






一、概述
1、什么是Hive
Apache Hive 是一个建立在 Hadoop 之上的数据仓库工具,它允许用户将结构化的数据文件映射为表,并提供类似于 SQL 的查询语言(称为 HiveQL)来进行数据查询和管理。Hive 的主要目标是让数据统计分析更加简单,特别是在处理海量结构化数据时。
2、Hive优缺点
2.1优点
Hive 采用类 SQL 的操作接口,提供了快速开发的能力,使得开发变得简单且容易上手,从而避免了编写复杂的 MapReduce 程序,降低了开发人员的学习成本。由于其较高的执行延迟,Hive 更适合用于对实时性要求不高的数据分析场合,尤其在处理大数据集时表现出色;而对于小数据集,Hive 的高延迟则不具优势。此外,Hive 支持用户自定义函数,允许用户根据自身需求实现特定功能。
2.2缺点
Hive 的 HQL(Hive Query Language)表达能力有限,无法支持迭代式算法和数据挖掘任务。同时,Hive 的执行效率较低,自动生成的 MapReduce 作业往往不够智能化,导致性能优化较为困难且粒度较粗。
3、Hive架构
3.1用户结构
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
3.2元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
默认是存储在derby数据库中,但推荐使用MySQl存储。
3.3Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
3.4驱动器:Driver
3.4.1解析器(SQL Parser)
将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
3.4.2编译器(Physical Plan)
将AST编译生成逻辑执行计划。
3.4.3优化器(Query Optimizer)
对逻辑执行计划进行优化
3.4.4执行器(Exexution)
把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
二、安装
1、内嵌模式
1.1上传解压重命名
我的安装包都在/opt/modules下,解压到/opt/installs下
解压:tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/installs
重命名:cd /opt/installs
mv apache-hive-3.1.2-bin.tar.gz hive
1.2配置环境变量
vi /etc/profile
export HIVE_HOME=/opt/installs/hive
export PATH=$PATH:$HIVE_HOME/bin
配置完成之后记得刷新一下让它生效:
source /etc/profile
1.3修改配置文件
配置hive-env.sh
进入这个文件夹下:/opt/installs/hive/conf
cp hive-env.sh.template hive-env.sh
export HIVE_CONF_DIR=/opt/installs/hive/conf
export JAVA_HOME=/opt/installs/jdk
export HADOOP_HOME=/opt/installs/hadoop
export HIVE_AUX_JARS_PATH=/opt/installs/hive/lib
进入到conf 文件夹下,修改这个文件hive-site.xml
cp hive-default.xml.template hive-site.xml
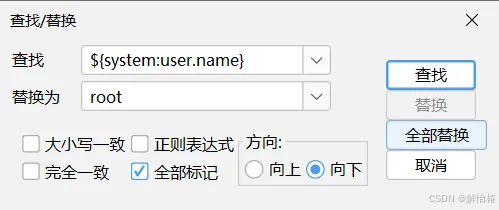
