







ConcurrentHashMap
一直以来一提到HashMap是线程不安全的,马上就会说使用ConcurrentHashMap这个线程安全的Map,但对其中的实现原理也是懵懵懂懂,本篇就来扒一下ConcurrentHashMap的实现原理
实现原理
ConcurrentHashMap底层并不是对HashMap的扩展,而是同样从底层基于数组+链表进行功能实现。其实现原理在JDK1.7和JDK1.8时是不一样的,详见 >>>>> HashMap实现原理(面试必背)
JDK1.7 ConcurrentHashMap的实现原理:
使用了Segment(分段锁)+ReentrantLock的技术,Segment继承ReentrantLock锁,是用于存放数组HashEntry[],Segment可以理解为一个桶,段,或者区域,简单的说就是ConcurrentHashMap中维护了多个段(Segment),默认为16个,每个段中都有HashEntry[],那么在使用put放法时,就不用将整个Map加锁了,通过Hash算法得到Key应该存入哪个段中,对该段进行加锁即可(这样一来,ConcurrentHashMap可以最大容纳16个线程并发操作),Segment对象的put方法会先加锁,然后根据再key计算出在段中对应的hashEntry[]的数组下标,然后将key和value封装为HashEntry对象放入该位置,此过程和JDK7中的HashMap的put方法一样,然后解锁。
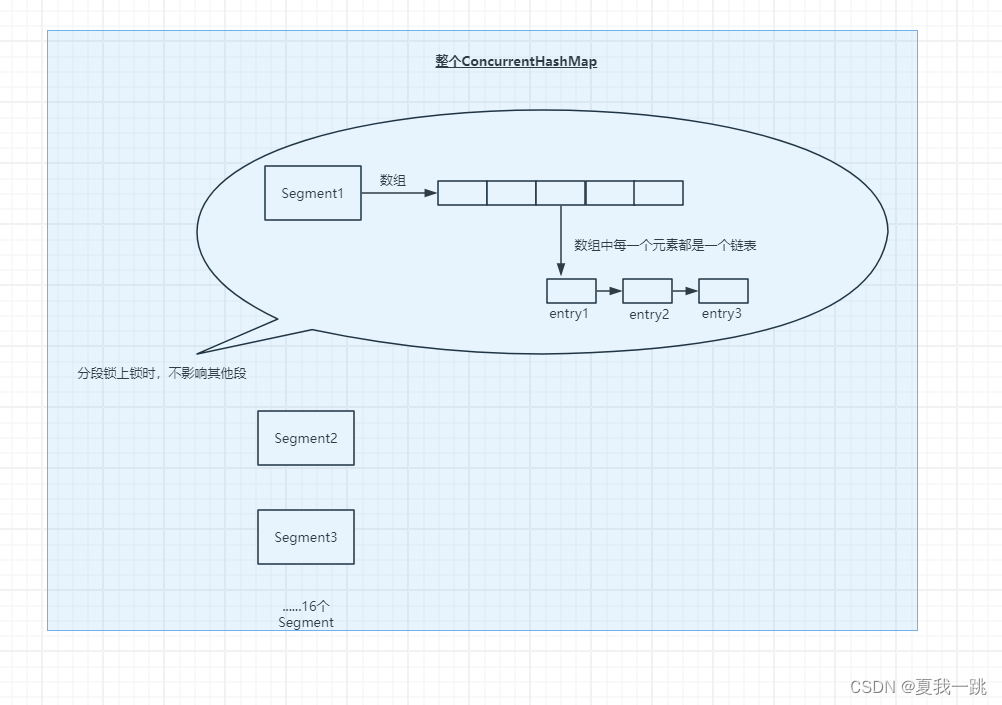
此外ConcurrentHashMap的get()方法是没有加锁的
