




本文章是课程 动手学大模型应用全栈开发-活动详情 | DatawhaleTask02:大模型进阶实战(二选一)的学习笔记。
一、RAG 介绍与必要性
- RAG 定义:Retrieval Augmented Generation,通过引入外部知识库检索相关信息,增强大模型生成过程,生成更准确、符合上下文的答案。
- 解决基础大模型痛点:
- 知识局限性:模型知识限于训练数据,无法掌握实时或非公开知识。
- 数据安全性:无需将私有数据纳入训练集,避免泄露风险。
- 大模型幻觉:基于概率生成易产生错误内容,尤其在未知领域。
- 优势:简单有效,已成为主流大模型应用方案之一,显著减少幻觉、提升事实准确性。
- RAG 基本三步骤:
- 索引(Indexing):文档分割成 Chunk → 构建向量索引。
- 检索(Retrieval):查询与 Chunk 相似度计算 → 取出相关 Chunk。
- 生成(Generation):检索 Chunk + 查询作为上下文 → 输入 LLM 生成回答。
二、完整 RAG 链路
- 整体流程:
- 离线计算(知识库构建):
- 解析多格式文档(PDF、Word、PPT 等),可能需 OCR。
- 切割成 Chunk → 清洗、去重(知识质量决定 RAG 效果)。
- 向量化(Embedding):用 Embedding 模型将 Chunk 转为向量 → 存入向量数据库(如 Milvus)。
- 好的 Embedding 模型:语义相似文本向量距离近,反之远。
- 在线计算(实时查询):
- 用户 Query → Embedding → 与数据库向量计算相似度(e.g., 余弦相似度)。
- 优化检索:
- 召回(Recall):快速粗筛(TF-IDF、BM25 等字符串匹配),降低计算量。
- 精排(一阶段检索):向量相似度精确检索(FAISS、Annoy 等加速)。
- 重排(Rerank,二阶段):用 Reranker 模型进一步排序,提升准确率(解决大知识库退化问题)。
- 计算量顺序:召回 > 精排 > 重排;效果顺序:召回 < 精排 < 重排。
- 选 top-k Chunk → 拼接 Prompt → 输入 LLM 生成。
- 离线计算(知识库构建):
- 最新发展(截至 2025 年 12 月):
- 从 Naive RAG → Advanced RAG(查询优化、重排) → Modular RAG(模块化) → Agentic RAG(智能体驱动,自适应规划、多步推理)。
- 多模态扩展、长上下文融合、自我纠正机制(如反馈循环、批判评估)。
- 工业落地广泛,用于企业知识问答、实时信息整合。
三、开源 RAG 框架
- 主流框架:
- TinyRAG:纯手工简易框架。
- LlamaIndex:数据摄取、索引、查询引擎。
- LangChain:模块化工具链,构建 LLM 应用。
- QAnything:网易有道本地知识库问答,支持多格式/数据库。
- RAGFlow:InfiniFlow 深度文档理解 RAG 引擎。
- 学习成本高 → 本课用简化版实战,基于 Yuan2-2B 系列掌握核心。
四、源2.0-2B RAG 实战(基于 Yuan2-2B-Mars-hf )
该项目构建了一个基于开源大模型的AI科研助手应用,主要用于上传学术PDF论文后自动生成摘要概括,并支持用户针对论文内容进行精准问答。其核心模型和技术包括:
- 生成模型采用浪潮信息开源的Yuan2-2B-Mars(2亿参数级中文大语言模型),推理高效、中文理解能力强,通过特殊分隔符<sep>和<eod>控制输入输出,确保生成稳定可靠。
- 嵌入模型选用BGE-small-en-v1.5(BAAI通用嵌入模型的英文小版本),基于BERT架构,擅长将文本转换为高质量语义向量,支持高效相似度检索。
- 系统采用经典的RAG(检索增强生成)技术框架:使用LangChain整合文档加载(PyPDFLoader)、递归文本切分(RecursiveCharacterTextSplitter)、向量存储与检索(FAISS),在用户提问时实时检索论文中最相关的片段作为上下文输入大模型,大幅减少幻觉、提升回答准确性。
- 前端交互由Streamlit快速搭建,提供简洁的文件上传和聊天式问答体验。整体技术栈完全开源、可本地部署,适合在单卡GPU环境下运行,是当前主流轻量级专域知识问答系统的典型实现。
核心代码
注:下面代码为修改后可运行的代码,与原代码不同。
# 导入所需的库
import torch
import streamlit as st
from transformers import AutoTokenizer, AutoModelForCausalLM
# 核心导入
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_community.document_loaders import PyPDFLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 模型下载
from modelscope import snapshot_download
snapshot_download('AI-ModelScope/bge-small-en-v1.5', cache_dir='./')
snapshot_download('IEITYuan/Yuan2-2B-Mars-hf', cache_dir='./')
# 路径
model_path = './IEITYuan/Yuan2-2B-Mars-hf'
embedding_model_path = './AI-ModelScope/bge-small-en-v1.5'
# 加载模型和 tokenizer
@st.cache_resource
def load_yuan_model():
print("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path, add_eos_token=False, add_bos_token=False, eos_token='<eod>', trust_remote_code=True)
tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>',
'<commit_before>', '<commit_msg>', '<commit_after>', '<jupyter_start>', '<jupyter_text>',
'<jupyter_code>', '<jupyter_output>', '<empty_output>'], special_tokens=True)
print("Loading model...")