把Hive-site.xml 中所有包含 ${system:java.io.tmpdir} 替换成 /opt/installs/hive/tmp 。如果系统默认没有指定系统用户名,那么要把配置 ${system:user.name} 替换成当前用户名 root 。
可以使用 nodepad++ 打开该文件,进行替换:
一个替换了4处
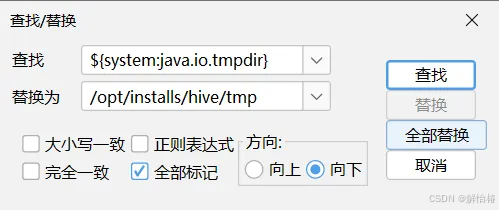
一个替换了3处
1.4在HDFS上创建Hive 的默认仓库目录
启动集群:start-all.sh
给HDFS创建文件夹:
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /tmp/hive/
hdfs dfs -chmod 750 /user/hive/warehouse
hdfs dfs -chmod 777 /tmp/hive
1.5初始化元数据
初始化操作要在hive的家目录执行,因为是内嵌模式,所以使用的数据库是derby
schematool --initSchema -dbType derby
在hive-site.xml中,3215行,96列的地方有一个非法字符

将这个非法字符,删除,保存即可
1.6使用
输入 hive 进入后,可以编写sql
hive> show databases;
OK
default
2、本地模式
使用本地模式的最大特点是:将元数据从derby数据库,变为mysql数据库,并且支持多窗口同时使用。
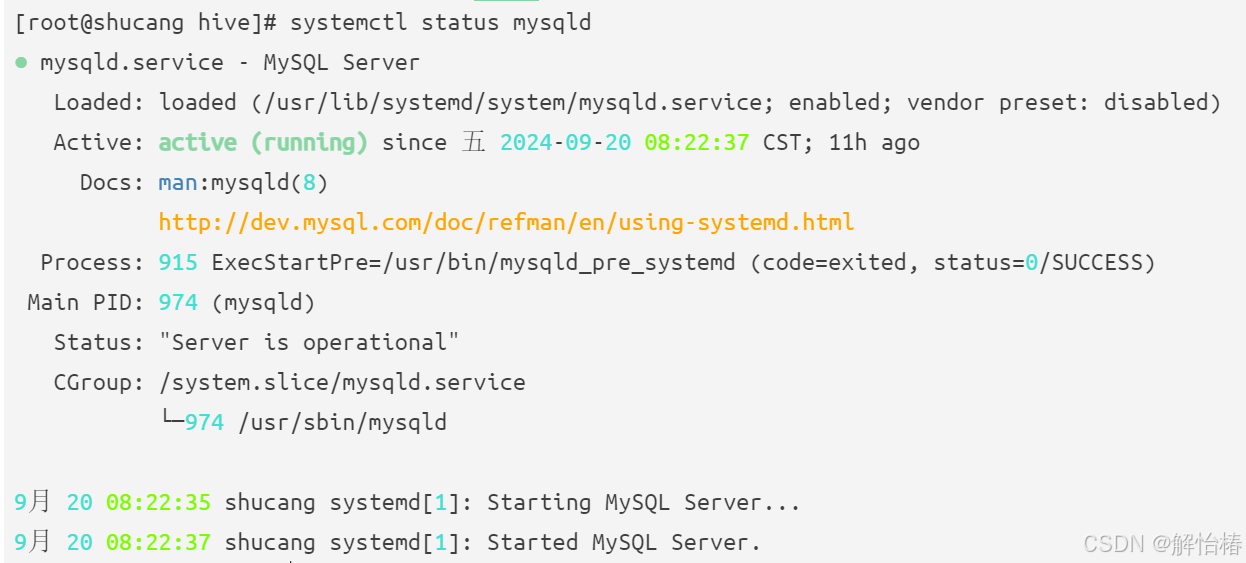
2.1检查mysql是否正常
systemctl status mysqld
2.2删除derby数据库
在hive目录下
rm -rf metastore_db/ derby.log
2.3修改配置文件hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--><configuration><!--配置MySql的连接字符串-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--配置MySql的连接驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--配置登录MySql的用户-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!--配置登录MySql的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<!-- 以下两个不需要修改,只需要了解即可 -->
<!-- 该参数主要指定Hive的数据存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 该参数主要指定Hive的临时文件存储目录 -->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
</configuration>
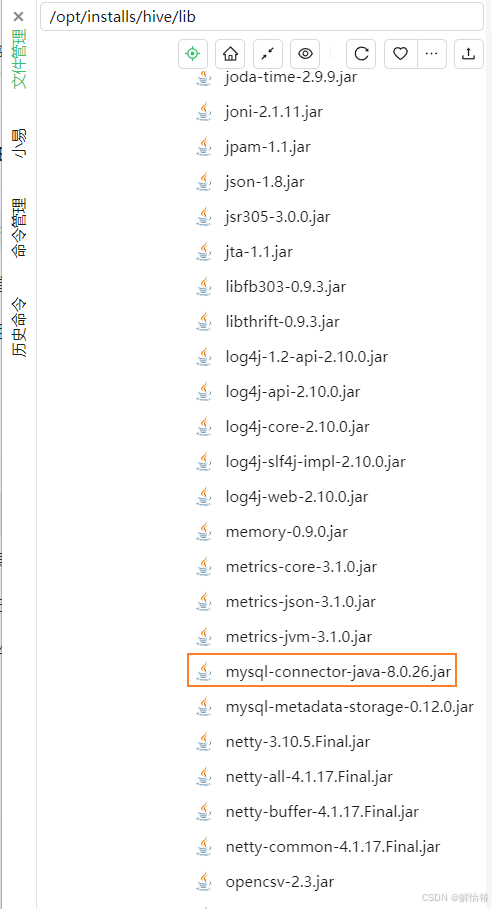
2.4上传mysql驱动包到hive的lib下
2.5初始化元数据
本质就是在mysql中创建数据库,并且添加元数据
schematool --initSchema -dbType mysql
3、远程模式
你想通过DataGrip操作hive,这个时候必须开启远程模式。
3.1创建临时目录
cd /opt/installs/hive/
mkdir iotmp
chmod 777 iotmp
3.2前期准备工作
