






一、前言
事情是这样的,之前在两次小公司的面试过程中都遇到了类似的 SQL 面试题,面试完后在总结这道面试题的过程中遇到了一些坑,同时也回顾起了很多遗忘的知识点,在这里分享一下自己的一个思考过程,希望大家看完能有所收获,如有错漏之处,请指正!
二、题目与解析
数据表 student 数据如下:
| id | name | subject | score |
|---|---|---|---|
| 1 | 张三 | 英语 | 81 |
| 2 | 张三 | 数学 | 75 |
| 3 | 张三 | 语文 | 67 |
| 4 | 李四 | 数学 | 90 |
| 5 | 李四 | 英语 | 81 |
| 6 | 李四 | 语文 | 100 |
| 7 | 王五 | 数学 | 100 |
| 8 | 王五 | 英语 | 90 |
| 9 | 王五 | 语文 | 81 |
| 10 | 刘六 | 数学 | 81 |
| 11 | 陈七 | 数学 | 99 |
建表语句:
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT,
`subject` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`name` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`score` tinyint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `student` VALUES (1, '英语', '张三', 81);
INSERT INTO `student` VALUES (2, '数学', '张三', 75);
INSERT INTO `student` VALUES (3, '语文', '张三', 67);
INSERT INTO `student` VALUES (4, '数学', '李四', 90);
INSERT INTO `student` VALUES (5, '英语', '李四', 81);
INSERT INTO `student` VALUES (6, '语文', '李四', 100);
INSERT INTO `student` VALUES (7, '数学', '王五', 100);
INSERT INTO `student` VALUES (8, '英语', '王五', 90);
INSERT INTO `student` VALUES (9, '语文', '王五', 81);
INSERT INTO `student` VALUES (10, '数学', '刘六', 81);
INSERT INTO `student` VALUES (11, '数学', '陈七', 99);
题目一:请找出各个科目的成绩都大于80的学生姓名
解法一:用 子查询 + WHERE + NOT IN
一开始没有注意到是需要各科成绩都大于80,写的是 SELECT DISTINCT name FROM student WHERE score > 80,然后觉得肯定没这么简单才反应过来是全部都要大于 80,因为是要找到所有都大于 80 的嘛,所以就想到可以先找出有成绩小于等于 80 的学生,其他学生就是所有科目都大于 80的,自然就想到用
子查询然后再NOT IN一下就可以了
SELECT DISTINCT `name` FROM student WHERE `name` NOT IN (SELECT DISTINCT `name` FROM student WHERE score <= 80)
解法二: 用 子查询 + HAVING + NOT IN
这种方式跟上一种方式其实很像,只是过滤的方式不同,WHERE 是针对行过滤,而 HAVING 是针对分组过滤的,后面详细介绍两者的区别,但是这两种方式可能用 HAVING 会更好一点吧,因为 WHERE 需要一行一行去比较,而 HAVING 是一个一个分组去比较,相对来说应该会快一点,这只是我的个人观点,如有错误,请指正!