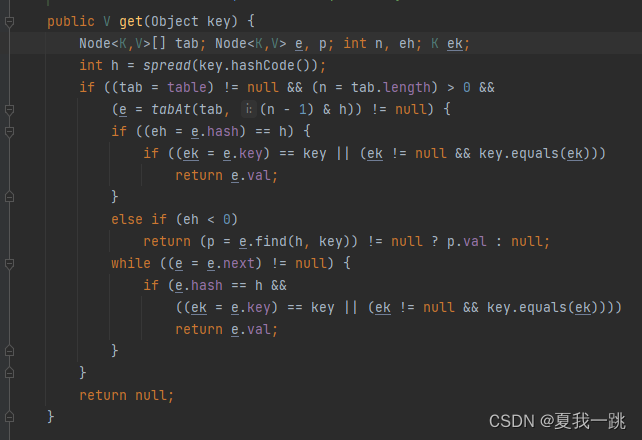
因为使用了volatile关键字,保证读取的是最新的数据
JDK1.8 ConcurrentHashMap的实现原理:
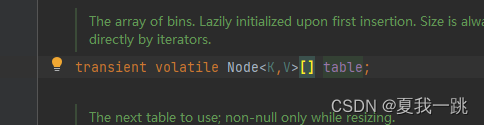
其摒弃了之前的Segment(分段锁)的概念,而是采用Node。它沿用了与它同期的HashMap版本的思想采用数组+链表+红黑树来实现,利用CAS+Synchronized来保证并发更新的安全。JDK1.8的ConcurrentHashMap结构基本上和JDK1.8的HashMap一样,不过保证线程安全性。
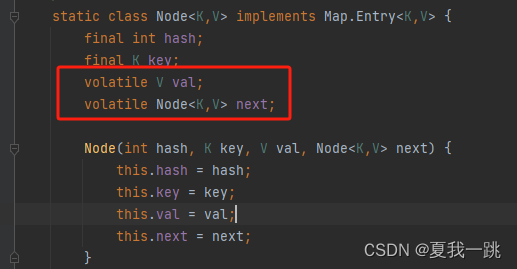
Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性。
CAS(Compare-And-Swap):
比较并交换,CAS就是通过一个原子操作,用预期值去和实际值做对比,如果实际值和预期相同,则做更新操作。
如果预期值和实际不同,我们就认为,其他线程更新了这个值,此时不做更新操作。
而且这整个流程是原子性的,所以只要实际值和预期值相同,就能保证这次更新不会被其他线程影响。
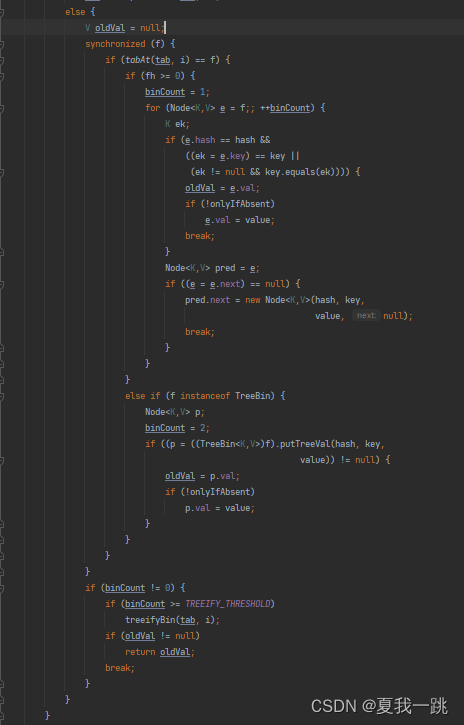
ConcurrentHashMap的put方法关键流程:
1.做插入操作时,首先进入乐观锁
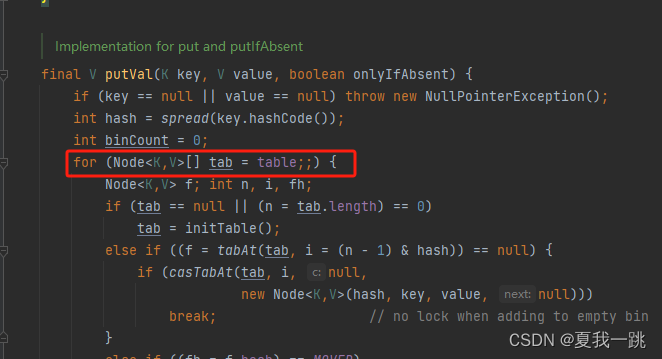
2.然后,在乐观锁中判断容器是否初始化,如果没初始化则初始化容器,