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, trust_remote_code=True).cuda()
return model, tokenizer
model, tokenizer = load_yuan_model()
# Yuan2 生成函数(关键:use_cache=False)
def yuan_invoke(input_prompt: any) -> str:
if hasattr(input_prompt, 'text'):
prompt = input_prompt.text
else:
prompt = str(input_prompt)
prompt = prompt.strip() + "<sep>"
inputs = tokenizer(prompt, return_tensors="pt")["input_ids"].cuda()
# 关键修复:关闭 cache,避免 past_key_values None 错误
outputs = model.generate(
inputs,
max_new_tokens=512, # 生成最多512个新token
do_sample=False, # greedy decoding
eos_token_id=tokenizer.convert_tokens_to_ids('<eod>'),
use_cache=False, # 必须关闭!Yuan2 不支持 cache
)
output = tokenizer.decode(outputs[0], skip_special_tokens=False)
# 提取 <sep> 后的内容,直到 <eod>
if "<sep>" in output:
response = output.split("<sep>")[-1].strip()
if "<eod>" in response:
response = response.split("<eod>")[0].strip()
else:
response = ""
return response
# 包装成 Runnable
yuan_llm = RunnableLambda(yuan_invoke)
# Embeddings
@st.cache_resource
def get_embeddings():
return HuggingFaceEmbeddings(
model_name=embedding_model_path,
model_kwargs={'device': 'cuda'},
encode_kwargs={'normalize_embeddings': True}
)
embeddings = get_embeddings()
# Summarizer
def summarize_abstract(abstract_text: str) -> str:
summarizer_prompt = PromptTemplate.from_template(
"假设你是一个AI科研助手,请用一段话概括下面文章的主要内容,200字左右。\n\n{text}"
)
chain = summarizer_prompt | yuan_llm | StrOutputParser()
return chain.invoke({"text": abstract_text})
# RAG Chain
def build_rag_chain(vectorstore):
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
rag_template = """
假设你是一个AI科研助手,请基于背景,简要回答问题。
背景:
{context}
问题:
{question}
""".strip()
rag_prompt = PromptTemplate.from_template(rag_template)
chain = (
{"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)),
"question": RunnablePassthrough()}
| rag_prompt
| yuan_llm
| StrOutputParser()
)
return chain
def main():
st.title('💬 Yuan2.0 AI科研助手(稳定运行版)')
uploaded_file = st.file_uploader("Upload your PDF", type='pdf')
if uploaded_file:
temp_file_path = "temp.pdf"
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.read())
loader = PyPDFLoader(temp_file_path)
docs = loader.load()
# 提取摘要
try:
abstract = docs[0].page_content.split('ABSTRACT')[1].split('KEY WORDS')[0].strip()
except Exception:
abstract = "\n".join([page.page_content for page in docs[:3]])[:4000]
st.chat_message("assistant").write("正在生成论文概括,请稍候...")
summary = summarize_abstract(abstract)
st.chat_message("assistant").write(summary)
# 构建向量库
text_splitter = RecursiveCharacterTextSplitter(chunk_size=450, chunk_overlap=10)
chunks = text_splitter.split_documents(docs)
vectorstore = FAISS.from_documents(chunks, embeddings)
# RAG
rag_chain = build_rag_chain(vectorstore)
if query := st.text_input("Ask questions about your PDF file"):
st.chat_message("assistant").write("正在检索并生成回复,请稍候...")
