






你好,我是郭震
Sora震撼上线,大模型继续狂飙。
通过公布的一些短视频,来看Sora的视频生成效果。
为了更加容易在公众号展示,把视频尺寸压缩为原来的1/3,大家可以看看效果:

以上5个Sora生成视频,因Sora是闭源的,具体的技术细节,无从得知,只能通过公布的技术框架,了解到:
Sora 可能基于GPT-4 多模态版本为基础模型,引入扩展模型(如扩散模型或基于时序卷积网络的生成模块),以支持视频帧的生成与序列化,通过 Transformer 的时间嵌入机制对视频帧间的时序关系进行建模。
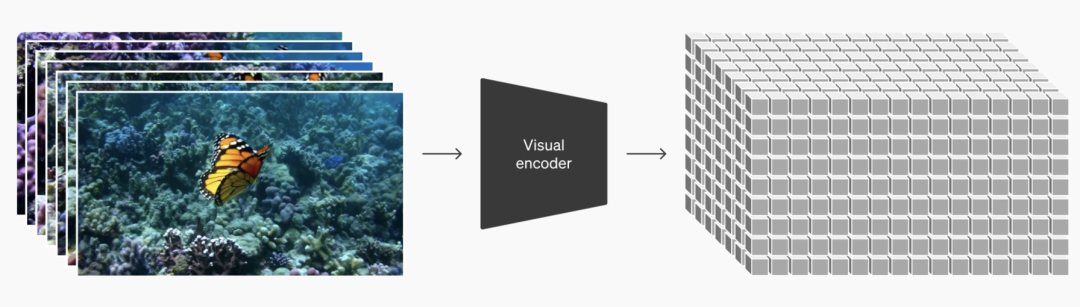
文本到视频的生成通过一个联合的嵌入空间实现,将文本和视频的语义统一对齐。初步生成低分辨率的视频帧序列,使用超分辨率网络提升视频帧质量(如 Real-ESRGAN 模块)。
可能采用扩散去噪模型进行多帧生成的平滑优化,保证连续性。

更多视频生成的技术细节,我们不妨从上周发布的腾讯版Sora来一探究竟,腾讯开源了视频生成的代码,部署在下面两个平台:

同时也发布了技术report:

还能通过PC在线免费体验:

腾讯视频模型称为HunyuanVideo,简称混元视频模型。
根据官方介绍,模型拥有130亿参数,是目前开源领域内参数规模最大的文本生成视频模型。
先看腾讯版Sora生成的几个视频,同样为了兼容公众号文章,视频尺寸压缩为1/3:
因视频已被压缩,抛开清晰度,你能发现:Sora生成的5条视频,腾讯混元生成的这5条视频,有什么区别吗?
衡量文生视频好坏,最重要的三个核心指标是什么?如下所示:

最重要的指标,物理一致性,也就是视频动作是否符合真实物理世界,如重力效果;
第二,场景一致性,帧间是否连续,如布局、光线;
第三,视频是否准确传达了输入文本的核心语义。
下面我亲自实践下,腾讯混元视频模型效果,进入网站,输入这些文字:
中国古代盛唐的江南豫章美景:落霞与孤鹜齐飞,秋水共长天一色
然后点击右下角的按钮,就进入视频生成阶段:
步骤可以说是非常简单,做到了一句话生成视频。提示预计5分钟,实际大概2分钟左右就出来下面视频:
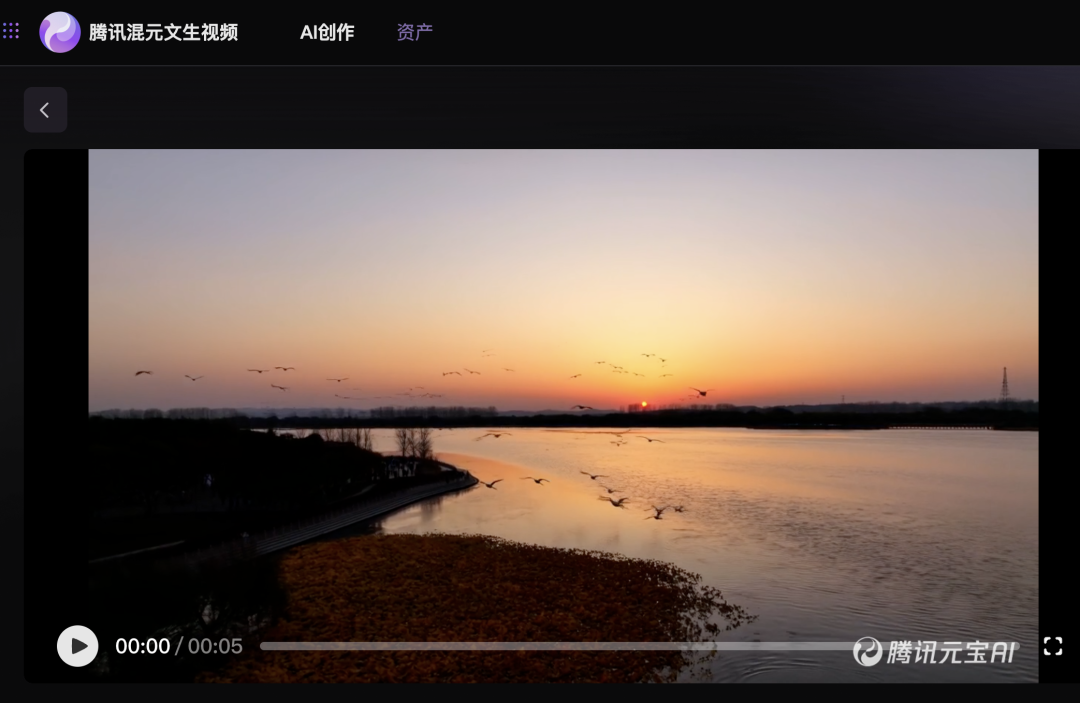
为了展示在公众号里,同样尺寸压缩为1/3后展示:
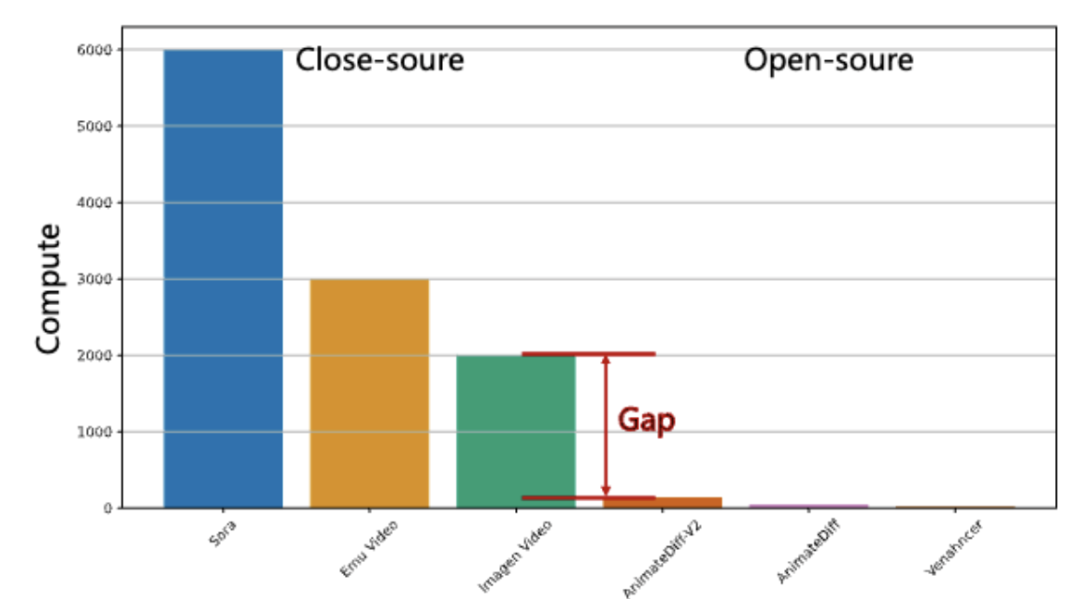
根据腾讯混元视频模型技术Report,混元计算资源远远小于闭源的Sora模型:
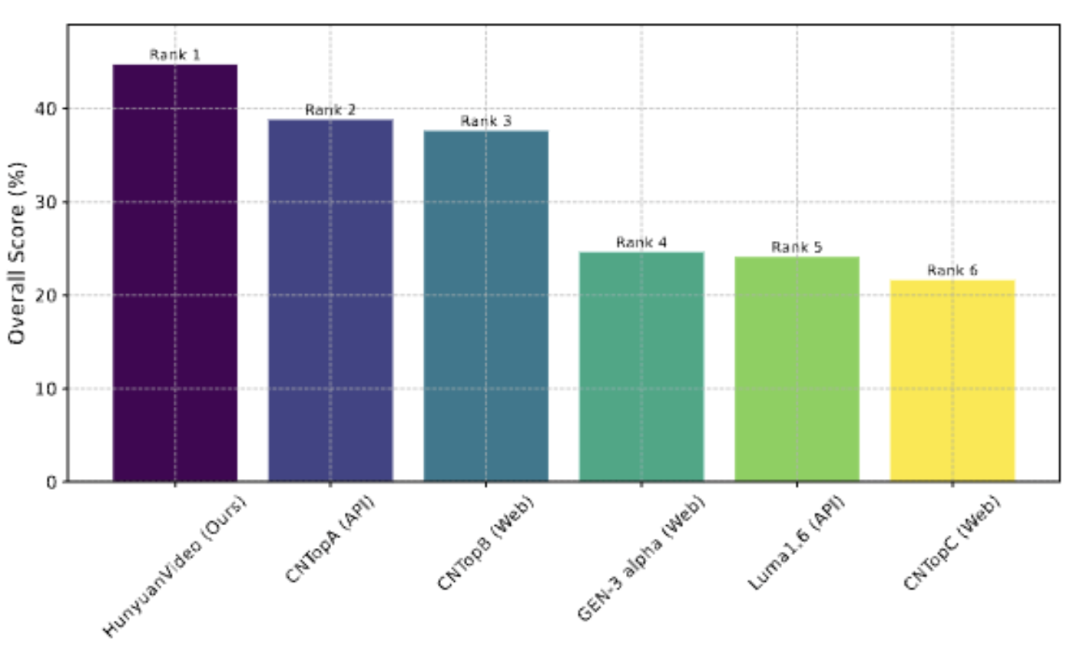
腾讯混元视频模型,目前在开源里面得分最高:
混元模型架构如下:
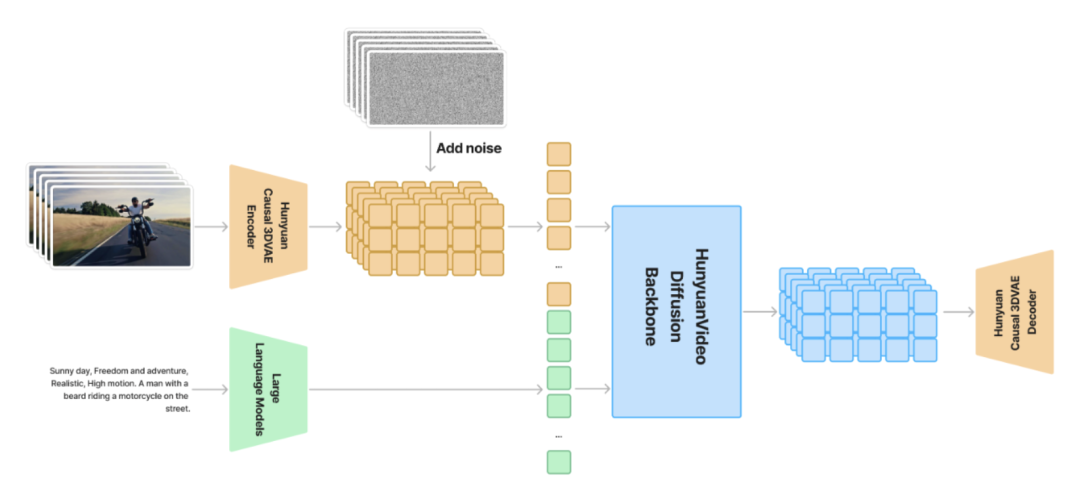
模型在时空压缩的潜在空间中训练,该空间通过因果3D VAE压缩。
文本提示通过大语言模型编码,并作为条件使用。
以高斯噪声和条件为输入,模型生成输出潜变量,并通过3D VAE解码器解码为图像或视频。
3D VAE压缩组件是核心技术之一,其架构如下所示:
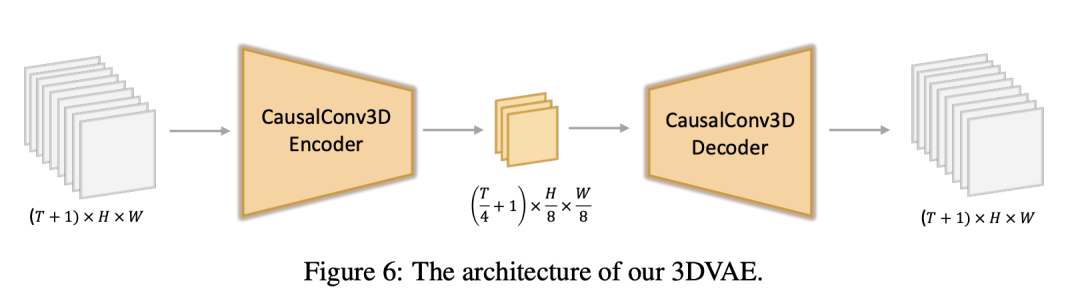
上图中间小块,即为压缩后隐式表达。
另一个核心是文本编码组件:如下图右侧所示,腾讯提出了预训练多模态编码方法:
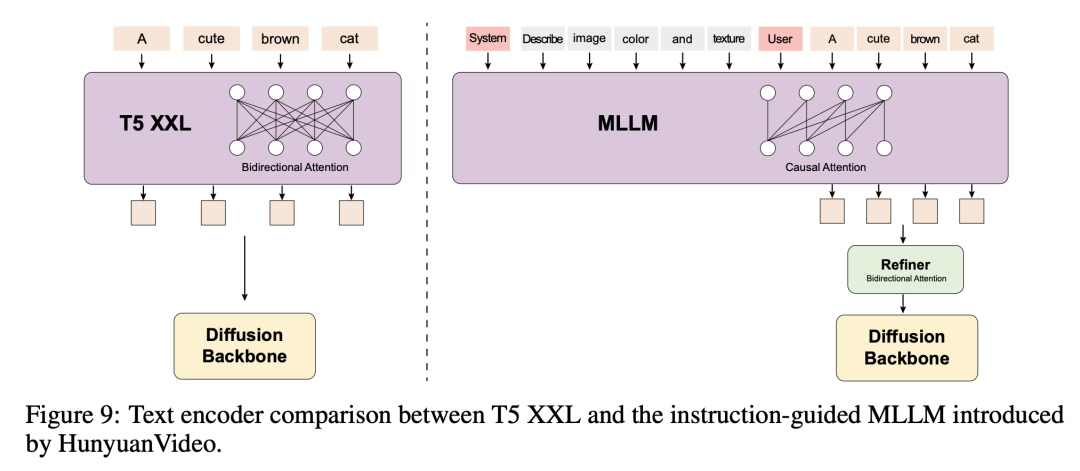
下面详细介绍了MLLM优势,包括:对齐能力强,图片细节处理和复杂推理强,指令跟随能力更强:

训练阶段,模型不基于预训练,而是完全从零开始训。损失函数另外引入了感知损失和对抗损失。训练策略是课程学习策略,从低到高分辨率:

推理阶段主要challenge,单GPU内存会爆。处理方法:采用时空平铺策略,将输入视频在空间和时间维度上分割成重叠的平铺块。每个平铺块分别进行编码/解码,输出结果再拼接在一起:

关于混元视频模型的scaling laws,会在接下来研究:

论文给出了更多生成视频图形展示:


更多有趣的应用,姿势跟随对齐:

多姿势和表情对齐:

总结
腾讯混元视频模型,技术创新还是蛮多的,并且代码开源了,这会活跃社区,技术贡献会被进一步放大,期望越来越好!
想要下载混元39页论文的,在下面我的公众号后台回复:混元
我的AI技术团队,正在招募志同道合的小伙伴,欢迎加入:

如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个⭐️,这样以后就不会错过我的AI教程。谢谢你看我的文章,我们下篇再见!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









