




 文章探讨了大模型在人工智能领域的兴起,特别提到书生·浦语开源的大模型系列,涵盖了从数据处理、预训练、微调到部署的全流程,旨在提升开发效率和用户体验,推动通用模型的发展,如通用大模型ChatGPT的原理和实践.
文章探讨了大模型在人工智能领域的兴起,特别提到书生·浦语开源的大模型系列,涵盖了从数据处理、预训练、微调到部署的全流程,旨在提升开发效率和用户体验,推动通用模型的发展,如通用大模型ChatGPT的原理和实践.
大模型正在成为人工智能热门的研究方向
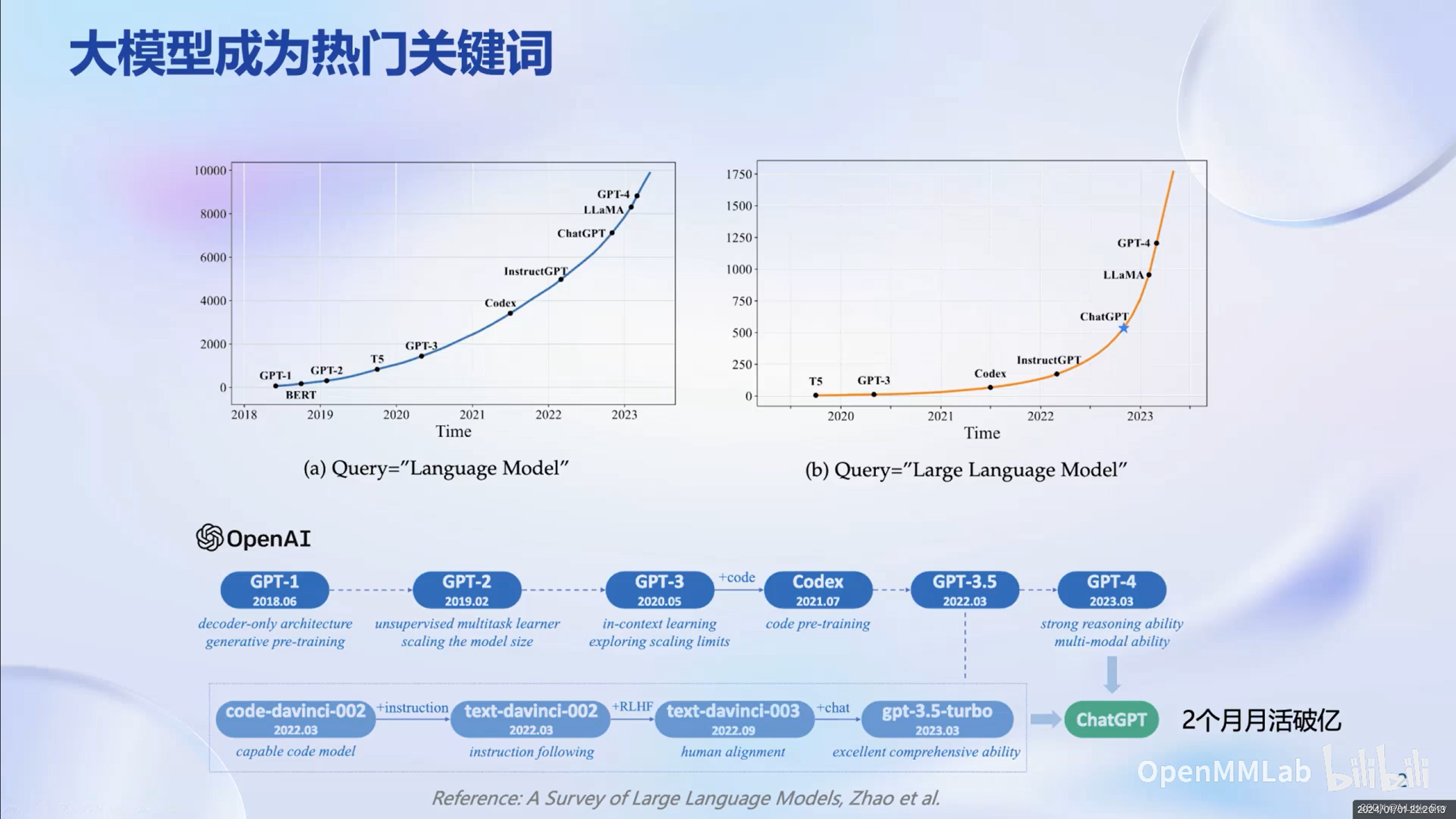
大模型成为发展通用人工智能的重要途径,人工智能正在由专用模型而转向通用模型。
专用模型:针对特定任务,一个模型解决一个问题。