response = rag_chain.invoke(query)
st.chat_message("assistant").write(response)
if __name__ == '__main__':
main()运行效果
上传OpenVLA论文进行测试。
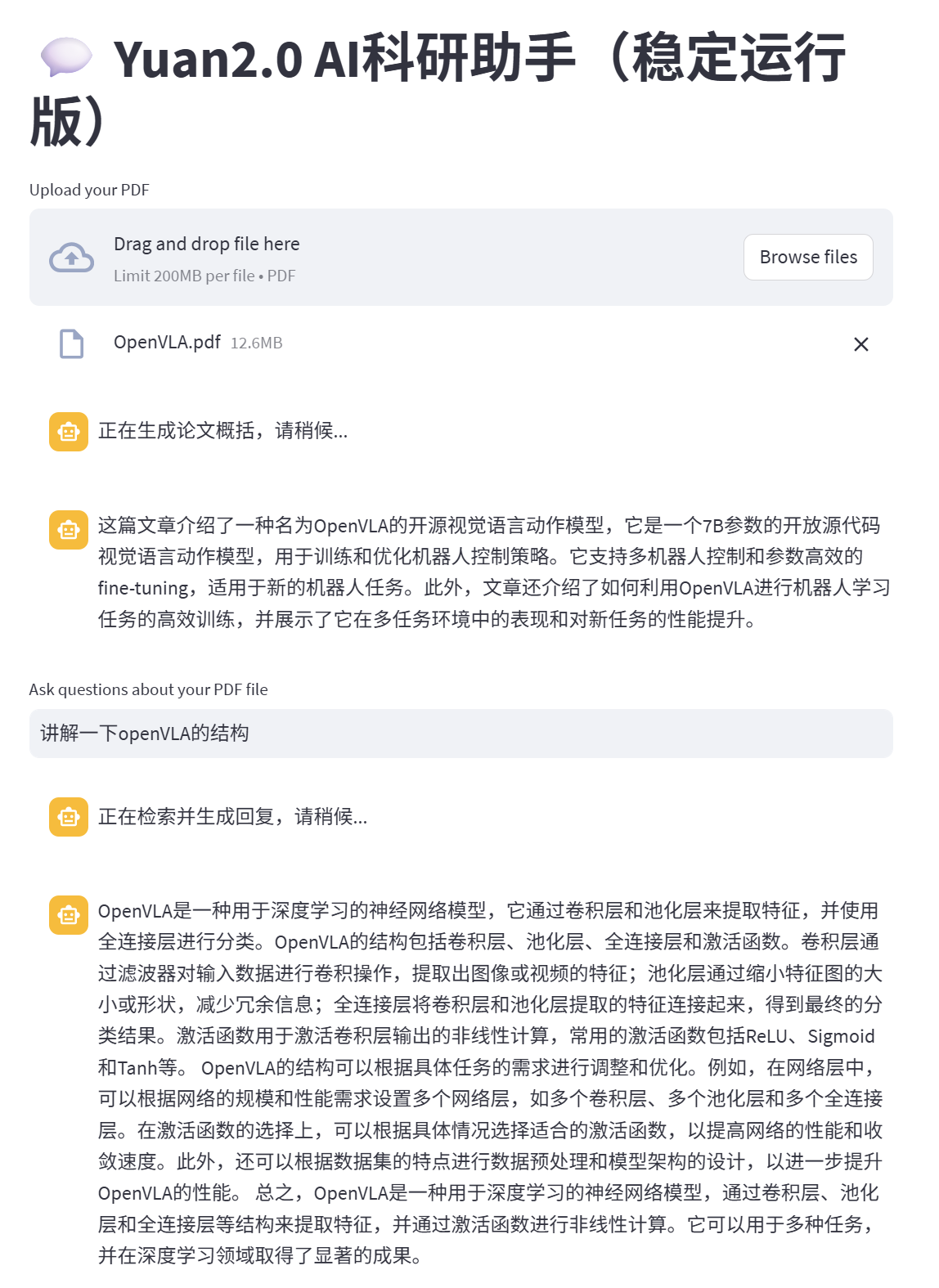
五、作业:RAG知识库开发(原创)
本项目针对大语言模型在特定垂直领域(如中国古代历史)容易产生事实错误、事件时间线混淆或知识幻觉的问题,设计并实现了基于 Retrieval-Augmented Generation(RAG)的增强方案。通过从可靠来源(如模拟的百度百科条目)收集中国古代历史文本数据,进行清洗、去重与语义分块预处理后,采用 BAAI/bge-small-zh 中文嵌入模型构建高效的 FAISS 向量知识库。在检索阶段,利用余弦相似度快速召回最相关的 top-k 文档片段;在生成阶段,将检索到的上下文通过精心设计的 Prompt 模板注入到 Yuan2-2B-Mars-hf 大模型中,指导模型严格基于外部知识作答。实验对比显示,未使用 RAG 时模型依赖自身参数知识容易出现泛化偏差,而引入 RAG 后回答显著更准确、忠实于事实,并附带可追溯的来源文档。该项目充分体现了 RAG 在提升大模型领域知识准确性、减少幻觉方面的实用价值,同时兼顾了中文场景下的嵌入效果与推理效率,适用于历史、教育、文物讲解等垂直问答场景的快速落地。
核心代码
import torch
import os
from transformers import AutoTokenizer, AutoModelForCausalLM
# LangChain 核心导入
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
# ==================== 1. 模型路径配置 ====================
model_name = "IEITYuan/Yuan2-2B-Mars-hf" # 如果本地有路径,可改为本地路径
# 嵌入模型本地路径(你已下载好的)
base_embedding_dir = './AI-ModelScope/bge-small-zh-v1___5'
# 自动查找真实模型目录
def find_local_embedding_path(base_dir):
for root, dirs, files in os.walk(base_dir):
if ('pytorch_model.bin' in files or 'model.safetensors' in files) and 'config.json' in files:
return root
return base_dir
embed_model_path = find_local_embedding_path(base_embedding_dir)
print(f"使用嵌入模型路径: {embed_model_path}")
# ==================== 2. 加载 Yuan2 模型和 tokenizer ====================
print("正在加载 Yuan2-2B-Mars-hf 模型和 tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(
model_name,
add_eos_token=False,
add_bos_token=False,
eos_token='<eod>',
trust_remote_code=True
)
tokenizer.add_tokens([
'<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>',
'<commit_before>', '<commit_msg>', '<commit_after>', '<jupyter_start>', '<jupyter_text>',
'<jupyter_code>', '<jupyter_output>', '<empty_output>'
], special_tokens=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
