






 本文详细介绍了数据库中的索引类型,包括聚簇索引和非聚簇索引,以及它们各自的特点。聚簇索引依据字段构建B+树,并直接存储数据,而非聚簇索引则存储数据的地址。同时,文章还探讨了不同索引方法,如B-Tree和Hash,分析了Hash索引的优缺点,如快速查找但不适用于范围查询和排序。通过对索引的理解,有助于提升数据库查询效率。
本文详细介绍了数据库中的索引类型,包括聚簇索引和非聚簇索引,以及它们各自的特点。聚簇索引依据字段构建B+树,并直接存储数据,而非聚簇索引则存储数据的地址。同时,文章还探讨了不同索引方法,如B-Tree和Hash,分析了Hash索引的优缺点,如快速查找但不适用于范围查询和排序。通过对索引的理解,有助于提升数据库查询效率。
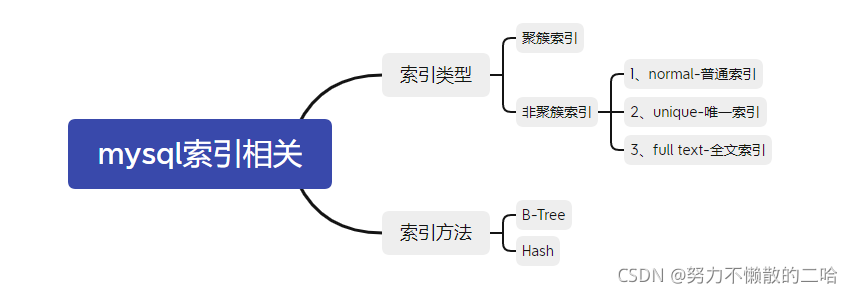
前言:索引的分类上 大致如下图所示
 一、聚簇索引:根据一个字段,构建B+树,在叶子节点存储data数据。
一、聚簇索引:根据一个字段,构建B+树,在叶子节点存储data数据。
选择条件:在索引上,首先选择主键作为索引,然后主键不存在的情况下,选择唯一且不为空的索引作为聚簇索引,最后如果也不存在,则隐式的定义一个主键作为聚簇索引
二、非聚簇索引:同样以字段构建B+树,在叶子节点存储的是数据的地址。
索引类型:
1、normal-普通索引:表示普通索引
2、unique-唯一索引:表示唯一的,不允许重复的索引
3、full text-全文索引:用于搜索长篇的文章时候 效果最好。
索引方法:
1、B-Tree:按InnoDb的结构上理解,就是聚簇索引构建数据源B+树。再通过索引查询 便是辅助索引。查到主键值,再通过主键值 获取到data。
2、Hash:理解上 将索引值构成一个Hash表存储。通过hash表查到行指针,获取行数据。速度比B-Tree快,但是有局限点:
1、仅支持"=","IN"和"<=>"查询,不能使用范围查询。
hash值的计算前后不能保证大小的一致性,无法应用范围查询
2、无法利用此索引做排序操作
3、Hash值的计算是通过整个索引进行计算出的,所以无法单使用前几个索引进行查询
4、无法避免表扫描
5、当大量hash值相等时,速度不一定比B-tree快。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









