






Fork/join筛选海量数据 gitee代码
技术点
- 利用Fork/join框架来在一个数据集中来筛选出符合条件的数据 ,
- Filter(过滤器)利用策略模式包装 ,
- 实现了TaskManager(任务管理器)来管理任务 ,
- 并用了乐观锁(CAS)来避免多线程的资源争抢问题.
- 使用stream流进行筛选,执行速度更快
知识点
-
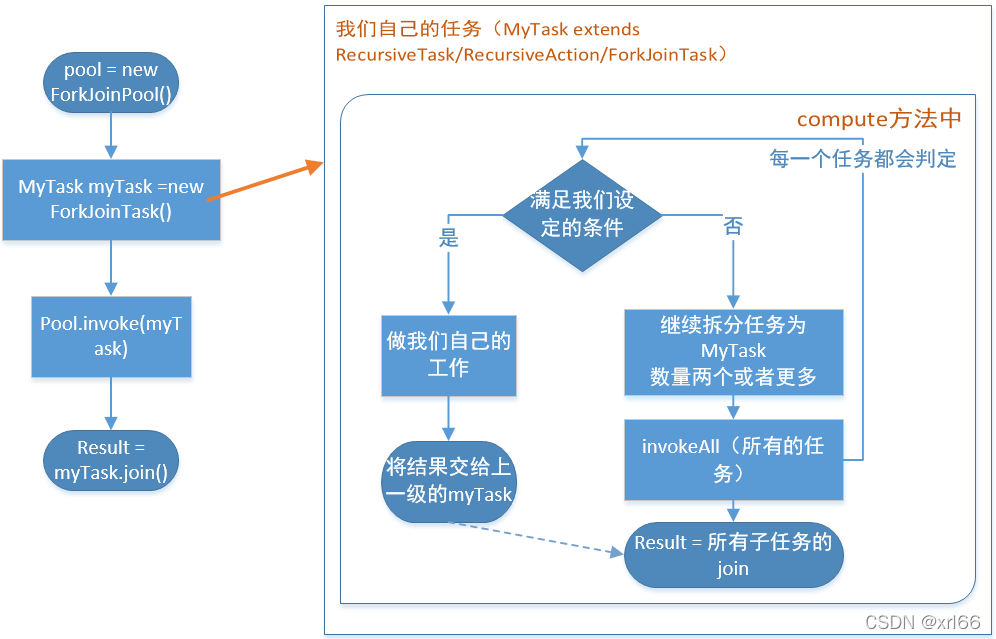
Fork/join框架
基于底层线程池和分治分治策略 ,将大规模的任务拆成小规模的子任务,运行子任务,并将将结果合并.
线程执行时采用了工作窃取算法,先执行完的线程会从没有运行完线程的任务双端队列尾部取任务执行快的帮慢的)
-
利用了策略模式根据环境或者需求,输入的不同的筛选条件来过滤数据.
-
当查询一条数据时 , 利用 Set tasks = ConcurrentHashMap.newKeySet();来构建出一个线程安全的set集合来存储子任务 , 当一个任务得到正确答案后遍历集合,调用task.cancel()方法中断线程并利用CAS来解决终止线程时的线程安全问题.
-
使用stream流进行筛选,执行速度更快。利用stream流操作,可以将文件中的一行读取后直接转为一个CensusData对象,然后与条件进行筛选符合则储存。让所有操作并行,而不是先将数据全部读出来然后再进行封装,筛选等操作。

















 2128
2128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