print("Yuan2 模型加载完成!")
# ==================== 3. Yuan2 生成函数 ====================
def yuan_invoke(input_prompt) -> str:
if hasattr(input_prompt, 'text'):
prompt = input_prompt.text
else:
prompt = str(input_prompt)
prompt = prompt.strip() + "<sep>"
# 只取 input_ids 并移动到模型所在设备
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"].to(model.device) # 关键:只传 input_ids tensor
outputs = model.generate(
input_ids, # 直接传 tensor,不传 dict
max_new_tokens=200,
do_sample=True,
temperature=0.7,
top_p=0.9,
eos_token_id=tokenizer.convert_tokens_to_ids('<eod>'),
use_cache=False # Yuan2 必须关闭 cache
)
output = tokenizer.decode(outputs[0], skip_special_tokens=False)
if "<sep>" in output:
response = output.split("<sep>")[-1].strip()
if "<eod>" in response:
response = response.split("<eod>")[0].strip()
return response
else:
return output.strip()
# 包装为 LangChain Runnable
yuan_llm = RunnableLambda(yuan_invoke)
# ==================== 4. 加载本地嵌入模型 ====================
print("正在加载本地 bge-small-zh 嵌入模型...")
embeddings = HuggingFaceEmbeddings(
model_name=embed_model_path,
model_kwargs={'device': 'cuda' if torch.cuda.is_available() else 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
print("嵌入模型加载完成!")
# ==================== 5. 模拟中国古代历史数据 ====================
raw_data = """
秦始皇,名嬴政,是中国历史上首位皇帝。他于公元前221年统一六国,建立秦朝。统一过程:先灭韩、赵、魏、楚、燕、齐。策略包括远交近攻、贿赂分化等。
六国统一后,秦始皇推行中央集权,统一度量衡、货币、文字。修建长城抵御匈奴。焚书坑儒以巩固统治。
秦朝灭亡于公元前207年,二世胡亥在位时,陈胜吴广起义爆发,导致秦朝迅速瓦解。
汉朝刘邦建立后,推行休养生息政策。汉武帝时打击匈奴,开辟丝绸之路。
唐朝是我国历史上强盛时期,太宗李世民贞观之治,玄宗开元盛世。安史之乱后衰落。
宋朝经济文化发达,发明活字印刷术、火药、指南针。
明朝朱元璋建立,迁都北京,修长城,郑和下西洋。
清朝入关后康熙、雍正、乾隆三帝盛世,后闭关锁国,鸦片战争后逐步沦为半殖民地。
"""
# ==================== 6. 构建知识库 ====================
print("正在构建向量知识库...")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=50)
documents = text_splitter.split_text(raw_data)
vectorstore = FAISS.from_texts(documents, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
print("知识库构建完成!")