图像分类(CNN)、人脸识别(LFW)、下围棋(AlphaGo)、蛋白质结构预测(AlphaFold)
通用大模型:一个大模型应对多种任务、多种模态(文字、图片、语音、视频等)
ChatGPT
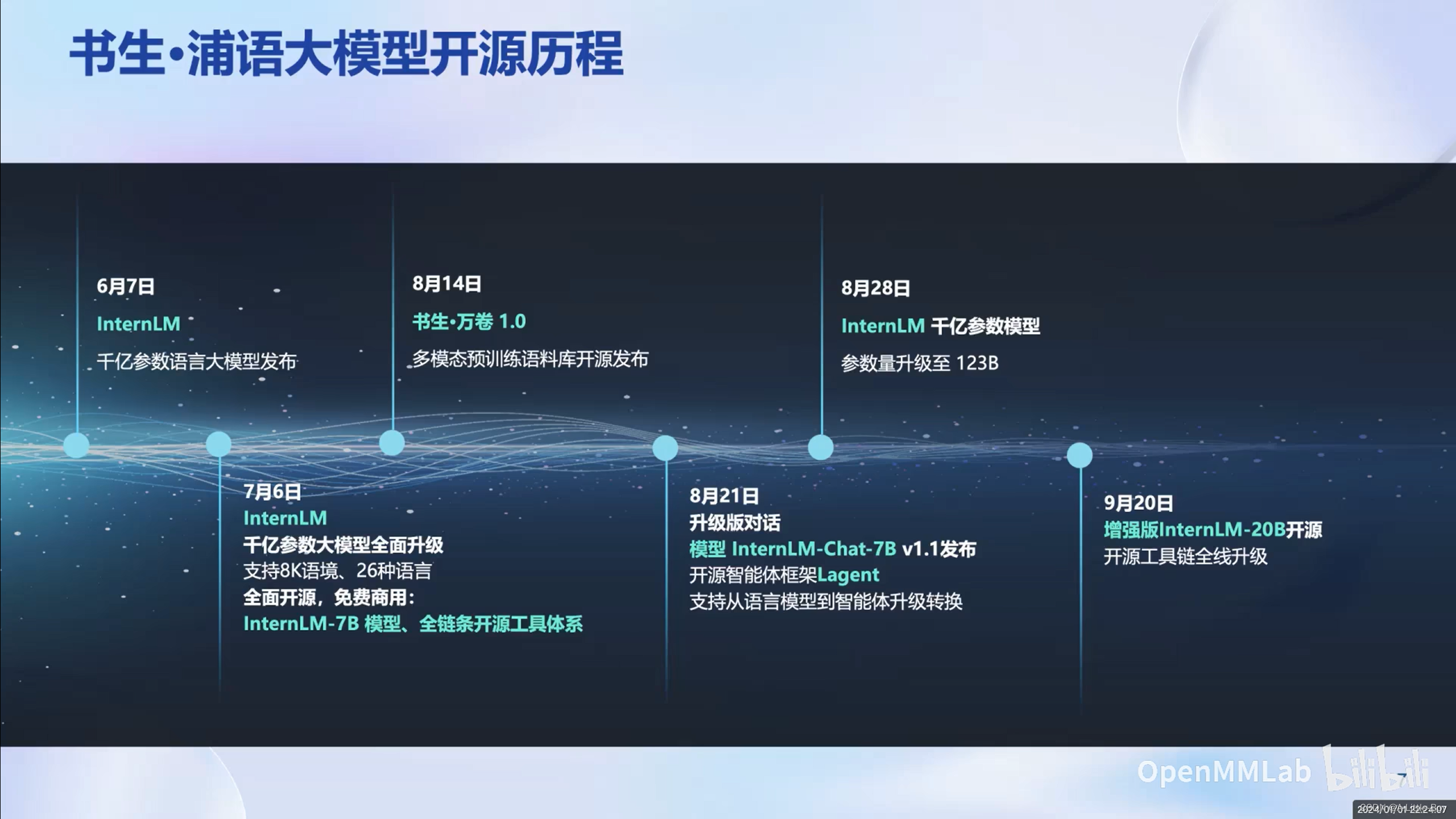
书生·浦语大模型开源历程
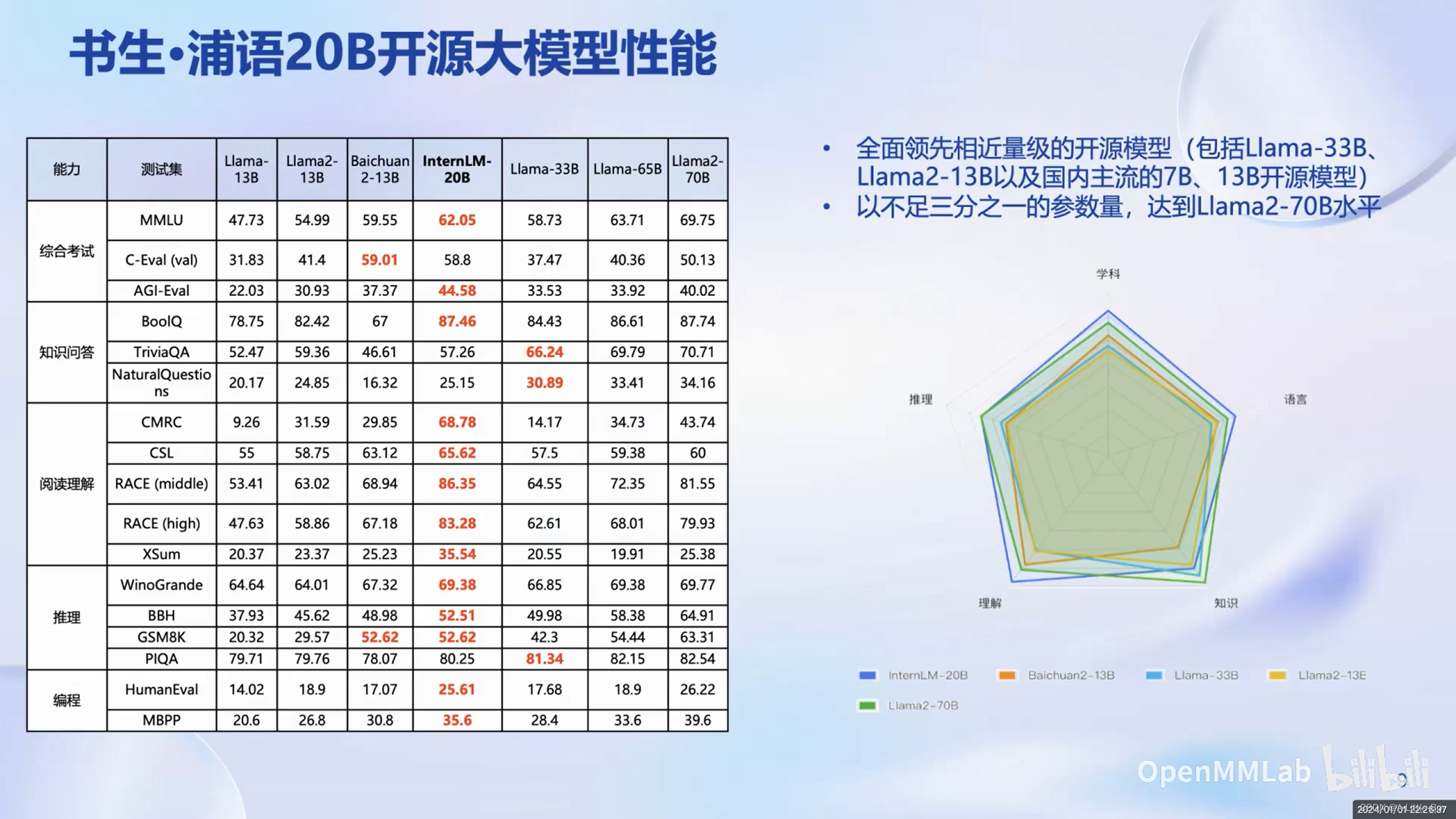
