






 博主分享了从初学者角度遇到的链表创建与节点删除问题,重点在于理解节点空置对遍历的影响,并提供了优化后的代码示例。通过自定义函数简化链表操作,讨论了正确遍历链表的方法和空置节点的处理策略。
博主分享了从初学者角度遇到的链表创建与节点删除问题,重点在于理解节点空置对遍历的影响,并提供了优化后的代码示例。通过自定义函数简化链表操作,讨论了正确遍历链表的方法和空置节点的处理策略。
题目链接:[编程入门]链表之节点删除 - C语言网 (dotcpp.com)
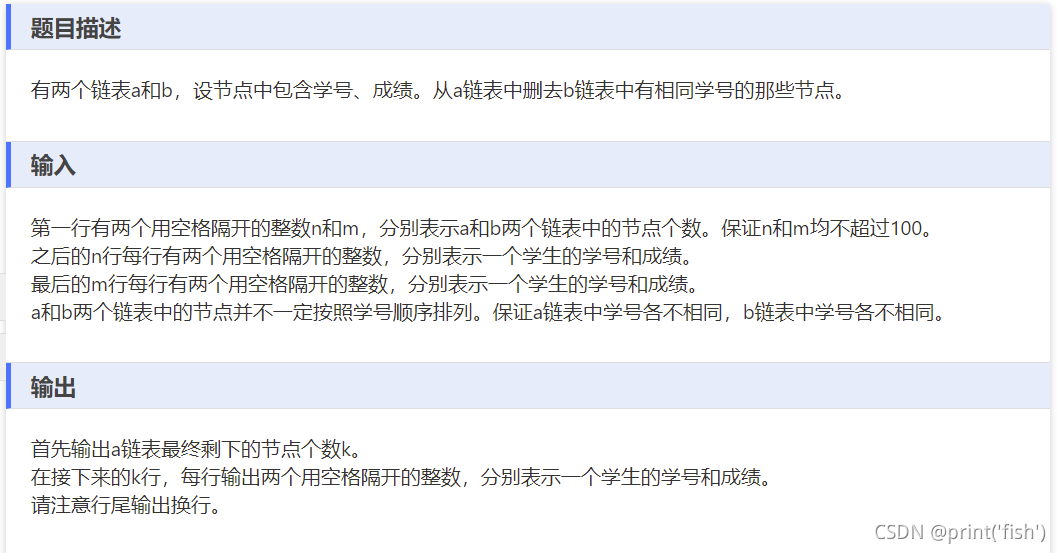
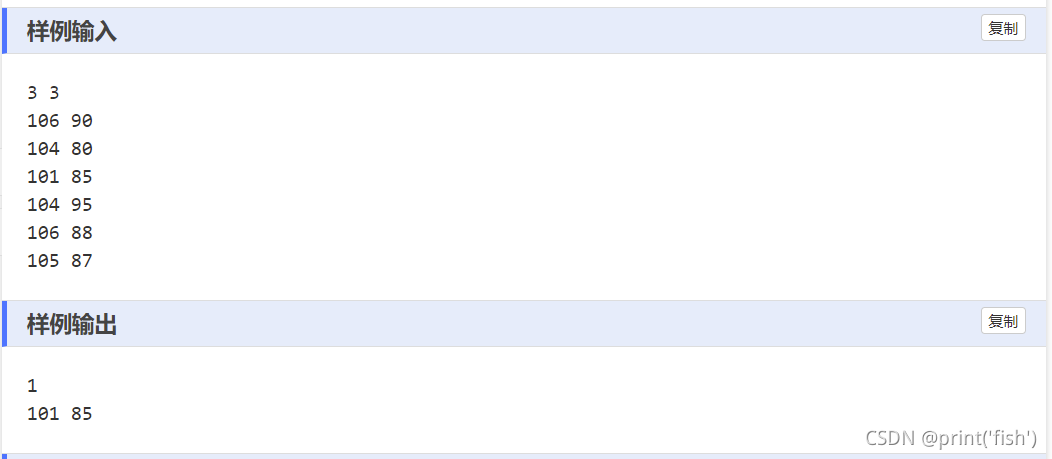
额,确实,这个题目是比较简单的,其实我没有必要写那么多出来的,但是我就是想将自己再做题的思考过程尽量的写出来,但是后面发现没有一定的文笔,连自己做题时确切的感受都些不出来,有点难受,但是还是尽量的写出来了,希望读者能看的懂我的思考过程吧.......
