







之前做的一个资金业务专门有个服务在内存中进行用户余额计算,然后通过kafka消息将计算结果异步的同步到数据库中。为了给用户显示余额的正确性,之前的设计严格的保证了处理的顺序性。
为了严格有序,kafka使用的是单分区。同时,为了实现kafka顺序消费,在消费端使用zookeeper的leader选举逻辑实现只有一个节点在消费消息,然后持久化到数据库。
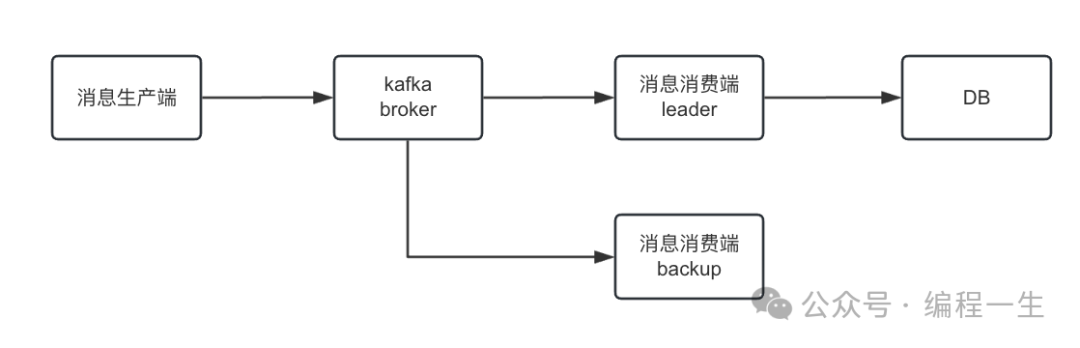
这个实现存在两个严重问题:使用单分区,一旦业务量上升kakfa的吞吐量却上不去,存在严重性能瓶颈无法通过扩分区解决。消费端采用主备模式,在进行重启等操作时会触发主备切换。借助zookeeper选主的过程很慢,测试发现要几分钟才能选举成功,这个过程中消息会积压。消费端因为采用了自动提交模式,每次都消费一批放到内存队列慢慢处理,会丢失消息,需要在部署时检查是否需要手动重放消息。
为了解决系统的扩展性问题和重启时手动运维的问题,我们进行了重新设计升级。
我之前也说过,系统优化亦或是性能优化,首先要做的是充分理解业务。
通过业务梳理发现:从本质上来看,我们的业务并不需要严格的顺序消费,只需要保证每个用户的余额新数据不被旧数据覆盖。因为kafka有offset等字段,针对每个用户余额也有相应的版本号。可以知道哪是新数据,哪是旧数据。所以做方案阶段,我们的方案是采用redis分布式锁,锁粒度为单个用户的余额。有数据更新时&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