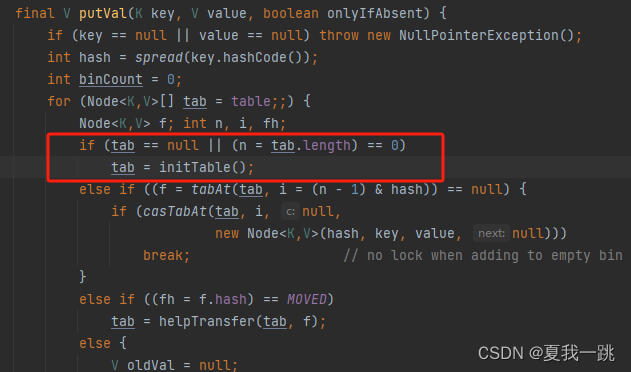
3.如果已经初始化,则判断该hash位置的节点是否为空,如果为空,则通过CAS操作进行插入。
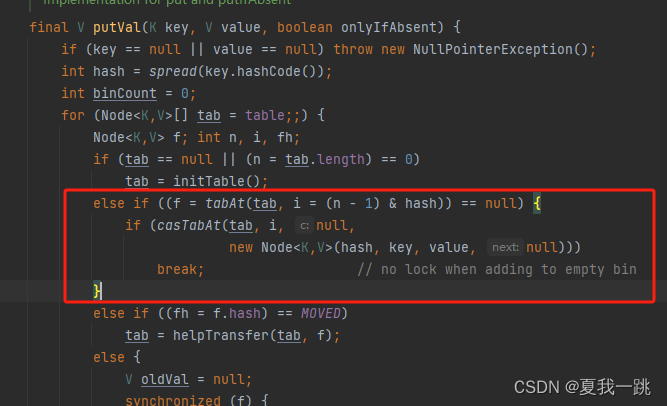
4.如果该节点不为空,再判断容器是否在扩容中,如果在扩容,则帮助其扩容。
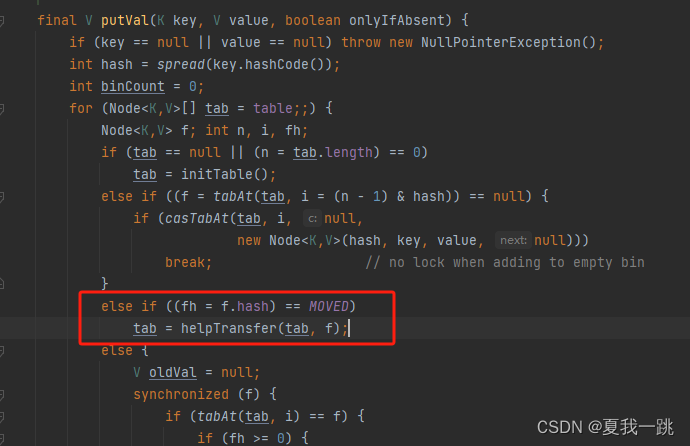
如果没有扩容,则进行最后一步,先加锁,然后找到hash值相同的那个节点(hash冲突),循环判断这个节点上的链表,决定做覆盖操作还是插入操作。循环结束,插入完毕。
ConcurrentHashMap总结:
1.实现方式:1.7使用了Segment(分段锁)+ReentrantLock的技术,1.8摒弃了Segment(分段锁)的概念,而是采用Node。它沿用了与它同期的HashMap版本的思想采用数组+链表+红黑树来实现,利用CAS+Synchronized来保证并发更新的安全
2.锁的粒度:1.7是对需要进行数据操作的Segment加锁,1.8调整为对每个数组元素加锁(Node)
3.数据结构:1.7底层是数组+链表,1.8数组+链表+红黑树
4.查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
上一篇 >>>>> HashMap实现原理(面试必背)
That’s it;
莫愁千里路,自有到来风

















 2082
2082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