hive-site.xml,直接粘贴进<configuration></configuration>里面
<!--Hive工作的本地临时存储空间-->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/installs/hive/iotmp/root</value>
</property>
<!--如果启用了日志功能,则存储操作日志的顶级目录-->
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/installs/hive/iotmp/root/operation_logs</value>
</property>
<!--Hive运行时结构化日志文件的位置-->
<property>
<name>hive.querylog.location</name>
<value>/opt/installs/hive/iotmp/root</value>
</property>
<!--用于在远程文件系统中添加资源的临时本地目录-->
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/installs/hive/iotmp/${hive.session.id}_resources</value>
</property>
hive.downloaded.resources.dir:
在 hdfs 上下载的一些资源会被存放在这个目录下,hive 一定要小写,否则报:
cause: java.net.URISyntaxException: Illegal character in path at index 26: /opt/installs/hive/iotmp/${Hive.session.id}_resources/json-serde-1.3.8-jar-with-dependencies.jar
hadoop的core-site.xml,三个集群的都要修改
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 不开启权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
3.3配置hiveserver2服务
hive-site.xml
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bigdata01</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>
1. 该服务端口号默认是10000
2. 可以单独启动此服务进程,供远程客户端连接;此服务内置metastore服务。
3. 启动方式:
方法1:
直接调用hiveserver2。会进入监听状态不退出。
方法2:
hive --service hiveserver2 & # 进入后台启动
方法3:
nohup hive --service hiveserver2 >/dev/null 2>&1 & #信息送入黑洞。
3.4配置metastore 服务
如果直接进入 Hive 操作数据库,底层会自动创建一个名为 ms01 的 Metastore 服务器;而通过 HiveServer2 运行命令时,也会默认创建一个名为 ms02 的 Metastore 服务器,若多人连接同一 MySQL 数据库,将导致多个 Metastore 实例同时运行,消耗大量资源。解决办法是配置一个专用的 Metastore 服务器,让它作为唯一的代理与 MySQL 交互,所有客户端必须通过它来访问 MySQL,从而有效节省内存资源。
只要配置了metastore以后,必须启动,否则报错!