SELECT `name` FROM student GROUP BY `name` HAVING `name` NOT IN (SELECT DISTINCT `name` FROM student WHERE score <= 80)
解法三:用 HAVING + MIN 函数
这题还可以用 HAVING来解决,用这种方式应该是最简单高效的,太久没用 HAVING,很多细节都忘记了,讲解完题目再给出 HAVING 的相关知识点吧,已经遗忘的小伙伴们可以先看完 HAVING 的讲解再来看题
注意:score 字段必须是整数类型的才能用MIN函数比较,我一开始没注意直接用的是字符串的类型,然后结果一直不对,使用 SELECT name, MIN(score) FROM student GROUP BY name 才发现字符串类型不能用MIN函数,不然比较的是 ASCII 值,所以如果是字符串类型的可以用解法三的方式来解决或者通过 MIN(score + 0) 转成整数类型
SELECT `name` FROM `student` GROUP BY `name` HAVING MIN(score) > 80
解法四:用 HAVING + 计数的方式
因为 HAVING 是先分组再过滤的,所以就想到先统计分组后每个分组的数量,然后再统计每个分组为分数大于 80 的数量,只要两者相等就是每科成绩都大于 80,比如张三分组后 count(*) = 3,但是 SUM(IF(score > 80, 1, 0)) = 1,因为一科英语 81 大于 80,两者不相等,所以不符合题目要求的各科都大于 80
SELECT `name` FROM `student` GROUP BY `name` HAVING COUNT(*) = SUM(CASE WHEN score > 80 THEN 1 ELSE 0 END)
或
SELECT `name` FROM `student` GROUP BY `name` HAVING COUNT(*) = SUM(IF(score > 80, 1, 0))
题目二:请找出只选修了数学的学生姓名
解法一:用 子查询 + WHERE + NOT IN
这道题同样可以用子查询 + NOT IN的方式来解决,因为我们是想找到只选修了数学的学生,那我们就通过逆向思维先找到选修了其他学科的学生,其他学生自然就是只选修了数学的学生
SELECT DISTINCT `name` FROM student WHERE `name` NOT IN (SELECT DISTINCT `name` FROM student WHERE `subject` != '数学');
解法二:用 子查询 + HAVING + NOT IN
这是与一个朋友讨论这道题的时候他给出的一个写法,他当时给出的是下面第一行的写法,那时候对 HAVING 不太熟悉,所以也没有发现问题所在,后面实际去测试的时候发现语法都错误了,简单来说就是 HAVING 后面能使用的元素只有 3 种:常数 、聚合函数 和聚合键,后面再仔细讲解这三种元素,下面给出可行的解法,其实跟解法一也是类似的,只是一个用 WHERE 一个用 HAVING
错解:SELECT `name` FROM student GROUP BY `name` HAVING `subject` NOT IN ('语文', '英语')
