






 这篇博客主要梳理了MySQL的基础语法,包括库层操作如创建、查看和删除数据库,表层操作如创建、修改和查询表,字段类型介绍,函数类别,存储引擎,索引优化策略,以及事务处理的基本语法。特别强调了索引设计的重要性以及在不同场景下如何有效利用索引。
这篇博客主要梳理了MySQL的基础语法,包括库层操作如创建、查看和删除数据库,表层操作如创建、修改和查询表,字段类型介绍,函数类别,存储引擎,索引优化策略,以及事务处理的基本语法。特别强调了索引设计的重要性以及在不同场景下如何有效利用索引。
文章目录
背景
最近写mongo写的比较多,偶尔回过头来写sql的时候,发现有一些语法会“提笔忘字”,因此在这里做一下系统的笔记整理,以便查阅。
库层
- 创建数据库 :
CREATE DATABASE dbname - 查看数据库 :
show databases - 选择数据库 :
USE dbname - 删除数据库 :
DROP DATABASE dbname
表层
创建表
CREATE TABLE `act_ru_execution` (
-- 列名 列的数据类型 约束条件
`ID_` varchar(64) COLLATE utf8_bin NOT NULL DEFAULT '',
`PROC_INST_ID_` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`BUSINESS_KEY_` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`PARENT_ID_` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`PROC_DEF_ID_` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`SUPER_EXEC_` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`IS_EVENT_SCOPE_` tinyint(4) DEFAULT NULL,
`SUSPENSION_STATE_` int(11) DEFAULT NULL,
`TENANT_ID_` varchar(255) COLLATE utf8_bin DEFAULT '',
`NAME_` varchar(255) COLLATE utf8_bin DEFAULT NULL,
-- 主键
PRIMARY KEY (`ID_`),
-- 索引
KEY `ACT_IDX_EXEC_BUSKEY` (`BUSINESS_KEY_`),
KEY `ACT_FK_EXE_PROCINST` (`PROC_INST_ID_`),
KEY `ACT_FK_EXE_PARENT` (`PARENT_ID_`),
KEY `ACT_FK_EXE_SUPER` (`SUPER_EXEC_`),
KEY `ACT_FK_EXE_PROCDEF` (`PROC_DEF_ID_`),
-- 外键约束
CONSTRAINT `ACT_FK_EXE_PARENT` FOREIGN KEY (`PARENT_ID_`) REFERENCES `act_ru_execution` (`ID_`),
CONSTRAINT `ACT_FK_EXE_PROCDEF` FOREIGN KEY (`PROC_DEF_ID_`) REFERENCES `act_re_procdef` (`ID_`),
CONSTRAINT `ACT_FK_EXE_PROCINST` FOREIGN KEY (`PROC_INST_ID_`) REFERENCES `act_ru_execution` (`ID_`) ON DELETE CASCADE ON UPDATE CASCADE,
CONSTRAINT `ACT_FK_EXE_SUPER` FOREIGN KEY (`SUPER_EXEC_`) REFERENCES `act_ru_execution` (`ID_`)
) ENGINE = InnoDB CHARSET = utf8 COLLATE utf8_bin;
查看表信息
- 查看表定义 :
DESC tablename - 查看创建表的SQL语句 :
SHOW CREATE TABLE tablename
修改表
- 修改表名字 :