书生·浦语大模型系列提供了轻量级、中量级和重量级三种模型。

书生·浦语开源模型更加轻量化
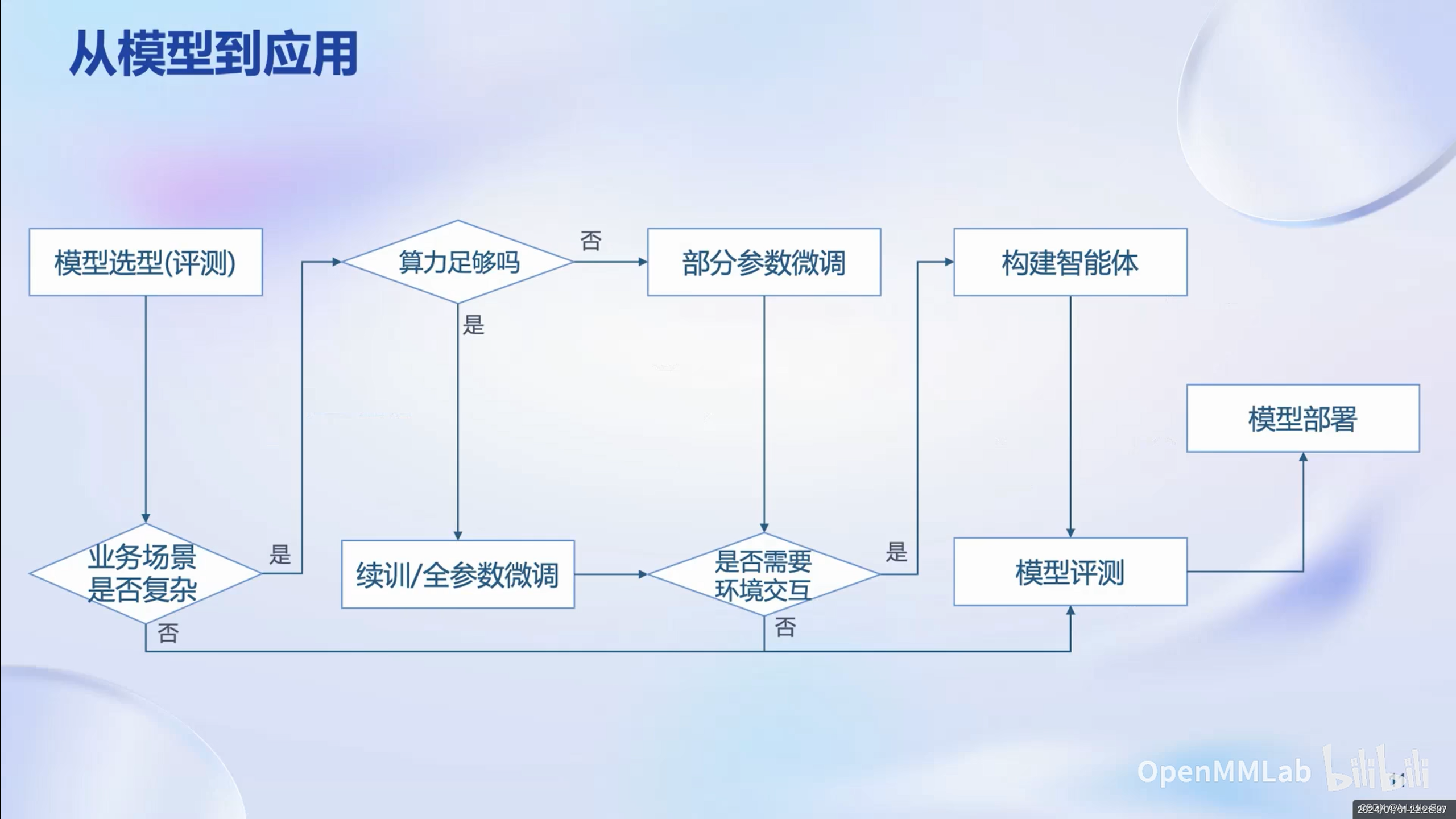
从模型到应用存在GAP

全链条开源开放体系包含数据、预训练、微调、部署、评测和应用

书生·万卷提供了海量的多模态数据


