







 本文介绍了ELK项目背景,涉及日志收集、存储和分析的解决方案。文章详述了filebeat、logstash、kafka、elasticsearch和kibana在ELK架构中的角色,以及面试中可能遇到的关于数据流程、Kafka的ISR和AR、ES插件、分词器等问题。同时,解释了为何使用nginx作为代理以及各个组件的工作原理。
本文介绍了ELK项目背景,涉及日志收集、存储和分析的解决方案。文章详述了filebeat、logstash、kafka、elasticsearch和kibana在ELK架构中的角色,以及面试中可能遇到的关于数据流程、Kafka的ISR和AR、ES插件、分词器等问题。同时,解释了为何使用nginx作为代理以及各个组件的工作原理。
文章目录
-
-
- 1. 这个项目的流程你说一下?
- 2. ELK中哪个负责收集数据
- 3. es有哪些常用的插件?
- 4. 分词器有哪些?
- 5. ES中有哪些数据类型
- 6.. 你们的ES集群方式是什么
- 7. es常用的语句有哪些?
- 8. Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
- 9. kafka中的broker 是干什么的
- 10. kafka中的 zookeeper 起到什么作用,可以不用zookeeper么
- 11. kafka follower如何与leader同步数据
- 12. 什么情况下一个 broker 会从 isr中踢出去
- 13. kafka的工作原理
- 14. 消息队列的两种通信方式:
- 15. 为什么要用nginx做代理
- 16. filebeat工作原理
- 17. Filebeat如何确保至少一次交付
- 18. logstash工作原理:
- 19. es读写数据工作原理
-
很多同学在简历上写了运维项目,面试官可能会问哪些问题一定要提前准备好,今天我就来给大家模拟一次面试准备过程,让大家对自己的简历上的项目如何准备有个初步的认识。
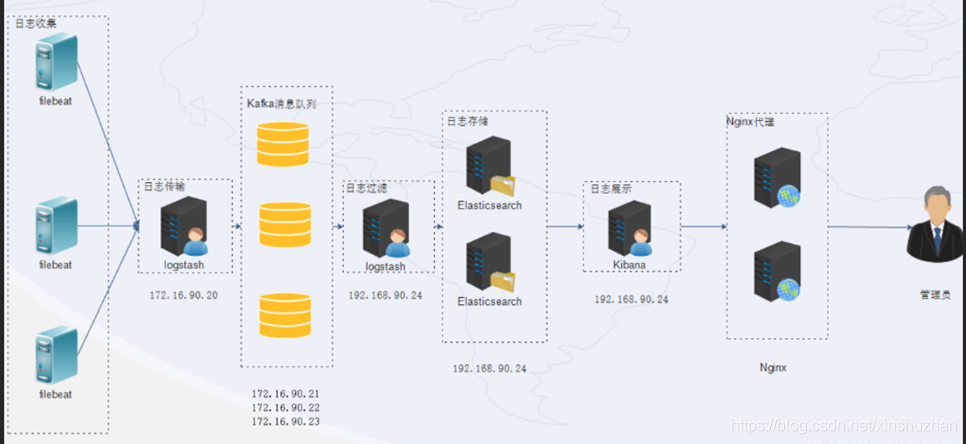
如果你的项目是这个ELK项目,你一般去介绍自己的项目的时候:
项目背景: 公司的线上业务部署在几十台服务器上,线上的日志如果使用ansible执行命令远程去grep,已经越来越不方便了,部门多次开会讨论,决定上线一套日志分析系统。 这套系统的雏形是rsyslog+kafka+elasticsearch,最后演化为图片中的架构。
这个项目是本人负责的,花了一个月的时间。
我们业务服务器上都安装了filebeat,确保数据的一个收集,然后failbeat会把数据发送到logastash或者kafka.
kafka是一个消息队列,订阅者就是filebeat,消费者就是logstash,在logstash里做过滤,分析和清晰,然后 传送给es, 最后通过kibana展示出来。
面试官可能会问的问题:
1. 这个项目的流程你说一下?
首先我们会在业务端都去安装filebeat,在filebeat有两个组件prospector和harvester,这两个组件一起来工作读取文件,并将数据发送到kafka里。kakfa就相当于是一个broker,起到一个缓冲的作用。
kafka的通信模式的话,一个点对点的模式,一

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