hive-site.xml
注意:想要连接metastore服务的客户端必须配置如下属性和属性值
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata01:9083</value>
</property>解析:thrift:是协议名称
ip为metastore服务所在的主机ip地址
9083是默认端口号
3.5启动
方法1:
hive --service metastore &
方法2:
nohup hive --service metastore 2>&1 >/dev/null & #信息送入黑洞。
解析:2>&1 >/dev/null 意思就是把错误输出2重定向到标准输出1,也就是屏幕,标准输出进了“黑洞”,也就是标准输出进了黑洞,错误输出打印到屏幕。
Linux系统预留可三个文件描述符:0、1和2,他们的意义如下所示:
0——标准输入(stdin)-- System.in
1——标准输出(stdout)--System.out
2——标准错误(stderr) --System.err
3.6一个启动命令
经常启动metastore 以及hiveserver2这两个服务,命令有点长,为了长期使用,可以编写一个命令
cd /usr/local/bin
touch hive-server-manager.sh
#!/bin/bash
# hive 服务控制脚本,可以控制 Hive 的 metastore 和 hiveserver2 服务的启停
# 使用方式: hive-server-manager.sh [start|stop|status] [metastore|hiveserver2]
# - start : 一键开启metastore和hiveserver2服务,也可以指定服务开启
# - stop : 一键停止metastore和hiveserver2服务,也可以指定服务停止
# - status : 一键查看metastore和hiveserver2服务,也可以指定服务查看help_info() {
echo "+---------------------------------------------------------------------------------+"
echo "| 本脚本可以一键控制 Hive 的 metastore 和 hiveserver2 服务 |"
echo "| 使用方式: hive-server-manager.sh [start|stop|status] [metastore|hiveserver2] |"
echo "+---------------------------------------------------------------------------------+"
echo "| 第一个参数用来指定操作命令,可以选择 开始(start)、停止(stop)、状态查看(status) |"
echo "| 第二个参数用来指定操作的服务,可以选择 metastore、hiveserver2,默认为全部 |"
echo "+---------------------------------------------------------------------------------+"
echo "| - start : 一键开启metastore和hiveserver2服务,也可以指定服务开启 |"
echo "| - stop : 一键停止metastore和hiveserver2服务,也可以指定服务停止 |"
echo "| - status : 一键查看metastore和hiveserver2服务,也可以指定服务查看 |"
echo "+---------------------------------------------------------------------------------+"
exit -1
}# 获取操作命令
# 检查进程状态
metastore_pid=`ps aux | grep org.apache.hadoop.hive.metastore.HiveMetaStore | grep -v grep | awk '{print $2}'`
hiveserver2_pid=`ps aux | grep proc_hiveserver2 | grep -v grep | awk '{print $2}'`# 检查日志文件夹的存在情况,如果不存在则创建这个文件夹
log_dir=/var/log/my_hive_log
if [ ! -e $log_dir ]; then
mkdir -p $log_dir
fi
# 开启服务
start_metastore() {
# 检查是否开启,如果未开启,则开启 metastore 服务
if [ $metastore_pid ]; then
echo "metastore 服务已经开启,进程号: $metastore_pid,已跳过"
else
nohup hive --service metastore >> $log_dir/metastore.log 2>&1 &
echo "metastore 服务已经开启,日志输出在 $log_dir/metastore.log"
fi
}
start_hiveserver2() {
# 检查是否开启,如果未开启,则开启 hiveserver2 服务
if [ $hiveserver2_pid ]; then
echo "hiveserver2 服务已经开启,进程号: $hiveserver2_pid,已跳过"
else
nohup hive --service hiveserver2 >> $log_dir/hiveserver2.log 2>&1 &
echo "hiveserver2 服务已经开启,日志输出在 $log_dir/hiveserver2.log"
fi
}# 停止服务
stop_metastore() {
if [ $metastore_pid ]; then
kill -9 $metastore_pid
fi
echo "metastore 服务已停止"
}
stop_hiveserver2() {
if [ $hiveserver2_pid ]; then
kill -9 $hiveserver2_pid
fi
echo "hiveserver2 服务已停止"
}# 查询服务
status_metastore() {
if [ $metastore_pid ]; then
echo "metastore 服务已开启,进程号: $metastore_pid"
else
echo "metastore 服务未开启"
fi
}
status_hiveserver2() {
if [ $hiveserver2_pid ]; then
echo "hiveserver2 服务已开启,进程号: $hiveserver2_pid"
else
echo "hiveserver2 服务未开启"
fi
}# 控制操作
if [ ! $server ]; then
${op}_metastore
${op}_hiveserver2
elif [ $server == "metastore" ]; then
${op}_metastore
elif [ $server == "hiveserver2" ]; then
${op}_hiveserver2
else
echo "服务选择错误"
help_info
fi
chmod u+x hive-server-manager.sh

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