正解:SELECT `name` FROM student GROUP BY `name` HAVING `name` NOT IN (SELECT DISTINCT `name` FROM student WHERE `subject` != '数学')
解法三:用 HAVING + 计数的方式
因为 HAVING 是先分组再过滤的,所以就想到先统计分组后每个分组的数量,然后再统计每个分组选修了数学的数量,只要相等就是只选修了数学,不等就是还选修了其他的科目
SELECT `name` FROM student GROUP BY `name` HAVING COUNT(*) = SUM(CASE WHEN `subject` = '数学' THEN 1 ELSE 0 END)
或
SELECT `name` FROM student GROUP BY `name` HAVING COUNT(*) = SUM(IF(`subject` = '数学', 1, 0))
三、知识点补充
1、HAVING 介绍
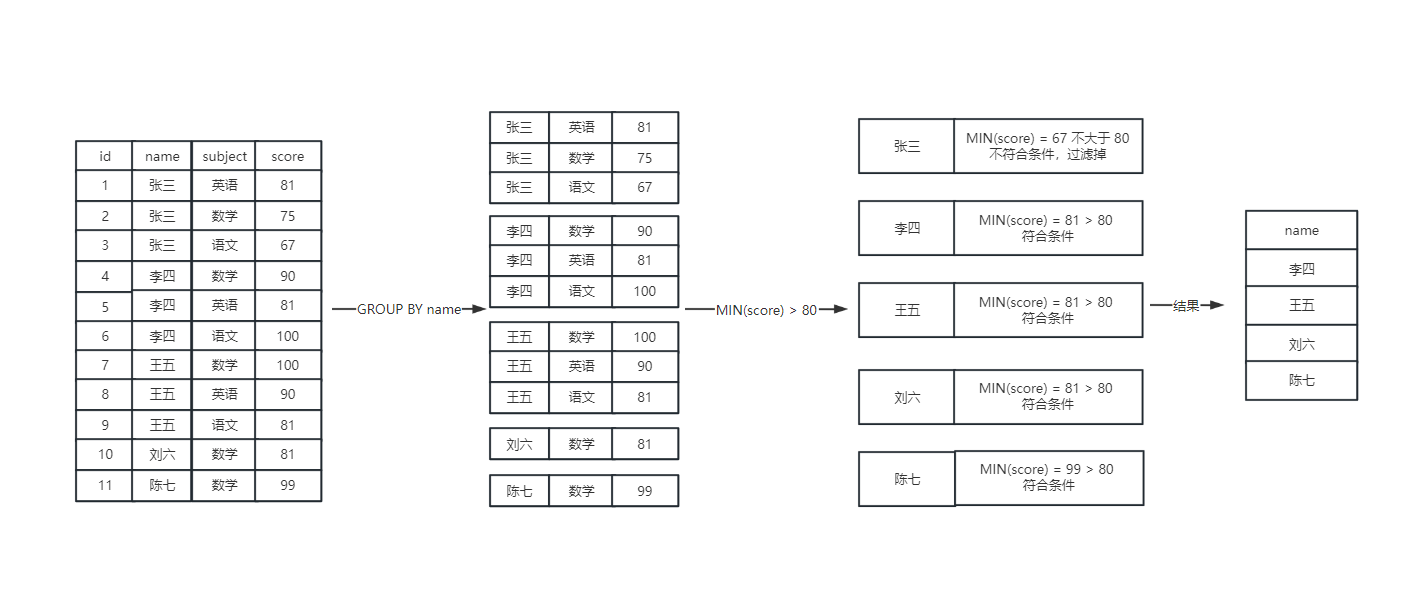
HAVING 通常与 GROUP BY 搭配使用,写在 GROUP BY 的后面,虽然也可以单独使用,但是一般有 HAVING 就有 GROUP BY,当然 GROUP BY 是可以单独使用的。GROUP BY 的功能是分组,对同类记录进行分组,比如按姓名划分,记录由多变少,而 HAVING 的作用是由多变少之后再变少,针对组内进行过滤,比如上面的例子,根据姓名分组后,属于张三的数据聚合在一起后,再通过 MIN 函数进行过滤,如下图所示
2、 HAVING 的使用注意事项
- HAVING 子句的构成要素:常数、聚合函数、聚合键,聚合函数就是 MIN、MAX、AVG、COUNT、SUM 等函数,聚合键就是 GROUP BY 子句中指定的列名,例如 SELECT
nameFROM student GROUP BYnameHAVINGsubjectNOT IN (‘语文’, ‘英语’) 这样写就会报错,因为 HAVING 后面的 subject 不是这三要素之一,不能直接用,改成 SELECTnameFROM student GROUP BYname,subjectHAVINGsubjectNOT IN (‘语文’, ‘英语’) 这样才不会报错,此时的 subject 就是聚合键;还有像 HAVING COUNT(*)= 5 这种,COUNT(*) 就是聚合函数,3 是常数 - HAVING 是分组后对组内元素进行过滤,所以是出现在 GROUP BY 后面的,而 WHERE 是在分组前对每一行进行过滤,是出现在 GROUP BY 前面的
- HAVING 子句的各要素之间可以通过运算符 (>, <, =, !=, <>)、IN、NOT IN 等进行计算
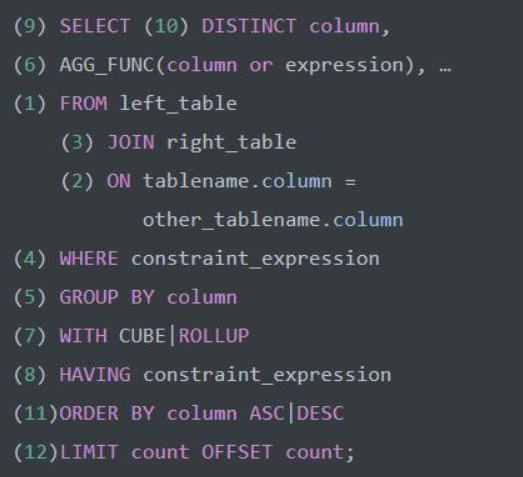
3、SQL 的执行顺序
这里从网上找了一个 SQL 的执行顺序图,可能会对你理解 WHERE、GROUP BY、HAVING 有所帮助,具体的执行过程这里就不展开了
四、最后
解决求平均值等类似的问题都可以用以上的几种解法,正常来说这几种解法应该可以解决面试中大多数比较简单的 SQL 面试题了,HAVING 的用处还是蛮大的,这是只是简单介绍了一下,如果要用好 HAVING 的话还是得去深入了解下,以上内容如果有错误之处,还请大家指出!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









