




导致接口级故障的原因
内部原因
- 程序bug导致死循环
- 某个接口导致数据库慢查询
- 程序逻辑不完善导致耗尽内存等
外部原因
- 黑客攻击、促销或者抢购引入了超出平时几倍甚至几十倍的用户
- 第三方系统大量请求
- 第三方系统响应缓慢等
解决接口故障的核心思想
- 优先保证核心业务和优先保证绝大部分用户
- 丢车保帅,优先保证核心业务
降级
降级指系统将某些业务或者接口的功能降低,可以是只提供部分功能,也可以是完全停掉所有功能
案例
- 双11,订单暂时不允许修改收货地址
- 论坛,降级为只能看帖子,不能发帖子
- App的日志上传接口,可以完全停掉一段时间,这段时间内APP都不能上传日志
常见的实现降级的方式有:
系统后门降级
例如,系统提供一个降级URL,当访问这个URL时,就相当于执行降级指令,具体的降级指令通过URL的参数传入即可
缺点:安全隐患,服务器数量多,需要一台一台去操作
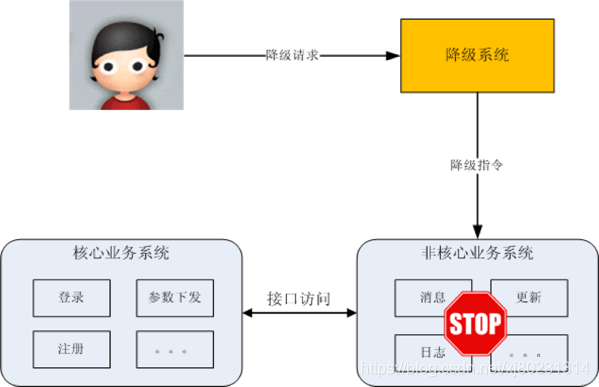
独立降级系统
将降级操作独立到一个单独的系统中,可以实现复杂的权限管理、批量操作等功能。其基本架构如下:
 熔断
熔断
降级的目的是应对系统自身的故障,而熔断的目的是应对依赖的外部系统故障的情况
案例
- A服务的X功能依赖B服务的某个接口,当B服务的接口响应很慢的时候,A服务的X功能响应肯定被拖慢,进一步导致A服务的线程都被卡在X功能处理上,此时A服务的其他功能都会被卡住或者响应非常慢
- 加入熔断机制后,A服务不再请求B服务这个接口,A服务内部只要发现是请求B服务的这个接口就立即返回错误,从而避免A服务整个被拖慢甚至拖死
实现
- 关键是需要有一个统一的API调用层,由API调用层来进行采样或者统计,如果接口调用散落在代码各处就没法进行统一处理了
- 另一个关键是阈值的设计,例如1分钟内30%的请求响应时间超过1秒就熔断,这个策略的“1分钟”“30%”“1秒”都对最终的熔断效果有影响
- 实践中一般都是先根据分析再确定阈值,然后上线观察效果,再进行调优
限流
降级是从系统功能优先级的角度考虑如何应对故障,而限流则是从用户访问压力的角度来考虑如何应对故障
限流指只允许系统能够承受的流量进来,超出系统访问能力的请求将被丢弃
常见的限流方式
基于请求限流
是指从外部访问的请求角度考虑限流
常见方式:限制总量、限制时间量
限制总量:限制某个指标的累积上限
例如,某个直播间限制总用户数上限为100万,超过后无法进入;抢购活动商品数量100个,限制参与用户1万个,超过1万个后直接拒绝
限制时间量:限制一段时间内某个指标的上限
例如,1分钟内只允许10000个用户访问,每秒请求峰值最高为10万
缺点:阈值难于确定
基于资源限流
是指从系统内部考虑的,找到系统内部影响性能的关键资源,对其使用上限进行限制
常见的内部资源:连接数、文件句柄、线程数、请求队列等
例如,采用Netty来实现服务器,每个进来的请求都先放入一个队列,业务线程再从队列读取请求进行处理,队列长度最大值为10000,队列满了就拒绝后面的请求;也可以根据CPU的负载或者占用率进行限流,当CPU的占用率超过80%的时候就开始拒绝新的请求
缺点:难于确定关键资源及其阈值
实现方案:逐步调优,开始时先根据推断选择某个关键资源和阈值,然后测试验证,再上线观察,不合理再优化。
排队
- 排队是限流的一个变种,限流是直接拒绝用户,排队是让用户等待一段时间
- 由于排队需要临时缓存大量的业务请求,单个系统内部无法缓存这么多数据,一般情况下,排队需要用独立的系统去实现,例如使用Kafka这类消息队列来缓存用户请求
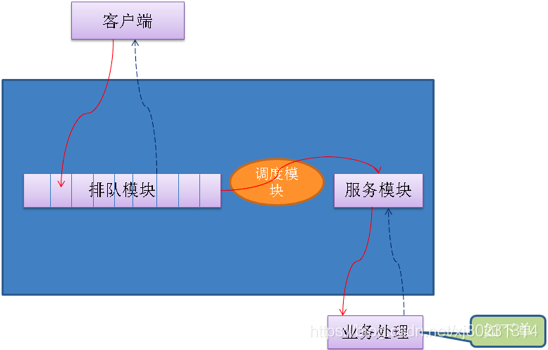
排队模块
将请求以先入先出的方式保存下来,每一个参加秒杀的商品保存一个队列
调度模块
负责排队模块到服务模块的动态调度,不断检查服务模块,一旦处理能力有空闲,就从排队队列头上把用户访问资源请求调入服务模块,并负责向服务模块分发请求
服务模块
负责调用真正业务来处理服务,并返回处理结果,调用排队模块的接口回写业务处理结果

















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









