要的是引用函数名。
from . import views
urlpatterns = [
#http://127.0.0.1:8000/page/1
path('page/1',views.page_1_view),
#http://127.0.0.1:8000/page/2
path('page/2',views.page_2_view),
#http://127.0.0.1:8000
path('',views.page_index_view),
]同级目录下新建文件views.py
from django.http import HttpResponse
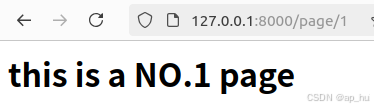
def page_1_view(request):
html ="<h1>this is a NO.1 page </h1>"
return HttpResponse(html)
def page_2_view(request):
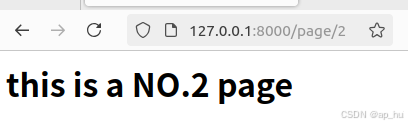
html ="<h1>this is a NO.2 page </h1>"
return HttpResponse(html)
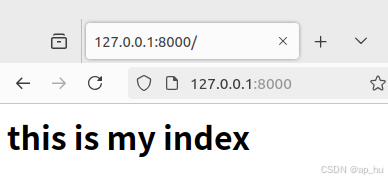
def page_index_view(request):
html="<h1>this is my index</h1>"
return HttpResponse(html)输出结果:
3 、path转换器

在urls.py文件下,使用的格式是path( xx/<int:a>, view), 关于这个我的理解是:view视图函数调用了前面xx/后的整型变量a,也可以直接path(<int:a>, view),直接一个整型当做路径,这个整型变量名为a,被view视图函数调用。 <int:a> 冒号后的a为你定义的整型变量名。
例如:
path( xx/<int:a>, page_view)下,这个path函数请求的url为 http//127.0.0.1:8000/xx/13, 则a=13
path(<int:a>, page_view)下,这个path函数请求的urlurl为http//127.0.0.1:8000/45,则a=45,
在view.py视图函数文件下,def page_view(request,a) 即可。
练习1,page1~100的输出:

解答:在urls.py文件下:
urlpatterns = [
# path('admin/', admin.site.urls),
# http://127.0.0.1:8000/page/n
path('page/<int:a>',views.pagen_view),
]
在view.py文件下:
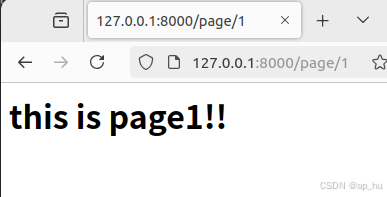
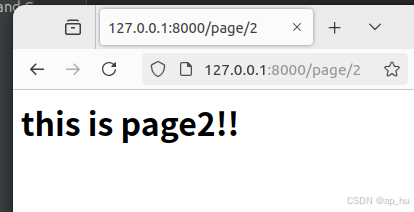
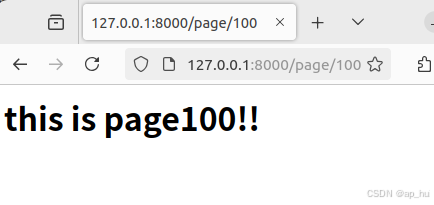
def pagen_view(request,a):
html=f"<h1> this is page{a}!!</h1>"
return HttpResponse(html)输出结果:
urlpatterns的数组遍历
值得注意的是,urls文件下,urlpatterns 的值内是一个个的数组,路径的查找是从上到下,为了证实这一点,在urls文件下输入,我将page1跟page2路径放在数组前两条,如下
urlpatterns = [
# http://127.0.0.1:8000/page/1
path('page/1', views.page1_view),
# http://127.0.0.1:8000/page/2
path('page/2', views.page2_view),
# http://127.0.0.1:8000/page/n
path('page/<int:a>',views.pagen_view),
]
在view.py下,我将page1跟page2的输出删除两个感叹号,
def page1_view(request):
html=f"<h1> this is page1</h1>"
return HttpResponse(html)
def page2_view(request):
html=f"<h1> this is page2</h1>"
return HttpResponse(html)
def pagen_view(request,a):
html=f"<h1> this is page{a}!!</h1>"
return HttpResponse(html)输出结果:page1,page2跟page3~100输出不同结果,
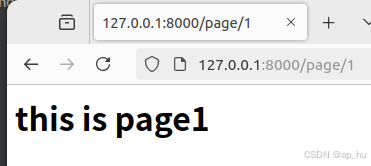
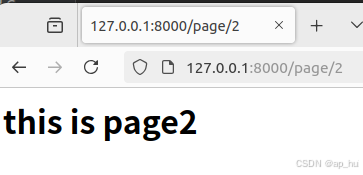
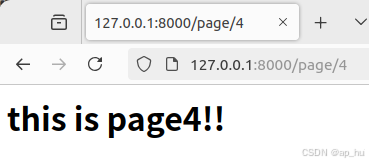
可见path函数先依次从倒下确定了前两个页面的输出,再决定其它的整数。
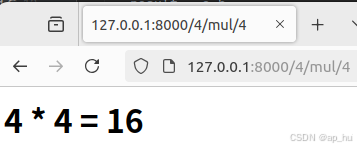
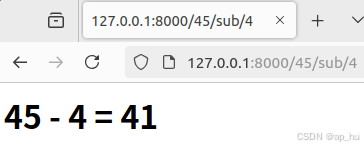
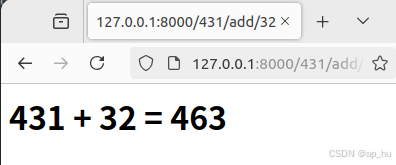
练习2,url计算器:

解答:
urls.py文件下:
urlpatterns = [
# http://127.0.0.1:8000/page/n
path('<int:a>/<str:op>/<int:b>',views.pageop_view),
]
view.py文件下:
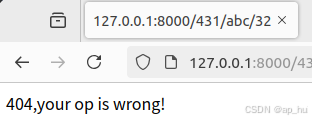
def pageop_view(request,a,op,b):
if op not in ['add','sub','mul']:
return HttpResponse('404,your op is wrong!')
result=0
if op == 'add':
result= a+b
op='+'
elif op=='sub':
result = a-b
op = '-'
elif op =='mul':
result=a*b
op = '*'
html=f"<h1> {a} {op} {b} = {result}</h1>"
return HttpResponse(html)输出结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