简单的说一下我遇到的主要问题:创建链表不够熟练,没有考虑要将头节点空置(及开辟了一个空间,没有将数据输进去)。
下面是对这两个问题的详细解释:
一开始我是这样创建链表的:
#include<iostream>
#include<cstdlib>
using namespace std;
typedef struct Node1 {
int id, grade;
struct Node1* next;
}node1;
typedef struct Node2 {
int id, grade;
struct Node2* next;
}node2;
int main() {
int n, m;
cin >> n >> m;
node1* head1 = (node1*)malloc(sizeof(node1));
head1->next = NULL;
node1* p = head1;
for (int i = 0; i < n; i++) {
cin >> p->id >> p->grade;
p->next = (node1*)malloc(sizeof(node1));
p = p->next;
p->next = NULL;
}
node2* head2 = (node2*)malloc(sizeof(node2));
head2->next = NULL;
node2* q = head2;
for (int i = 0; i < m; i++) {
cin >> q->id >> q->grade;
q->next = (node2*)malloc(sizeof(node2));
q = q->next;
q->next = NULL;
}
//最后来进行打印一下前一个链表中的元素,查看是否创建成功
p=head1;
while(p->next!=NULL){
cout<<p->id<<" "<<p->grade<<endl;
p=p->next;
}
return 0;
}
是的,我定义了两遍,这代码一看都要头疼啊!于是我又去看了下别人的代码,发现可以进行优化,没有必要定义两个链表结构,而且存在大量的重复代码,这可以用自定义函数来解决(解决重复的创建链表问题)。下面是优化代码:
#include<iostream>
#include<cstdlib>
using namespace std;
typedef struct student {
int id, grade;
struct student* next;
}node;
node* create(int n) {
node* head = (node*)malloc(sizeof(node));
head->next = NULL;
node* p = head;
for (int i = 0; i < n; i++) {
cin >> p->id >> p->grade;
p->next = (node*)malloc(sizeof(node));
p = p->next;
p->next = NULL;
}
return head;
}
void print(node* p) {
while (p ->next!= NULL) {
cout << p->id << " " << p->grade << endl;
p = p->next;
}
}
int main() {
int n, m;
cin >> n >> m;
node* a, * b;
a = create(n); b = create(m);
print(a);//输出查看连链表
return 0;
}这样方便了很多。
接下来我就发现:
为什么要这样遍历链表:
while(p->next!=NULL){}而不是:
while(p!=NULL){}因为之前学链表是为了对付课设,没有将链表搞得太清楚(就是我太菜了!)。所以我还是这样创建链表。然后这样创建链表:对单个链表来说,其实我创建了n+1个节点,第1~n个节点都存这数据,而第n+1个节点虽然开出了一个空间,但是其实里面是没有数据的(节点没有数据和NULL是不一样的)
所以,当我这样进行输出的时候:
while (p != NULL) {
cout << p->id << " " << p->grade << endl;
p = p->next;
}
就会有这样的结果:
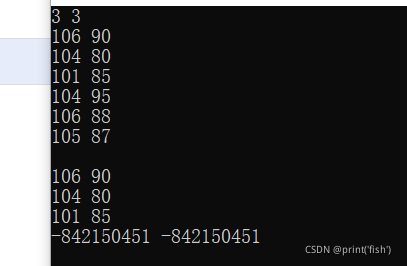
最后面一行一两个负数,说明这一节点其实是没有数据的。
所以,后面用这样的创建链表方式解题的时候,就会导致遍历链表不能遍历完全(少遍历了头节点)。
拿着怎么办呢?
