 领域模型设计详解
领域模型设计详解





概要说明
| *血模型 | 概述 |
| 失血模型 | 模型仅仅包含数据的定义和getter/setter方法,业务逻辑和应用逻辑都放到服务层中。这种类在Java中叫POJO,在.NET中叫POCO。 |
| 贫血模型 | 贫血模型中包含了一些业务逻辑,但不包含依赖持久层的业务逻辑。这部分依赖于持久层的业务逻辑将会放到服务层中。可以看出,贫血模型中的领域对象是不依赖于持久层的。 |
| 充血模型 | 充血模型中包含了所有的业务逻辑,包括依赖于持久层的业务逻辑。所以,使用充血模型的领域层是依赖于持久层,简单表示就是 UI层->服务层->领域层<->持久层。 |
| 胀血模型 | 胀血模型就是把和业务逻辑不想关的其他应用逻辑(如授权、事务等)都放到领域模型中。我感觉胀血模型反而是另外一种的失血模型,因为服务层消失了,领域层干了服务层的事,到头来还是什么都没变。 |
特点对比分析
关于一个模型的相关处理逻辑如下
1.成员的set/get。
2.对数据加工的逻辑,相比于set/get更复杂的逻辑。
3.关于数据的处理。
4.对表示层的响应。
| 成员的set/get | 对数据加工的逻辑 | 对数据的处理的调用 | 对表示层的响应 | |
| 失血模型 | 模型 | 逻辑层 | 逻辑层 | 逻辑层 |
| 贫血模型 | 模型 | 模型 | 逻辑层 | 逻辑层 |
| 充血模型 | 模型 | 模型 | 模型 | 逻辑层 |
| 胀血模型 | 模型 | 模型 | 模型 | 模型 |
补充说明
通常的3层架构,表示层,业务层,数据层。表示层和数据层都好理解,就是把数据加工层模型表示,或者通过表示层的数据加工成模型,并保存。这里的关键是对模型的加工有两种加工,简单加工,复杂加工。简单加工就是set/get复杂加工就是指更复杂的加工逻辑,关于以上的4中*血模型,处理差别的关键就在于对复杂处理逻辑的处理放置的位置。
| 失血模型 | 贫血模型 | 充血模型 | 胀血模型 |
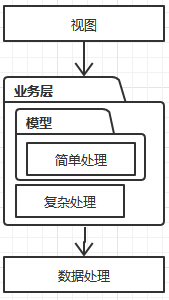 | 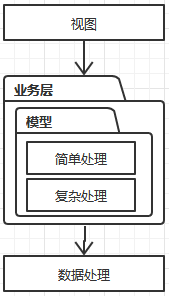 | 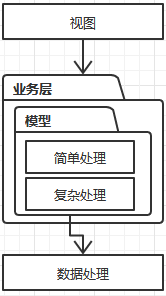 | 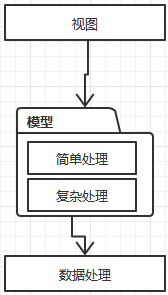 |

















 2617
2617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