ALTER TABLE tablename to tablename1 - 修改表注释 :
ALTER TABLE table comment '注释'
修改/添加表字段
-- 设置字段允许为空,修改字段类型,修改字段注释,修改为自增主键
ALTER TABLE table_name MODIFY COLUMN column_name varchar(255) null (auto_increment) AFTER `(在某个字段名后面)` COMMENT '应用描述' ;
-- 添加字段
ALTER TABLE table_name ADD column_name varchar(255) not null comment '应用访问地址';
-- 添加主键(自增主键)
ALTER TABLE table_name ADD column_name int(5) not null auto_increment ,ADD PRIMARY KEY (column_name);
-- 修改字段名字(要重新指定该字段的类型)
ALTER TABLE table_name CHANGE name app_name varchar(20) not null;
-- 删除字段
ALTER TABLE table_name DROP column_name;
插入记录
INSERT INTO tablename (field1,field2) VALUES (value1,value2),(value1,value2)
更新记录
UPDATE tablename SET field1 = value1,field2 = value2 where id = 1
UPDATE table1,table2 SET table1.field1 = value1,table2.field2 = value2 where table1.id = table2.id
删除记录
DELETE FROM tablename where id = 1
DELETE FROM table1,table2 where table2.id = 1 and table2.id1 = table1.id
查询记录
-- distinct 去重
-- limit 2,10 从第3条开始,显示10条
-- ORDER BY 排序 desc:降序 asc:升序
-- 当order by 混合asc 和desc中,不使用索引
-- 当查询行的关键字与order by中使用的不相同,不使用索引
-- 一堆不同的关键字使用order by,不使用索引
SELECT DISTINCT * FROM tablename where id = 1 ORDER BY time desc LIMIT 2,10
-- group by 聚合,注意会自动的进行排序,如果不需要排序,可以指定order by null
-- WITH ROLLUP 对分类聚合后的结果进行再汇总
-- HAVING 对分类后的结果再进行条件的过滤
SELECT field1 FROM tablename where id = 1 GROUP BY id WITH ROLLUP
SELECT field1 FROM tablename where id = 1 GROUP BY id HAVING count(1) >1
-- 表连接
-- 左连接:包含所有的左边表中的记录甚至是右边表中没有和它匹配的记录
-- 右连接:包含所有的右边表中的记录甚至是左边表中没有和它匹配的记录
SELECT field1,field2 from table1,table2 where table1.field1 = table2.field2
-- 子查询
-- in (not in) 范围查询
-- exists (not exists)
-- = (!=) 单个匹配
SELECT * FROM tablename where field in (SELECT field2 in tablename1)
聚合操作
- 求和:
sum - 计数:
count - 最大值:
max - 最小值:
min
记录联合
-- UNION ALL 把结果集直接合并在一起
-- 将结果进行一次DISTINCT
SELECT * FROM table1
UNION
SELECT * FROM table2
创建索引
-- UNIQUE:唯一索引
-- FULLTEXT:全文索引,只在MyISAM中有