将这个空置的节点换成头节点,这样就可以完全的遍历并删掉节点了。
下面给出两种代码,一种是没有使用自定义函数的,一种是使用自定义函数的(当然是用函数的代码看起来比较舒服了!)
没用自定义函数的(没有注释,自定义的代码有注释):
#include<iostream>
#include<cstdlib>
using namespace std;
typedef struct student {
int id, grade;
struct student* next;
}node;
int main() {
int n, m;
cin >> n >> m;
node* a, * b;
node* head1 = (node*)malloc(sizeof(node));
head1->next = NULL;
node* s = head1;
for (int i = 0; i < n; i++) {
node* p = (node*)malloc(sizeof(node));
cin >> p->id >> p->grade;
s->next = p;
p->next = NULL;
s = p;
}
a = head1;
node* head2 = (node*)malloc(sizeof(node));
head2->next = NULL;
node* l = head2;
for (int i = 0; i < m; i++) {
node *p= (node*)malloc(sizeof(node));
cin >> p->id >> p->grade;
l->next = p;
p->next = NULL;
l = p;
}
b = head2;
node* s1 = head1;
node* p = head1->next;
while (p != NULL) {
node* q = head2->next;
while (q != NULL) {
if (p->id == q->id) {
n--;
s1->next = p->next;
free(p);
p = s1;
break;
}
q = q->next;
}
s1 = p;
p = s1->next;
}
cout << n << endl;
if (n == 0)return 0;
a = head1->next;
while (a != NULL) {
cout << a->id << " " << a->grade << endl;
a = a->next;
}
return 0;
}用函数的:
#include<iostream>
#include<cstdlib>
using namespace std;
typedef struct student {//定义结构体
int id, grade;
struct student* next;
}node;
node* create(int n) {//创建链表
node* head = (node*)malloc(sizeof(node));
head->next = NULL;
node* s = head;
for (int i = 0; i < n; i++) {
node* p = (node*)malloc(sizeof(node));
cin >> p->id >> p->grade;
s->next = p;
p->next = NULL;
s = p;
}
return head;
}
void print(node* L) {//输出链表
node* p = L->next;//头节点不带数据,跳过
while (p != NULL) {
cout << p->id << " " << p->grade << endl;
p = p->next;
}
}
int lenth(node* L) {//计算链表中存有数据的节点数
node* p = L->next;//头节点不带数据,跳过
int n = 0;
while (p != NULL) {
n++;
p = p->next;
}
return n;
}
node* delnode(node* a, node* b) {
node* p = a->next, * s = a;//删除一个节点需要知道这个节点的前一个节点
while (p != NULL) {//这里用结构体指针s来表示p的前一个节点
node* q = b->next;
while (q != NULL) {
if (p->id == q->id) {
node* l = p->next;
s->next = p->next;
free(p);//释放p指向的节点的空间,并不是p就没有了,p是指针,还是存在的
p = s;//确保数据删除之后的后续删除还可以进行
break;//删掉数据后就是可以直接退出这一重循环了
}
q = q->next;
}
s = p;//确保s指向的节点始终在p的前一个
p = s->next;
}
return a;
}
int main() {
int n, m;
cin >> n >> m;
node* a, * b;
a = create(n); b = create(m);//创建链表
a=delnode(a, b);//删除相同数据
cout << lenth(a) << endl;//计算删除数据后的节点数(带数据的节点)
if (lenth(a) == 0)return 0;//如果删除数据后没有有效节点了,直接结束程序
print(a);
return 0;
}。。。。。。。
写完了之后感觉是在浪费时间,估计没有人会看这么繁琐的题解,还说的不清不楚。
要是看了不理解的话可以评论提问,我看到了会回的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











