







 本文介绍如何使用TextCNN模型进行文本分类,通过Word2Vec预训练词向量并结合LSTM和CNN实现句子表示,展示了从数据预处理到模型训练和评估的全过程。
本文介绍如何使用TextCNN模型进行文本分类,通过Word2Vec预训练词向量并结合LSTM和CNN实现句子表示,展示了从数据预处理到模型训练和评估的全过程。
参考:https://blog.youkuaiyun.com/Kaiyuan_sjtu/article/details/84536256
import numpy as np
import gensim
from sklearn import metrics
import keras
from keras.preprocessing import sequence
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Activation, concatenate
from keras.layers import Embedding, Input, MaxPooling1D, Flatten, LSTM, Lambda, Conv1D, GlobalMaxPooling1D
from keras.datasets import imdb
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
import pandas as pd
import jieba
import pkuseg
import re
from keras.preprocessing.sequence import pad_sequences
from gensim.models import KeyedVectors
from gensim.models import word2vec
from keras.preprocessing.text import Tokenizer
import tensorflow as tf
import keras.backend.tensorflow_backend as KTF
from keras.models import load_model
import joblib
from sklearn.model_selection import GridSearchCV
from keras.wrappers.scikit_learn import KerasClassifier
KTF.set_session(tf.Session(config=tf.ConfigProto(device_count={'gpu': 0})))
# 构建TextCNN模型,模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
def TextRCNN_model(maxlen, max_features, embedding_dims, class_num, embedding_weights, activation):
# input 层
input_current = Input(shape=(maxlen,), dtype='float64')
input_left = Input(shape=(maxlen,), dtype='float64')
input_right = Input(shape=(maxlen,), dtype='float64')
# embedding 层
embedding = Embedding(max_features + 1, embedding_dims, input_length=maxlen, weights=[embedding_weights])
embedding_current = embedding(input_current)
embedding_left = embedding(input_left)
embedding_right = embedding(input_right)
# RNN 层
forward_rnn = LSTM(128, return_sequences=True)
backward_rnn = LSTM(128, return_sequences=True, go_backwards=True)
reverse = Lambda(lambda x: tf.reverse(x, axis=[1]))
x_left = forward_rnn(embedding_left)
x_right = backward_rnn(embedding_right)
x_right = reverse(x_right)
# CNN Conv 卷积层
conv = Conv1D(64, kernel_size=1, activation='tanh')
x = concatenate([x_left, embedding_current, x_right])
x = conv(x)
# CNN max_pooling 池化层
max_pooling = GlobalMaxPooling1D()
x = max_pooling(x)
# 全连接层
classifier = Dense(class_num, activation=activation)
output = classifier(x)
model = Model(inputs=[input_current, input_left, input_right], outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
word2vec = gensim.models.Word2Vec.load("../model/word2vec.model")
max_features = word2vec.syn1.shape[0]
maxlen = 256
embedding_dims = word2vec.syn1.shape[1]
# We add an additional row of zeros to the embeddings matrix to represent unseen words and the NULL token.
embedding_weights = np.zeros((word2vec.syn1.shape[0] + 1, word2vec.syn1.shape[1]), dtype="float32")
embedding_weights[:word2vec.syn1.shape[0]] = word2vec.syn1
label_dict = np.load('../data/label_dict.npy', allow_pickle=True).tolist()
label_dict = dict(zip(label_dict.values(), label_dict.keys()))
jieba.load_userdict('../data/OTA_words.txt')
st = re.compile('\[.*?\]')
rule = re.compile(u"[^\u4e00-\u9fa5]")
def handel_query(line):
mytext = st.sub('', line)
line = rule.sub('', mytext)
line = list(jieba.cut(line))
return line
dataset = pd.read_csv('../data/all_data_final.csv')
dataset['words'] = dataset['query'].apply(lambda x: handel_query(x))
dataset['token'] = dataset['words'].apply(lambda words: [word2vec.wv.vocab[token].index if token in word2vec.wv.vocab else max_features for token in words])
train_df = dataset[0: int(dataset.shape[0] * 0.9)]
test_df = dataset[int(dataset.shape[0] * 0.9):]
x_train = train_df['token'].tolist()
x_train = pad_sequences(x_train, maxlen=maxlen) # 将超过固定值的部分截掉,不足的在最前面用0填充
x_train_current = x_train
x_train_left = np.hstack([np.expand_dims(x_train[:, 0], axis=1), x_train[:, 0:-1]])
x_train_right = np.hstack([x_train[:, 1:], np.expand_dims(x_train[:, -1], axis=1)])
y_train = to_categorical(train_df['label_id'].tolist(), num_classes=339) # 将标签转换为one-hot编码
batch_size = 1000
epochs = 10
class_num = 339
last_activation = 'softmax'
model = TextRCNN_model(maxlen, max_features, embedding_dims, class_num, embedding_weights, last_activation)
model.summary()
print('Train...')
model.fit([x_train_current, x_train_left, x_train_right], y_train, batch_size=batch_size, epochs=epochs)
# 模型保存
model.save('./model/textrcnn_model.h5')
# model = load_model('./model/textcnn_model.h5')
print('Test...')
x_test = test_df['token'].tolist()
x_test = pad_sequences(x_test, maxlen=maxlen) #将超过固定值的部分截掉,不足的在最前面用0填充
x_test_current = x_test
x_test_left = np.hstack([np.expand_dims(x_test[:, 0], axis=1), x_test[:, 0:-1]])
x_test_right = np.hstack([x_test[:, 1:], np.expand_dims(x_test[:, -1], axis=1)])
y_predict = model.predict([x_test_current, x_test_left, x_test_right])
print('准确率', metrics.accuracy_score(test_df['label_id'].tolist(), [np.argmax(score) for score in y_predict]))
# 再次训练
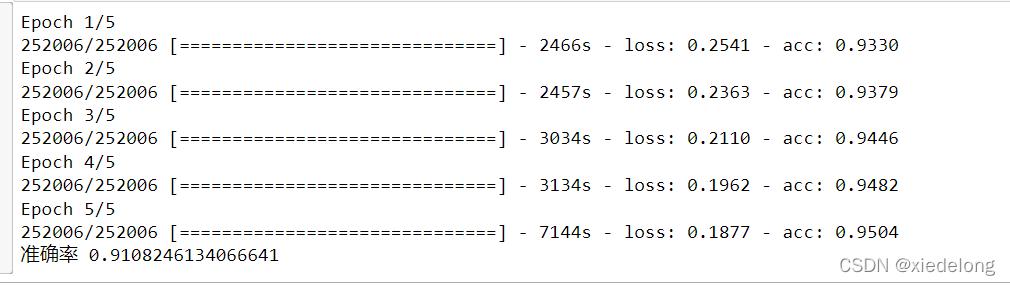
model.fit([x_train_current, x_train_left, x_train_right], y_train, batch_size=batch_size, epochs=5)
y_predict = model.predict([x_test_current, x_test_left, x_test_right])
print('准确率', metrics.accuracy_score(test_df['label_id'].tolist(), [np.argmax(score) for score in y_predict]))

















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