# ==================== 7. 构建 RAG Chain ====================
rag_template = """
基于以下上下文回答问题。如果上下文不足以回答,请说“我不知道”。
上下文:
{context}
问题:{question}
回答:""".strip()
rag_prompt = PromptTemplate.from_template(rag_template)
rag_chain = (
{"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)),
"question": RunnablePassthrough()}
| rag_prompt
| yuan_llm
| StrOutputParser()
)
# ==================== 8. 不使用 RAG 的直接生成 ====================
def generate_without_rag(query):
prompt = f"问题:{query}\n回答:"
return yuan_invoke(prompt)
# ==================== 9. 主程序:对比测试 ====================
def main():
query = "秦始皇统一六国的过程是什么?"
print("问题:秦始皇统一六国的过程是什么?" )
print("\n" + "="*60)
print("【不使用 RAG 的回答】")
print(generate_without_rag(query))
print("\n" + "="*60)
print("【使用 RAG 的回答】")
print(rag_chain.invoke(query))
print("\n" + "="*60)
print("【检索到的来源文档】")
docs = retriever.invoke(query)
for i, doc in enumerate(docs, 1):
print(f"来源 {i}:\n{doc.page_content}\n")
if __name__ == '__main__':
main()运行效果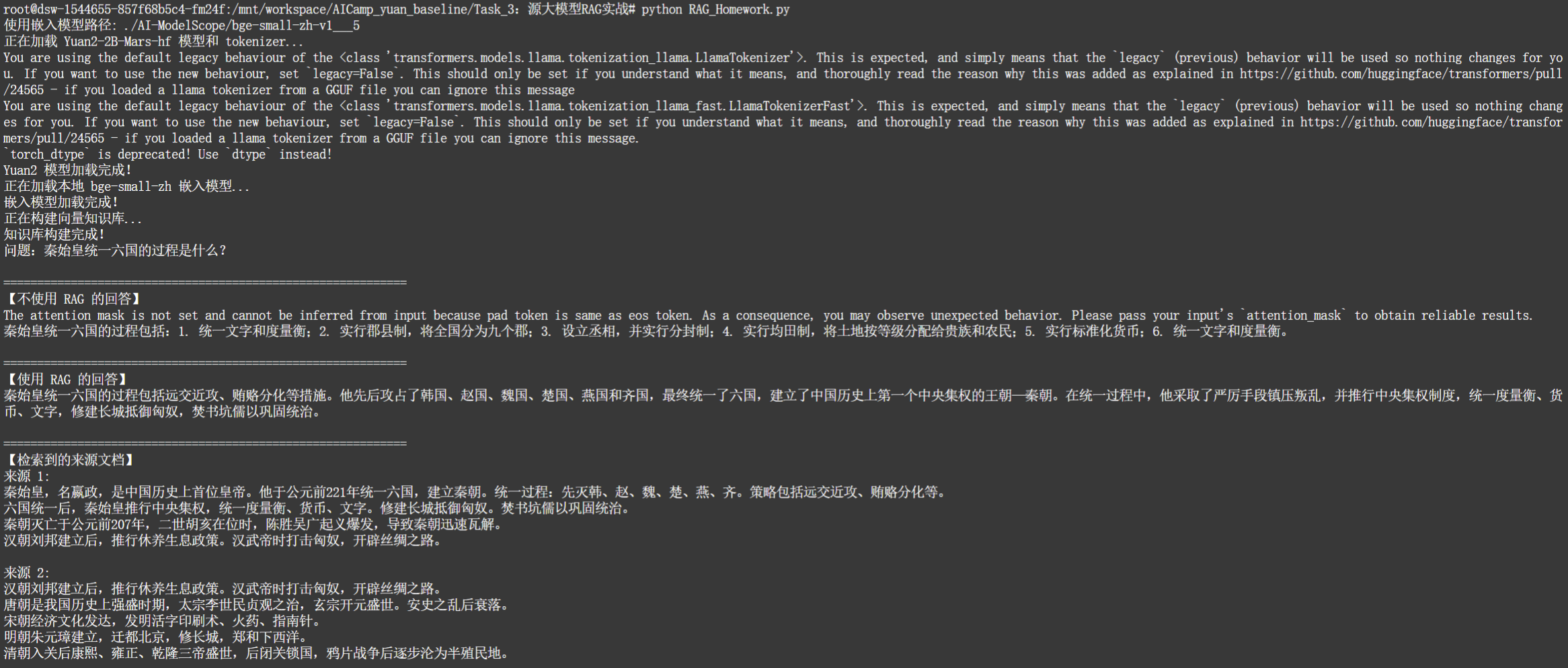

















 2338
2338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