预训练具有高可扩展、极致性能优化、兼容主流和开箱即用等优势

微调:增量续训和有监督微调

高效微调框架XTuner
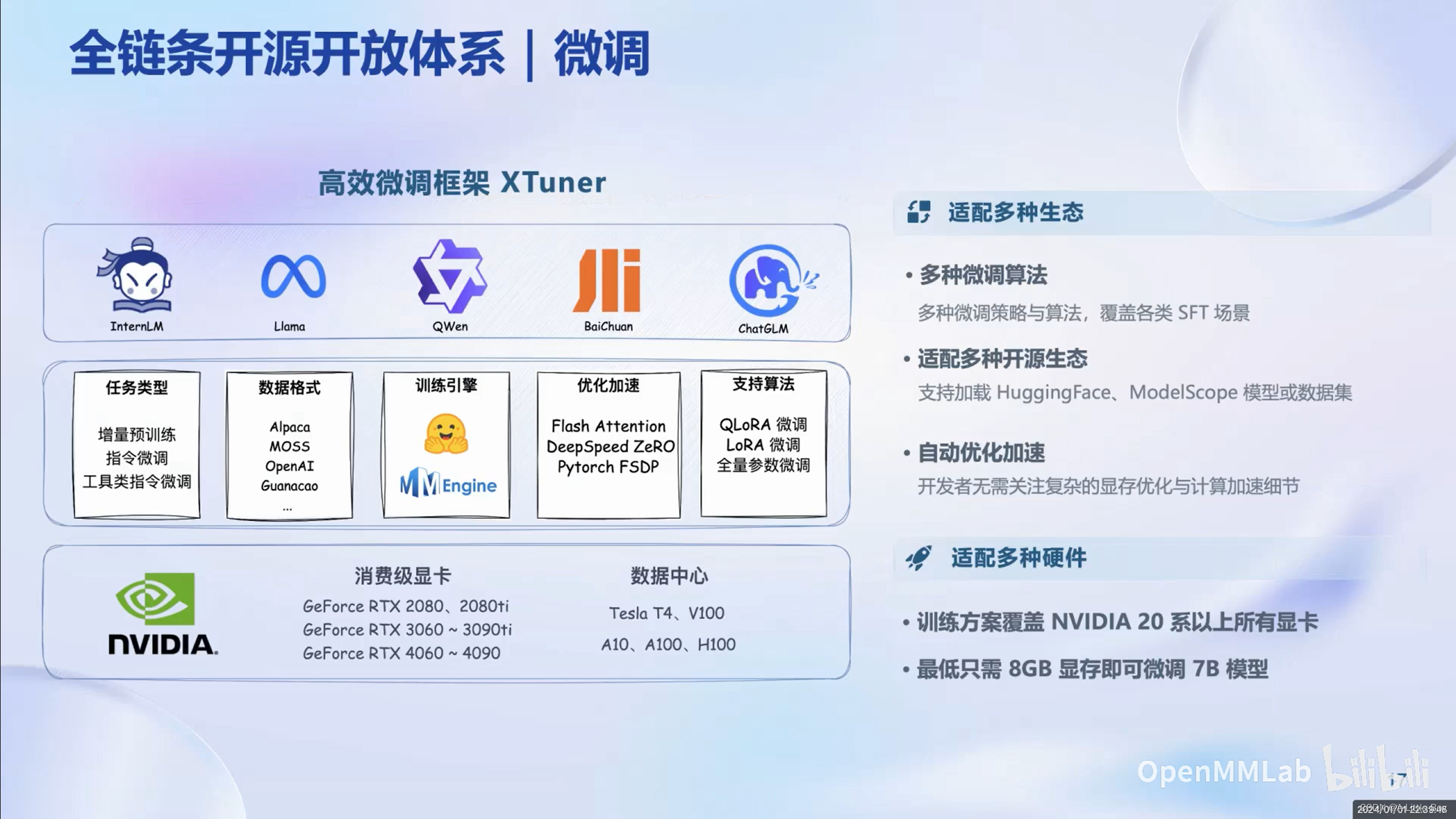
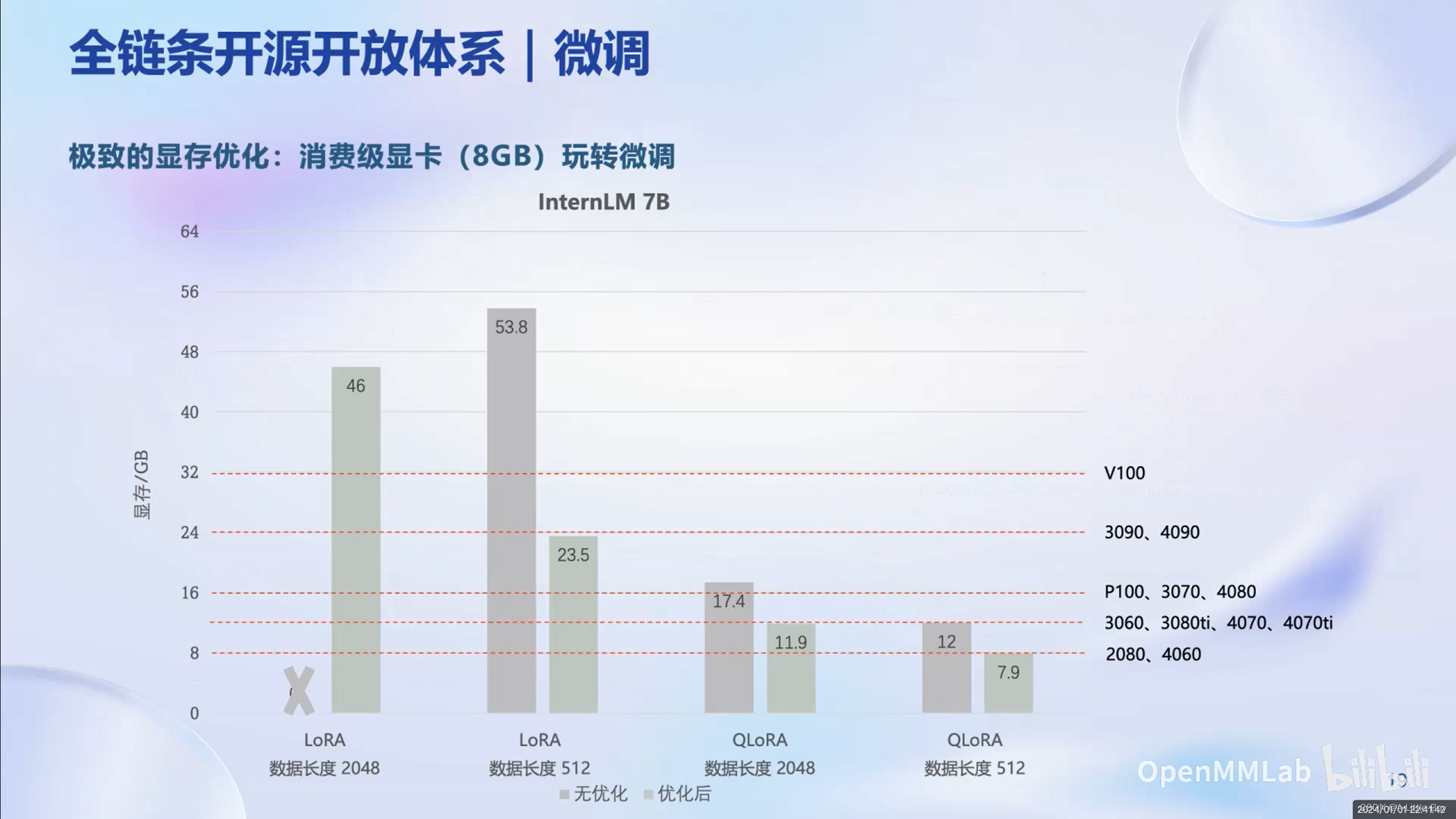
消费级(小显存)显卡一样也能玩转大模型微调
