




 本文探讨了Mybatis的分页插件、注解开发的利弊,重点讲解了一对多和多对一关系的复杂查询,以及如何利用动态SQL、缓存优化性能。还介绍了Lombok简化POJO的使用和自定义缓存的实践。
本文探讨了Mybatis的分页插件、注解开发的利弊,重点讲解了一对多和多对一关系的复杂查询,以及如何利用动态SQL、缓存优化性能。还介绍了Lombok简化POJO的使用和自定义缓存的实践。
目录
8 分页
SQL分页查询:
Limit start,length:查询[start,start+length),下标从0开始
Limit end:从查询[0,n)
正常写就好了
有个古老的不再使用的:Rowbounds功能,不建议使用
8.1 分页插件
Mybatis PageHelper分页插件
9 注解开发
9.1 面向接口编程
最主要的原因:解耦
定义与实现的分离
9.2 注解开发(了解,项目不允许使用)
简单的sql可以使用,复杂的sql则力不从心了,建议使用xml配置
使用方法:在mapper.java接口中
@Select("select * from user")
public List<User> findAll();
然后在mybatis核心配置文件中绑定接口,使用class方式而不是resource即可
如果是多个参数,需要加@Param参数,该参数值需要保证和#{}中一致(这里有待测试)
基本类型或者String需要加,引用类型不需要,只有一个基本类型可以忽略
@Select("select * from user where id=#{id} and name=#{name}")
User getUserByIdAndName(@Param("id") int id,@Param("name") String name);
10 Mybatis执行流程
- Resources获取全局配置文件
- 实例化SqlSessionFactoryBuilder构造器
- 解析配置文件流XMLConfigBuilder
- 生成一个Configuration,包含所有配置信息
- SqlSessionFactory实例化
- 创建事务管理:transactional
- 创建executor执行器
- 创建SqlSession
- 实现CRUD,然后就在789来回执行
- 执行完所有sql,提交事务时查看是否执行成功,不成功则回滚到6之后7之前,成功提交事务
- 关闭
11 Lombok
用于简化POJO类编写
@Data注解在类上,会为类的所有属性自动生成setter/getter、equals、canEqual、hashCode、toString方法,如为final属性,则不会为该属性生成setter方法。
使用方法:
- idea中安装lombok插件
- 项目中导入lombok包
- 配置注解
常用注解:@Data,生成全套方法
12 复杂关系查询
复杂类型这里需要重点理解一下,首先一对多和多对一都是相对的,可以互相转化的,观察视角不同罢了。不同的视角可以构建处不同的POJO。
举个例子:学生和老师,在数据库中表设计如下:(不使用物理外键)
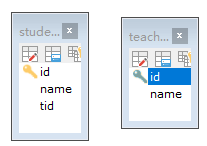
很明显看出来,学生和老师是多对一的关系。老师和学生是一对多的关系。
用Mybatis语言表述就是:【一个学生只能关联到一位老师】【一个老师集合了多个学生】
简单的讲就是学生和老师的关系:一个老师教很多学生,每个学生只有一个老师,则学生和老师关系为多对一,老师和学生关系为一对多
多对一:可以理解为多个实体关联同一个实体,association,javaType(对象属性)
一对多:可以理解为一个实体集合了多个实体,collection,ofType(集合中的泛型)
首先以学生为视角,我们讨论一下多对一的关系构建
12.1 多对一
学生视角下,一个学生只有一个老师,所以老师属性用对象类型作为实体属性
学生类Student属性:id name Teacher
@Data
public class Student{
private int id;
private String name;
private Teacher teacher;
}
老师类Teacher属性:id name
@Data
public class Teacher{
private int id;
private String name;
}
由于学生类中包含对象字段,需要用复杂查询
12.1.1 子查询
步骤:
- 先查询出指定的学生信息
- 根据学生信息中的tid进行老师信息查询
<!--学生信息查询-->
<select id="findStudent2ById" resultMap="findStudentByIdResult">
select * from student where id=#{id}
</select>
<!--学生实体中的对象属性需要用association来映射-->
<resultMap id="findStudentByIdResult" type="student2">
<id property="id" column="id"/>
<result property="name" column="name"/>
<!--为了关联老师实体对象,使用tid外键传入子查询-->
<association property="teacher2" javaType="teacher2" column="tid" select="findTeacher2ById"/>
</resultMap>
<!--根据tid查询出老师信息-->
<select id="findTeacher2ById" resultType="teacher2">
select * from teacher where id=#{tid}
</select>
特别注意:association中的javaType由于在子查询中有resultType给定了,所以javaType可以省略!!
