 PyQt6打造Hexo博客管理工具
PyQt6打造Hexo博客管理工具




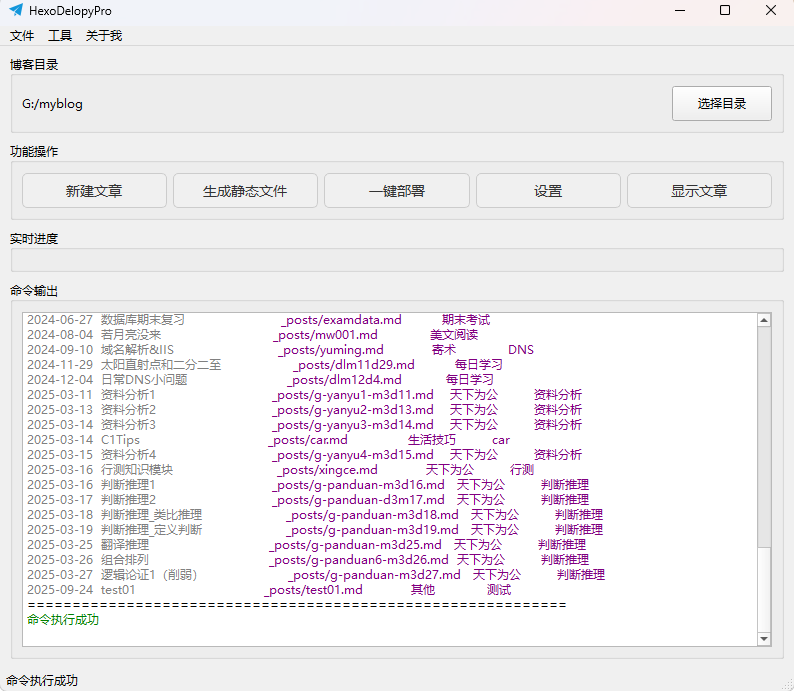 不用每次找到自己的项目目录然后cmd或者github bash here然后在hexo cl hexo g等等。 全部包装好了。直接制作成exe。双击运行 记忆目录。每次打开直接新建文章然后并且自动打开创建好的Markdown文件。 创作好后,一键发布到github自动部署。
不用每次找到自己的项目目录然后cmd或者github bash here然后在hexo cl hexo g等等。 全部包装好了。直接制作成exe。双击运行 记忆目录。每次打开直接新建文章然后并且自动打开创建好的Markdown文件。 创作好后,一键发布到github自动部署。
需要的直接下载咯,好不好用记得回来评论
https://hope.xurunbo.top/y3XI0LoS8z6xtqHy8HiwBJlToT5wnD31/HexoDeplyPro.exe
http://lc-hhMy4V8o.cn-n1.lcfile.com/FRqzEEUXwMQucQbK0onCbgwKyTF4FHjm/HexoDeplyPro.exe

















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