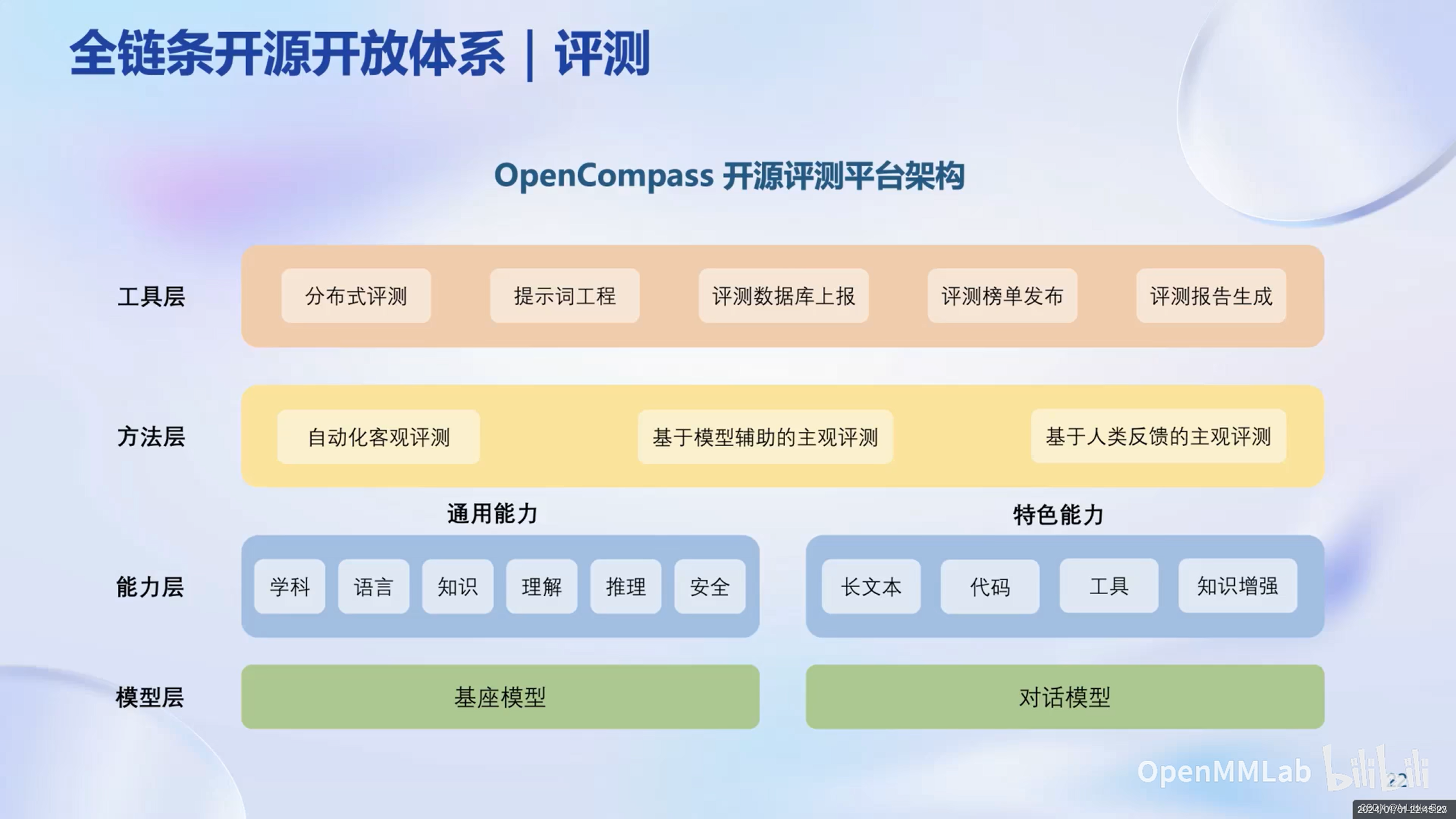
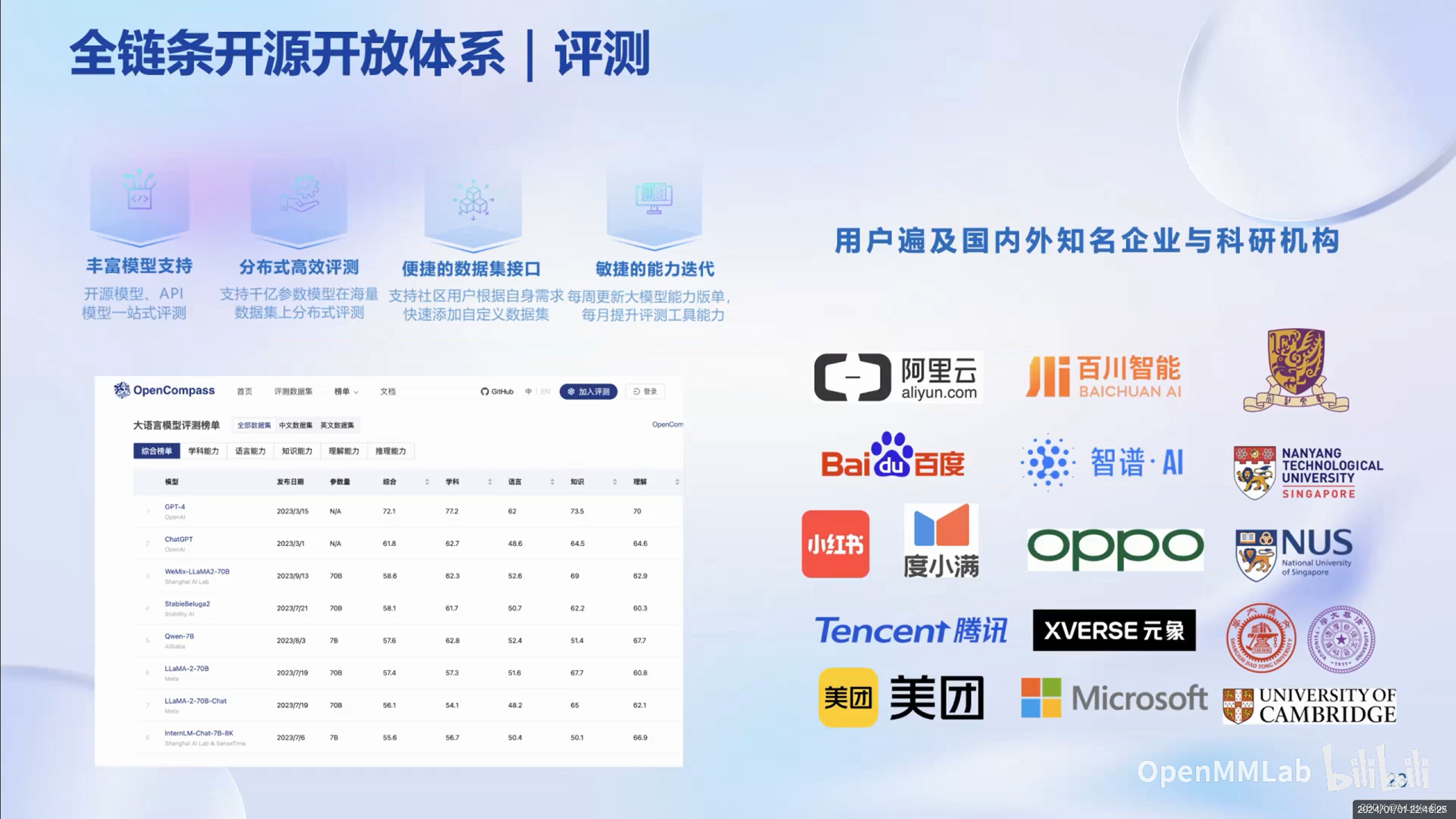
评测

OpenCompass开源评测平台架构的模型层包含基座模型和对话模型
与知名企业以及院校机构合作紧密
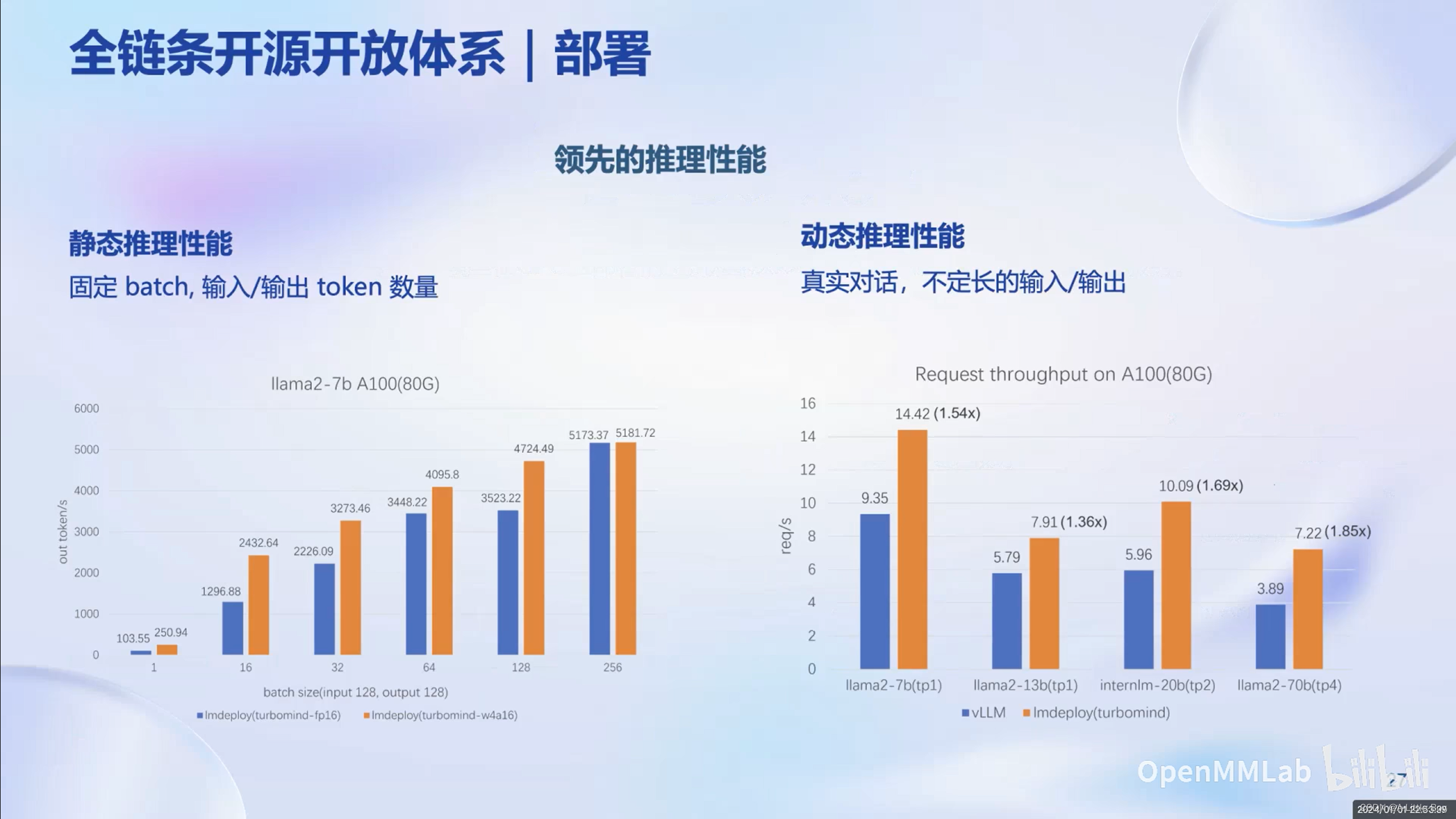
部署

