




异常值检测
应用高斯分布检测异常数据
高斯分布
x服从均值为μ\muμ,方差为σ2σ^2σ2的高斯分布,其概率密度分布图如下:
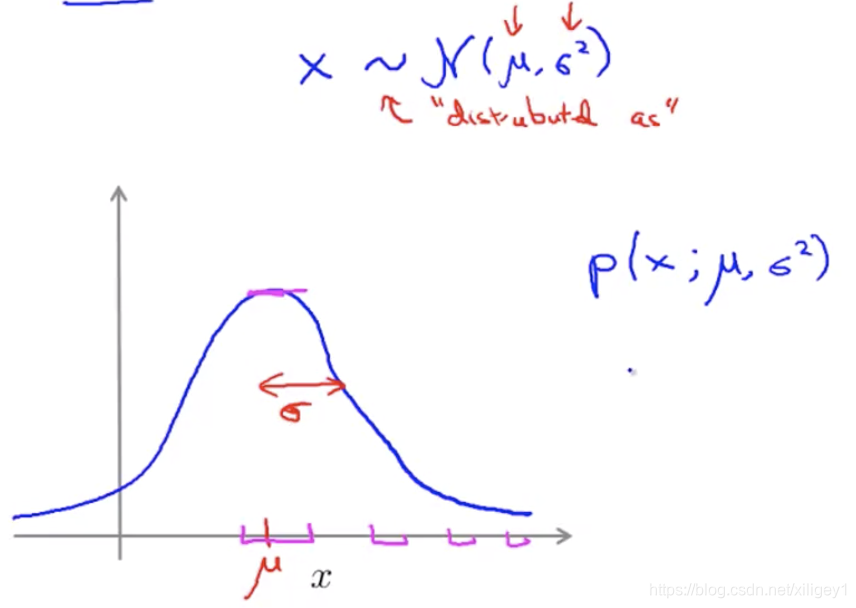
p(x)=12πσexp(−(x−μ)22σ2)p(x)=\frac 1 {\sqrt{2\pi}\sigma}exp(-\frac{(x-\mu)^2}{2σ^2})p(x)=2πσ1exp(−2σ2(x−μ)2)
其中,μ=1m∑i=1mx(i)\mu=\frac 1 m \sum_{i=1}^mx^{(i)}μ=m1∑i=1mx(i)
σ2=1m∑i=1m(x(i)−μ)2\sigma^2=\frac 1 m \sum_{i=1}^m(x^{(i)}-\mu)^2σ2=m1∑i=1m(x(i)−μ)2
算法流程
- 选出哪些你认为可能是异常的特征或者是样本
- 计算出你选择的数据的每个特征的均值和标准差
- 给定一个新的数据xxx,计算p(x)p(x)p(x):
p(x)=∏j=1np(xj;μj,σj2)=∏j=1n12πσjexp(−(xj−μj)22σj2)p(x)=\prod_{j=1}^np(x_j;\mu_j,\sigma_j^2)=\prod_{j=1}^n\frac{1}{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu_j)^2}{2\sigma^2_j})p(x)=j=1∏np(xj;μj,σj2)=j=1∏n2πσj1exp(−2σj2(xj−μj)2)
如果p(x)<ϵp(x)<\epsilonp(x)<ϵ则为异常
如何开发和评价一个异常检测系统
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 yyy 的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
例如:我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
6000台正常引擎的数据作为训练集
2000台正常引擎和10台异常引擎的数据作为交叉检验集
2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
根据测试集数据,我们估计特征的平均值和方差并构建p(x)函数
对交叉检验集,我们尝试使用不同的ϵ\epsilonϵ值作为阀值,并预测数据是否异常,根据F1F_1F1值或者查准率与查全率的比例来选择ϵ\epsilonϵ
选出 ϵ\epsilonϵ 后,针对测试集进行预测,计算异常检验系统的F1F_1F1值,或者查准率与查全率之比
异常检测与监督学习的对比
| 异常检测 | 监督学习 |
|---|---|
| 非常少量的正向类(异常数据 y=1), 大量的负向类(y=0) | 同时有大量的正向类和负向类 |
| 许多不同种类的异常,非常难。根据非常 少量的正向类数据来训练算法。 | 有足够多的正向类实例,足够用于训练 算法,未来遇到的正向类实例可能与训练集中的非常近似。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | |
| 例如: 欺诈行为检测 生产(例如飞机引擎)检测数据中心的计算机运行状况 | 例如:邮件过滤器 天气预报 肿瘤分类 |

















 1318
1318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