12.1.2 结果集映射
将所有信息全部查询出来再做映射
<select id="findStudent2ById2" resultMap="findStudentByIdResult2">
select s.id s_id,s.name s_name,s.tid s_tid,t.id t_id,t.name t_name from student s,teacher t where s.id=#{id} and s.tid=t.id
</select>
<resultMap id="findStudentByIdResult2" type="student2">
<id property="id" column="s_id"/>
<result property="name" column="s_name"/>
<association property="teacher2" javaType="teacher2">
<id property="id" column="t_id"/>
<result property="name" column="t_name"/>
</association>
</resultMap>
12.2 一对多
这里使用老师为视角,谈论一对多的关系构建
由于是老师为主,老师POJO下集合了多个学生,构建POJO类如下:
学生类Student属性:id name
@Data
public class Student{
private int id;
private String name;
// private int tid; // 注意:此处可写可不写,主要看需求是否需要获取该属性
}
老师类Teacher属性:id name studentList
@Data
public class Teacher{
private int id;
private String name;
private List<Student> studentList;
}
构建查询,查询方式分为两种,子查询方式和结果集嵌套方式
12.2.1 子查询
步骤:
- 首先对老师进行获取,使用resultMap映射
- 老师下面有个学生集合,使用collection映射
- 学生和老师是通过一个逻辑外键(tid)来作用的,所以这里column指定以下需要传给子查询的字段值
- 子查询通过传递过来的值进行查询获取学生集合,映射到老师的属性中
<!--首先对老师进行获取,使用resultMap映射-->
<select id="findTeacherById" resultMap="findTeacherByIdResult">
select * from teacher where id=#{id}
</select>
<!--老师下面有个学生集合,使用collection映射-->
<resultMap id="findTeacherByIdResult" type="teacher">
<id property="id" column="id"/>
<result property="name" column="name"/>
<!--学生和老师是通过一个逻辑外键(student.tid=teacher.id)来作用的,所以这里column指定以下需要传给子查询的字段值,当前环境只有老师的id-->
<collection property="studentList" column="id" ofType="student" select="findStudentById"/>
</resultMap>
<!--子查询通过传递过来的值进行查询获取学生集合,映射到老师的属性中-->
<select id="findStudentById" resultType="student">
select * from student where tid=#{id}
</select>
特别注意:collection里的ofType可以不写,因为子查询指定了resultType!
12.2.2 结果集映射
结果集映射顾名思义,在一条语句中查询出所有信息,然后将其映射到对应的POJO类中即可!思想很简单,直接上代码:
<!--这条语句结果包含所需的所有字段值-->
<select id="findTeacherById2" resultMap="findTeacherByIdResult2">
SELECT t.id t_id,t.name t_name,s.name s_name,s.id s_id,s.tid s_tid FROM teacher t,student s WHERE t.id=#{id} AND t.id=s.tid;
</select>
<resultMap id="findTeacherByIdResult2" type="teacher">
<id property="id" column="t_id"/>
<result property="name" column="t_name"/>
<collection property="studentList" ofType="student">
<id property="id" column="s_id"/>
<result property="name" column="s_name"/>
</collection>
</resultMap>
13 动态SQL
简化SQL拼接,当前提供功能如下:
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
if
标签如下:
<if test="条件表达式"> sql语句</if>
示例:
<select 省略>
select * from blog where 1=1
<if test="titel != null">and title=#{title}</if>
<if test="author != null">and author=#{author}</if>
</select>
注意:如果没有1=1,则条件成立后的and语句语法就不对了,但是这个1=1没什么实际含义,为了解决这个问题,使用where标签,该标签自动插入where且能删除多余and或or
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
chose
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
set
类似where,可以动态的拼接和删除末尾逗号
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
trim
prefix:前缀,如果标签内部存在内容,则加上前缀
做功能定制,如和where等价的trim元素为:
prefixOverrides:前缀移除,移除标签内部语句的匹配前缀
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
和set元素等价的trim元素为:
suffixOverrides:后缀移除,移除标签内部所有匹配后缀
<trim prefix="SET" suffixOverrides=",">
...