LMDeploy提供了大模型在GPU上部署的全流程解决方案,包括模型的量化、推理和服务。

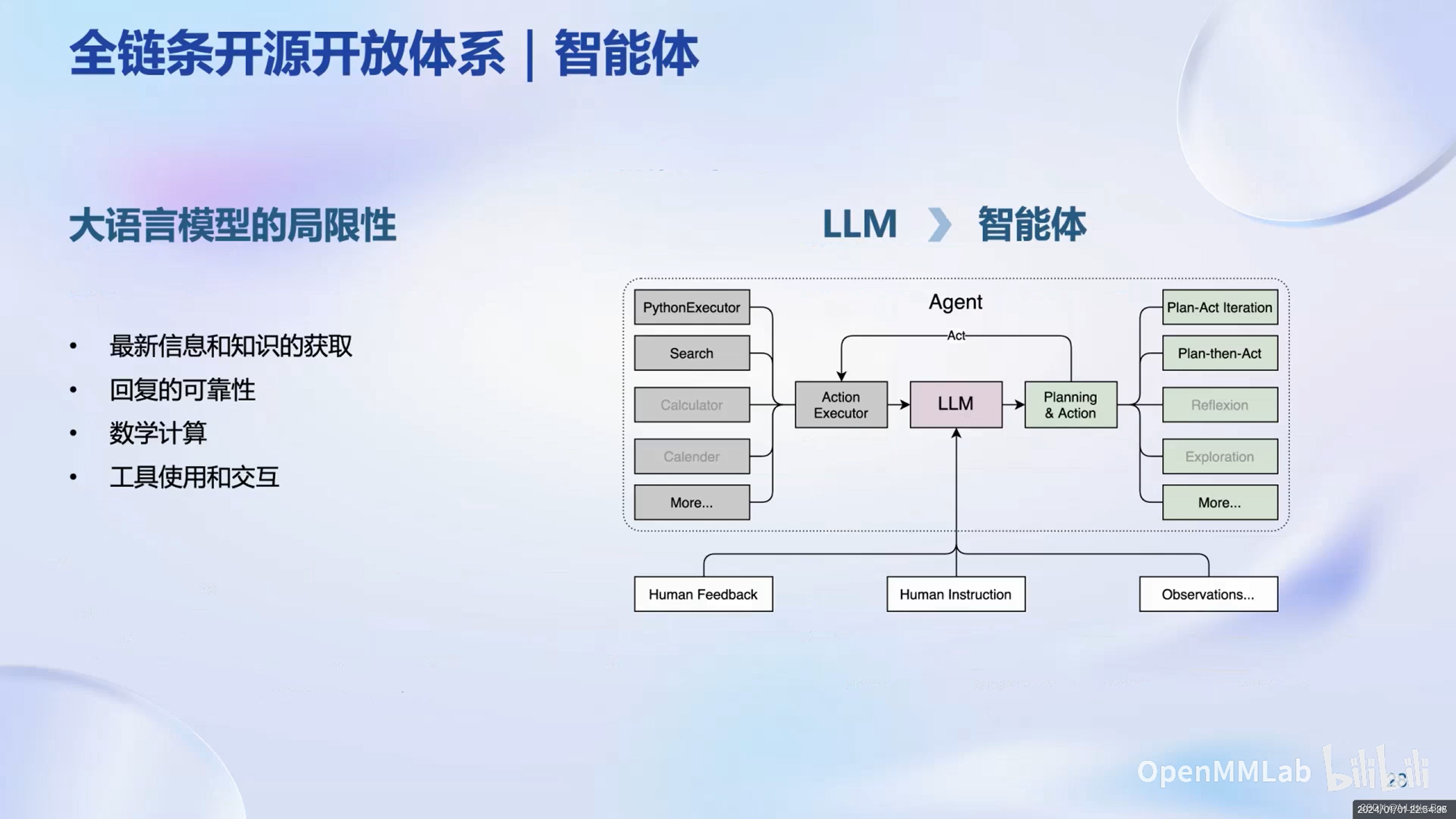
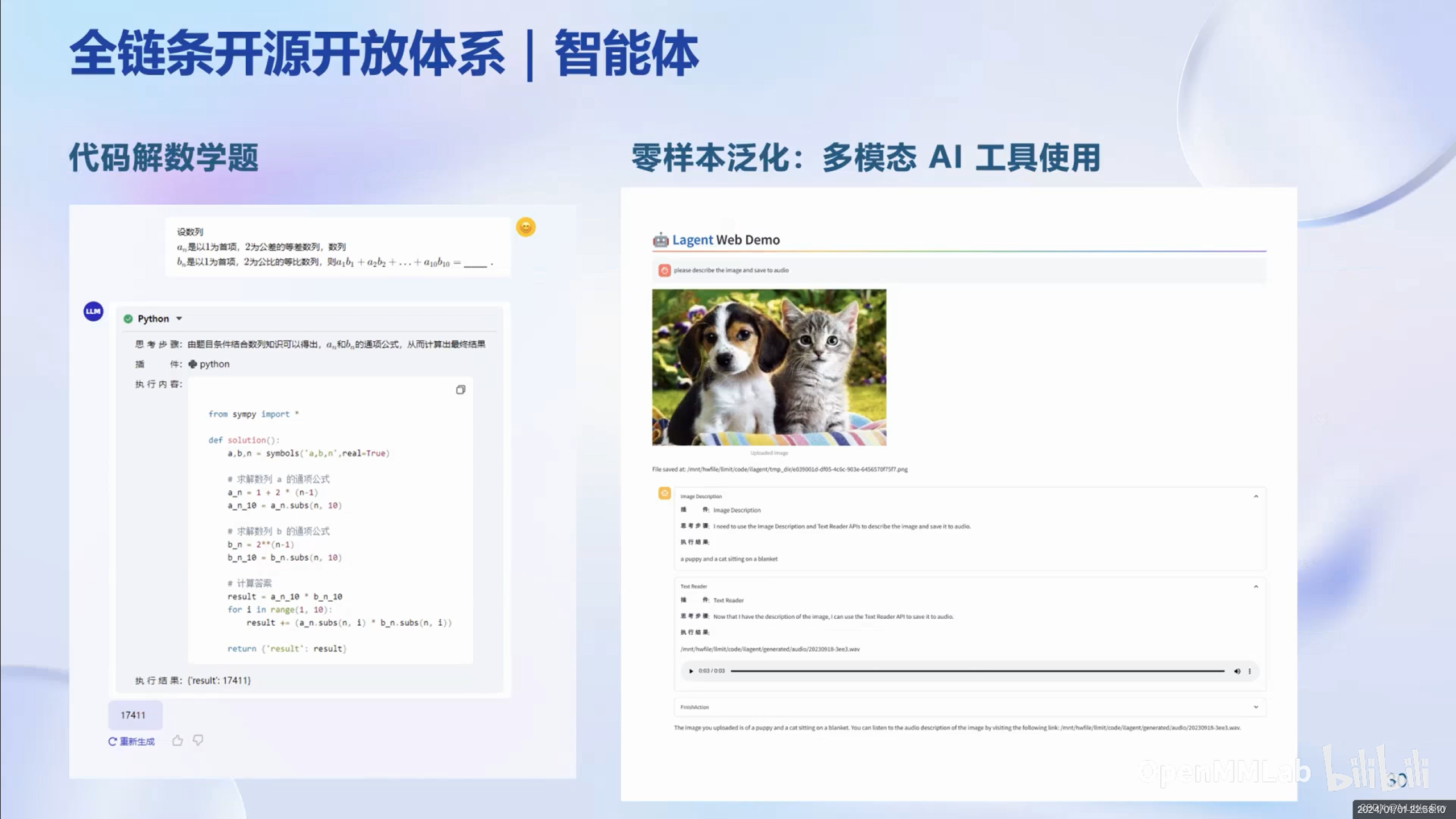
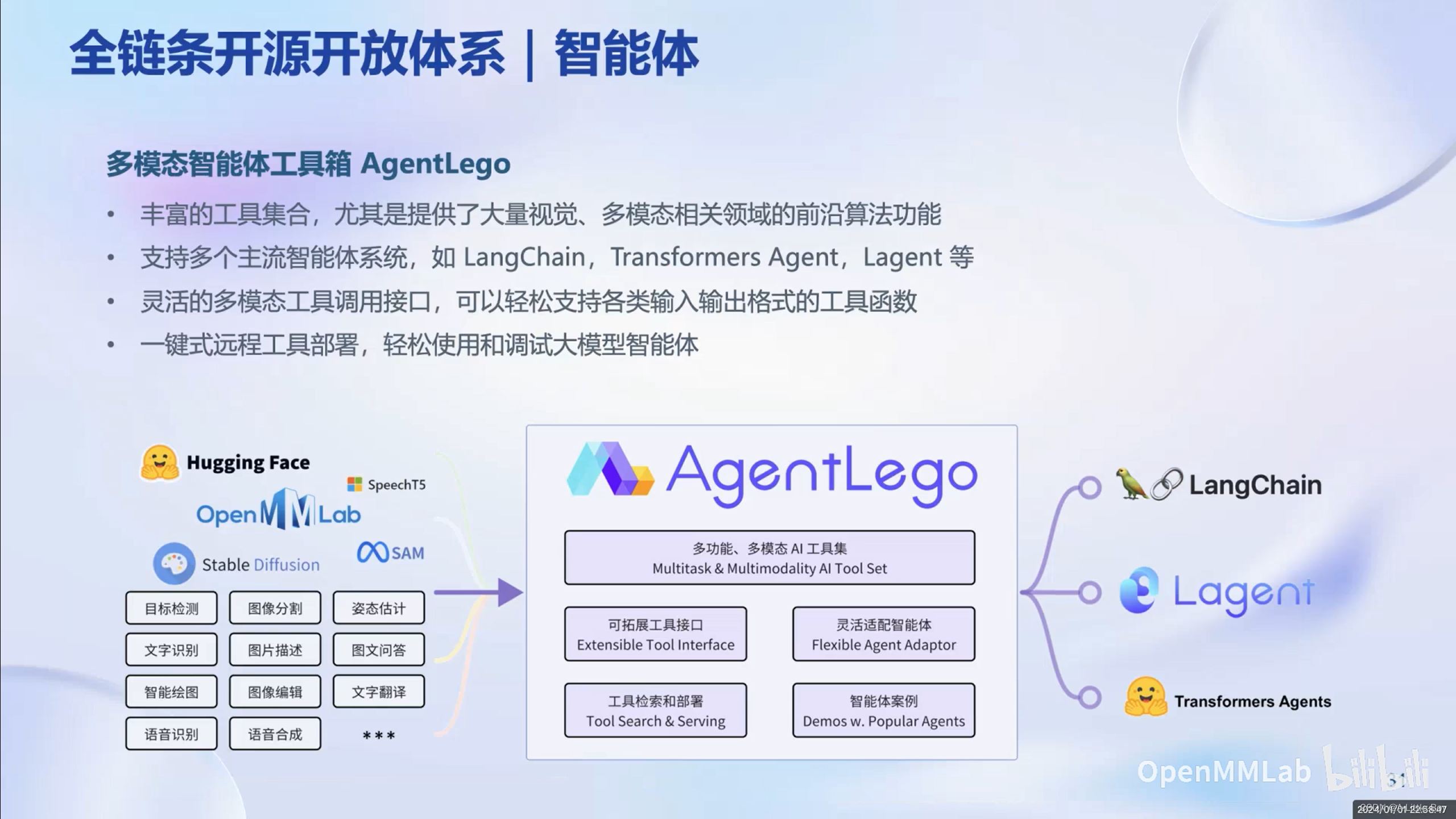
智能体

综述所述,书生·浦语提供了从数据处理到预训练、模型微调、模型部署、模型评测以及应用服务的全链条开源开发体系,覆盖大模型开发者开发大模型的整个流程,极大提高了用户的开发效率和使用体验。


















 2239
2239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









