




 本文深入探讨了Sparkcore的核心概念——弹性分布式数据集(RDD)。详细解析了RDD的分布式存储特性,以及其基于内存的弹性计算模式。通过具体示例代码,展示了如何使用SparkContext进行数据读取、转换及计算,最后输出结果。
本文深入探讨了Sparkcore的核心概念——弹性分布式数据集(RDD)。详细解析了RDD的分布式存储特性,以及其基于内存的弹性计算模式。通过具体示例代码,展示了如何使用SparkContext进行数据读取、转换及计算,最后输出结果。
Spark core 原理
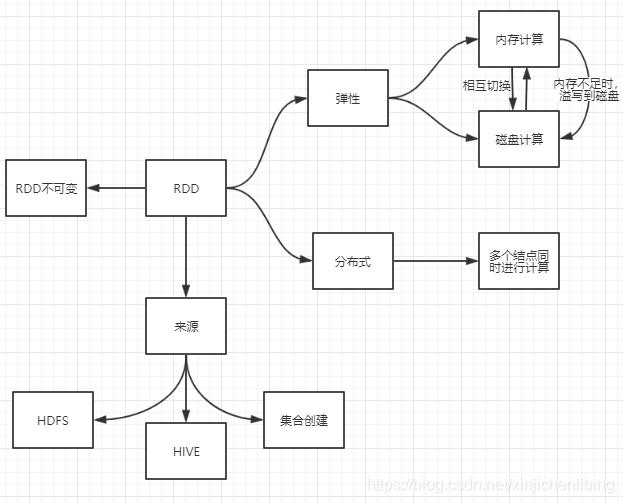
1.弹性分布式数据集(RDD)
1.1概念
数据集:需要运算的数据集合
分布式的:
Spark加载的数据都是以分区的形式存储在各个节点上的,各个节点的分区组合在一起就是一个RDD,所以它是分布式的。
基于内存的(弹性的):
Spark在进行数据的转换或者计算的时候都是在内存中完成的,如果内存资源不够的话 ,那么它就会在磁盘中进行计算。
1.2程序解析
程序代码
package com.terry.sparkcore
import org.apache.spark.{SparkConf, SparkContext}
object WorldCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("WorldCount")