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON table_name(index_field,...)
删除索引
DROP INDEX index_name ON table_name
字段类型
数值类型
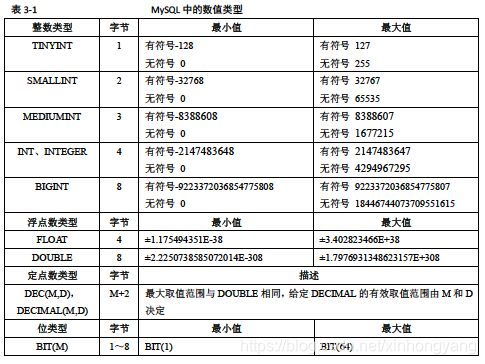
- 精度:在类型后面的小括号内指定显示宽度,表示当数值宽度小于5位的时候在数字前面填满宽度。一般配合zerofill使用,用0填充。
- 无符号:
UNSIGNED - 自增:
AUTO_INCREMENT,应该定义为NOT NULL,并且定义为PRIMARY KEY或者UNIQUE键
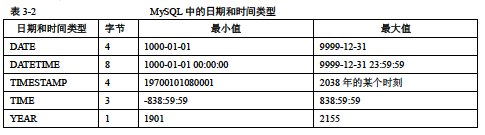
日期时间类型
字符串类型
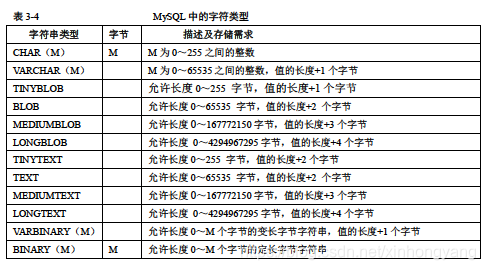
- char:长度固定为创建表时声明的长度,检索时删除空格
- varchar:变长字符串,检索时保留空格,在Mysql5.0以上的版本,按照字符数来进行计算,4.0的是按照字节数进行计算
函数
字符串函数
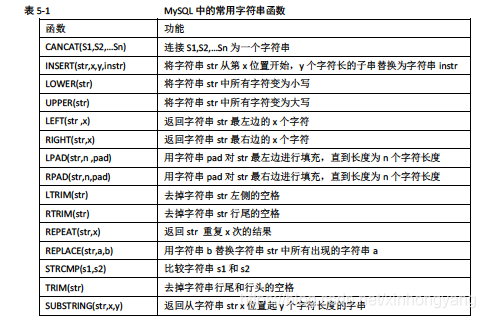
数值函数
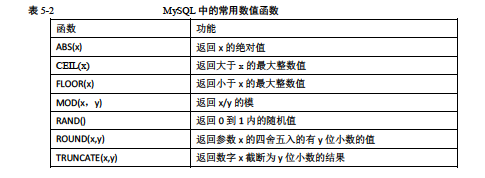
日期和时间函数
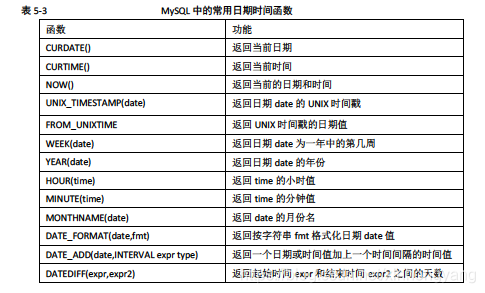
流程函数
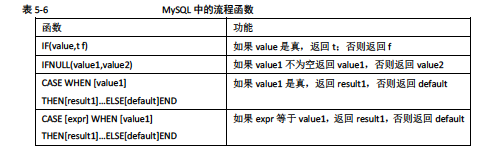
存储引擎
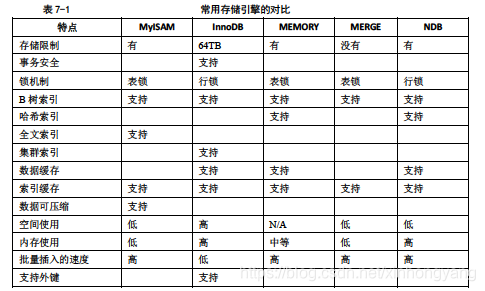
- MyISAM会直接存储总行数,InnoDB则不会,需要按行扫描。(只有查询全表的总行数,MyISAM才会直接返回结果,当加了where条件后,两种存储引擎的处理方式类似。)
- InnoDB务必建好索引,否则锁粒度较大,会影响并发。
- 如果访问没有命中索引,也无法使用行锁,将要退化为表锁。
索引优化
设计索引
- 索引列作为查询关键字
- 索引的列的基数越大,索引的效果越好
- 对字符串列进行索引,尽量使用前缀索引
- 最左前缀规则
- 不要过度索引
Hash索引
- 只能使用
= 或 <=>操作符的等式比较 - 不能加速
ORDER BY操作 - 只能适应整个关键字来搜索一行
BTREE索引
- 支持
>,<,<=,>=,BETWEEN,!=,<>,或者LIKE'pattern'(其中模式不以通配符开始)
使用索引的技巧
- 负向使用
in/exists,无法使用索引。 - 前导模糊查询
%xxx不能使用索引。 - 数据区分度不大的字段不宜使用索引。
- 在属性上进行计算不能命中索引,尽量对值进行计算。
- 如果业务大部分是单条查询,使用Hash索引性能更好,例如用户中心
- 复合索引最左前缀,并不是值SQL语句的where顺序要和复合索引一致
- 如果明确知道只有一条结果返回,limit 1能够提高效率
- 把计算放到业务层而不是数据库层,除了节省数据的CPU,还有意想不到的查询缓存优化效果
- 强制类型转换会全表扫描
- 不要使用
select *
事务
-- 获得该表的READ锁定,其他session更新这张表会等待锁
LOCK TABLE table_name READ
-- 解锁当前session获得的所有表
UNLOCK TABLES
下面是基本的语法
-- 开启事务
START TRANSACTION | BEGIN [WORK]
-- 提交事务
-- CHAIN会立即启动一个新事务,并且和刚才的事务具有相同的隔离性
-- RELEASE会断开和客户端的连接
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
-- 回滚事务
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
-- 修改当前连接的提交方式,为0时,所有事务都需要通过明确的命令进行提交
SET AUTOCOMMIT = {0|1}
如果在锁表期间用start transaction开始一个新事务,会造成一个隐含的unlock tables被执行。

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