</trim>
foreach
集合遍历:用于in查询,特别注意:foreach中的collection属性!!
foreach的collection属性取值:
如果在接口中定义了@Param则按照注解来,否则:
如果是单参数,且为List类型,则为list
如果是单参数,且为array类型,则为array
如果是多参数,需要封装成Map,则为key
接口:
List<User> findByIds(@Param("ids")List ids);
映射文件:
<select id="findByIds" resultType="User" >
select * from user where id in
<foreach collection="ids" item="id" open="(" separator="," close=")">#{id}</foreach>
</select>
sql
可以将sql语句提取出来,然后include到需要用到的地方放,最好引用简单sql,防止出错
引用:

使用:

14 缓存
查询相同数据时直接走缓存不去数据库查询,提高查询速度,因为大部分情况下都在做查询操作
解决问题:高并发系统的性能问题
三高:高并发、高可用、高性能
使用环境:经常查询且不经常改变的数据
Mybatis提供:一级缓存和二级缓存
一级缓存:默认开启,SqlSession级别,又称为本地缓存,同一用户在一次请求中查询重复数据会使用缓存,close后清除
二级缓存:需要手动配置,基于namespace级别
自定义缓存:实现Mybatis的Cache接口,自定义二级缓存
映射语句文件中的所有 select 语句的结果将会被缓存。
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。(缓存失效)
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。(默认)
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
缓存策略:可用的清除策略有:
LRU – 最近最少使用:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU。
14.1 一级缓存
手动清理缓存:sqlSession.clearCache()
14.2 二级缓存
同一个mapper下的会话会用到二级缓存
开启方式:要启用全局的二级缓存,还需要在你的 SQL 映射文件中添加一行:<cache/>
<cache/>
或,详细配置一下:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
解释:创建一个FIFO缓存,每隔60秒刷新,最多存储512个引用,返回的对象是只读的,不要去修改。
另外:为了方便阅读,建议显式配置一下:cacheEnabled:全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。默认值为true。
<setting name="cacheEnable" value="true"/>
二级缓存作用机制:查询时的一级缓存在关闭会话后被放到二级缓存中了,新的会话可以从二级缓存中获取内容,不同的mapper查处的数据放在自己对应的map中
注意:关闭会话后才会放到二级缓存中,新会话才会用到二级缓存
注意:如果报未序列化错误,则在pojo类实现一下序列化即可
注意:查询时的顺序:二级缓存–>一级缓存–>数据库
14.3 自定义缓存
可以使用自己写的或者第三方的:<cache type="自定义缓存使用类"/>
14.3.1 使用第三方缓存
ehcache:一个纯Java进程内缓存框架,Hibernate默认缓存管理,面向通用缓存
redis:目前最流行的内存缓存
这里使用ehcache测试一下,步骤:
- 导包
- 加标签:
<cache type="org.mybatis.caches.ehcache.EhcacheCache/> - 加配置文件:ehache.xml(去网上搜一下,不做赘述)
14.3.2 使用自定义类
略

















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