.setMaster("local[4]")
val sc = new SparkContext(conf)
val filePath="C:/Users/wwlh/Desktop/gitTest/window/test.java"
val fileRdd = sc.textFile(filePath,4)
val words = fileRdd.flatMap(lines => lines.split(" ")).filter(word => word!=" ")
val wordcount = words.map(x=>(x,1)).reduceByKey(_+_)
wordcount.foreach(x=>{println(x)})
Thread.sleep(9999999)
sc.stop()
}
}
代码工作流程
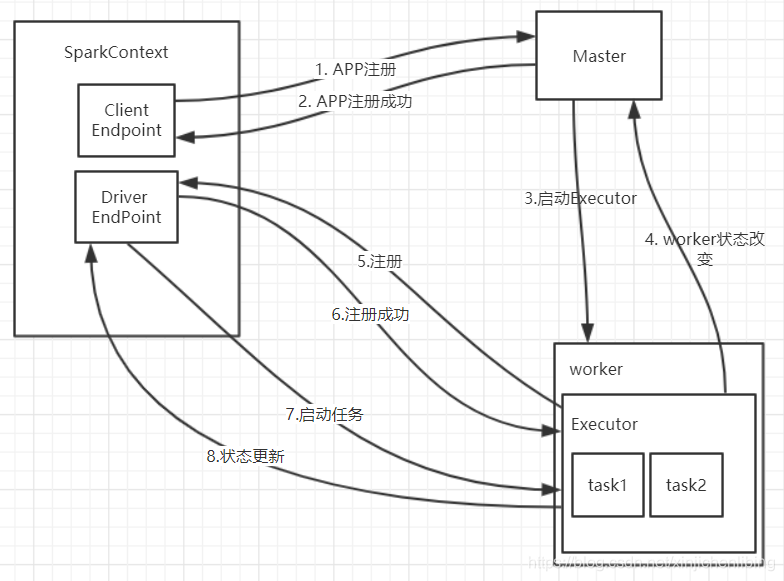
RDD执行流程
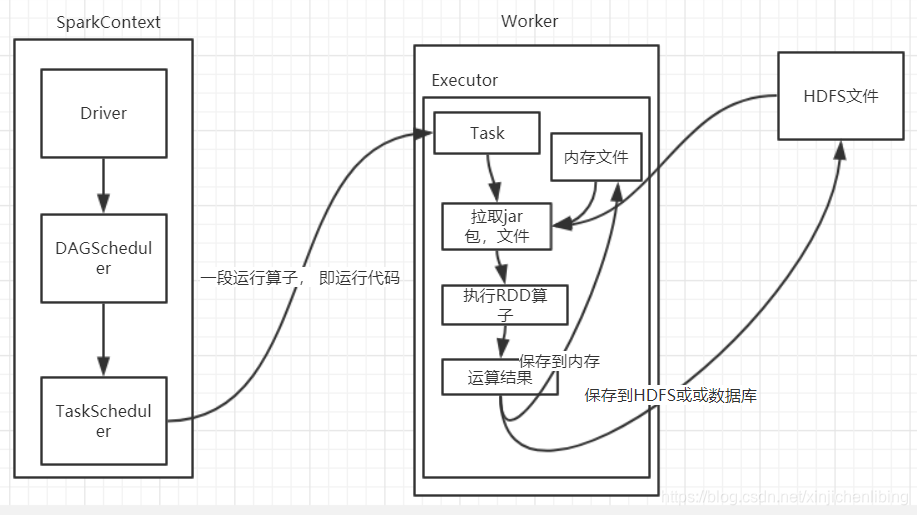
RDD流程解析
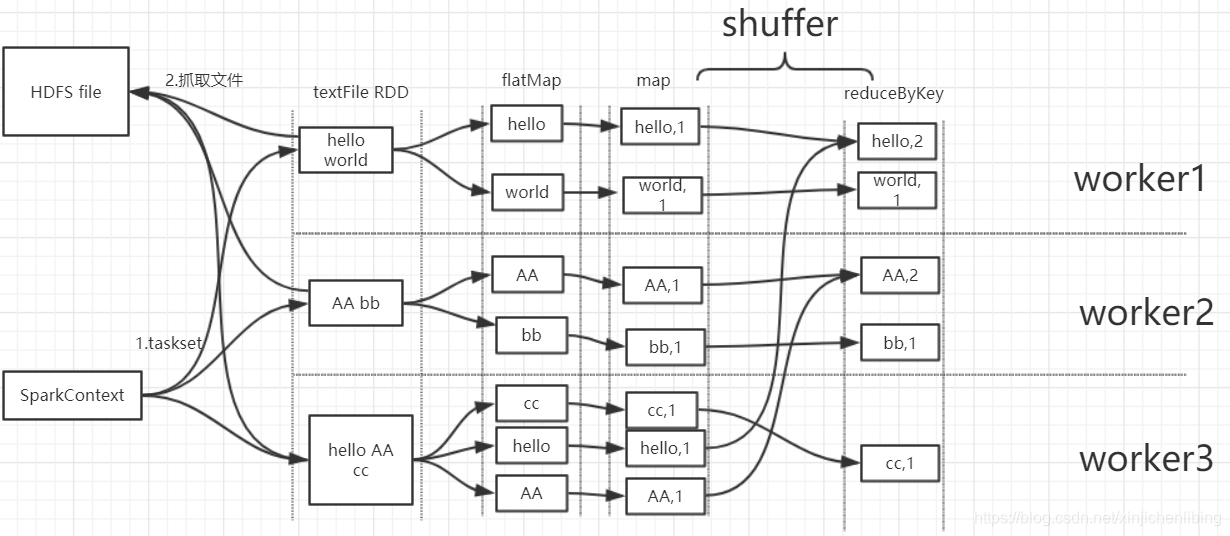
sparkContext的整个启动过程


















 2048
2048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









