




目录
1. 流形学习:降维利器登场
在当今数字化时代,数据呈爆炸式增长,高维数据无处不在。无论是图像识别中动辄成千上万维度的图像特征向量,还是生物信息学里复杂的基因表达数据,又或是自然语言处理中高维的文本向量表示,高维数据给我们带来丰富信息的同时,也带来了巨大的挑战,其中最为突出的便是 “维数灾难”。随着数据维度的增加,数据点在高维空间中变得极为稀疏,传统的距离度量和相似性评估方法失效,基于距离的聚类、分类等算法难以准确地捕捉数据的内在结构 。而且,高维数据会导致计算量呈指数级增长,算法的运行时间大幅延长,甚至在实际应用中变得不可行。此外,高维数据还容易引发过拟合问题,模型在训练数据上表现良好,但在新的数据上泛化能力很差,无法准确地进行预测和分析。
流形学习作为一种强大的非线性降维技术,应运而生,成为了应对 “维数灾难” 的有力武器。它基于一个重要假设:高维数据实际上是由低维流形嵌入到高维空间中的,即数据点在低维空间中存在着一种潜在的、连续且光滑的流形结构。尽管这些数据在高维空间中看似杂乱无章,但在低维流形上却遵循着特定的规律 。流形学习的主要优势在于能够发现数据的低维嵌入,从而有效地降低数据的维度。通过学习数据的流形结构,它可以将高维数据映射到低维空间,同时最大程度地保留数据的内在几何特性。这一特性使得流形学习在数据可视化、特征提取、机器学习模型性能提升等诸多领域都发挥着不可或缺的作用。接下来,就让我们深入探索流形学习的原理与实现。
2. 流形学习原理剖析
2.1 流形的概念
在数学领域中,流形是一种局部具有欧氏空间性质的拓扑空间。简单来说,对于流形上的任意一点,都存在一个邻域,这个邻域与欧氏空间中的开集是同胚的(同胚可以理解为一种连续的、可逆的映射,并且其逆映射也是连续的,在拓扑学中用于描述两个空间在连续变形下的等价性 )。就像地球表面,从全局来看,它是一个三维空间中的弯曲球面,有着自身独特的整体几何性质,比如球面上三角形的内角和大于 180 度 。但当我们把视野局限在一个足够小的区域,比如一座城市的范围,我们会感觉自己处于一块平坦的土地上,这个局部区域就可以近似看作是二维平面,也就是欧氏空间中的一个子集。在这个局部范围内,我们可以使用平面几何知识,比如用直角坐标系来描述位置,用欧氏距离来计算两点之间的距离 。
从数据科学的角度来看,流形可以被视为高维数据在低维空间中的一种潜在结构。假设我们有一组高维数据点,尽管它们在高维空间中的分布看似杂乱无章,但实际上可能分布在一个低维流形上。例如,在图像数据中,每一张图像可以表示为一个高维向量,向量的每个维度对应图像的一个特征,如像素值、颜色特征等。虽然这些高维向量在高维空间中看起来很复杂,但它们可能是由一个低维流形嵌入到高维空间中的,这个低维流形捕捉了图像数据的内在结构,比如图像的类别、形状等特征。又比如在语音识别中,语音信号可以转换为高维的特征向量,这些向量同样可能分布在一个低维流形上,这个流形反映了语音的语义、语调等信息。 流形的局部与整体特性是理解流形学习的关键。局部特性使得我们可以在局部区域内使用简单的欧氏空间模型来近似处理数据,而整体特性则要求我们在降维过程中尽可能保留数据的全局结构和内在关系。
2.2 流形学习的核心假设
流形学习基于一个重要的核心假设:高维数据实际上分布在一个低维的流形上 。这意味着,尽管数据在高维空间中呈现出复杂的分布形态,但它们之间存在着一种潜在的、低维的结构关系。例如,在手写数字识别任务中,每个手写数字图像可以表示为一个高维向量(通常是一个包含图像像素值的向量,假设图像大小为 28x28 像素,则向量维度为 784),这些高维向量看似在 784 维空间中杂乱分布,但实际上它们是由一个低维流形嵌入到这个高维空间中的。这个低维流形捕捉了手写数字的本质特征,如数字的形状、笔画顺序等。通过学习这个低维流形,我们可以将高维的图像数据映射到低维空间中,同时保留数据的关键信息,实现降维的目的 。
与传统的线性降维方法(如主成分分析 PCA)相比,流形学习的这一假设突破了线性降维的局限性。传统的线性降维方法假设数据是线性分布的,即数据可以通过线性变换(如矩阵乘法)投影到低维空间中。然而,在许多实际问题中,数据的结构往往是非线性的。例如,在上面提到的手写数字图像数据中,不同数字的图像之间的关系并不是简单的线性关系,无法通过线性降维方法准确地捕捉到它们的内在结构。而流形学习能够处理这种非线性结构,通过探索数据在低维流形上的分布规律,找到更合适的降维方式,从而更好地保留数据的本质特征和内在关系 。 流形学习的核心假设为我们处理高维数据提供了新的视角和方法,使得我们能够更深入地挖掘数据中的潜在信息,在数据可视化、特征提取、机器学习模型性能提升等方面发挥重要作用。
2.3 局部保持思想
局部保持思想在流形学习中起着至关重要的作用,它是流形学习算法能够有效处理非线性数据的关键所在。其核心在于,在高维空间中彼此接近的数据点,在低维空间中也应该保持相似的相对位置 。这一思想基于流形的局部欧氏空间性质,即流形在局部区域内可以近似看作欧氏空间,因此在局部范围内可以使用欧氏距离等简单的度量方式来描述数据点之间的关系。
在流形学习中,大多数算法通过构建邻域图来捕捉数据的局部几何结构。具体来说,对于数据集中的每个数据点,我们确定它的 k 个最近邻点(k 是一个预先设定的参数),然后在这些点之间建立连接,形成一个邻域图。在这个邻域图中,边的权重通常表示两个数据点之间的相似度,例如可以使用欧氏距离的倒数作为权重,距离越近,权重越大,表示两个点的相似度越高 。通过构建这样的邻域图,流形学习算法能够保留数据点之间的局部相对位置关系。在低维嵌入过程中,算法会根据邻域图的结构,将高维数据点映射到低维空间中,使得在高维空间中相邻的数据点在低维空间中也尽可能相邻。这样,就可以在降维的同时,最大程度地保留数据的局部几何特征和内在结构 。
以局部线性嵌入(LLE)算法为例,它假设每个数据点都可以由其邻域点的线性组合来表示,并且在低维空间中保持这种线性关系。通过计算每个数据点与其邻域点之间的线性重构权重,LLE 算法能够将高维数据点准确地映射到低维空间中,实现局部结构的保持 。这种局部保持思想使得流形学习算法在处理非线性数据时具有明显的优势,能够发现数据中隐藏的低维结构,为后续的数据分析和处理提供有力支持。
2.4 主要算法原理
2.4.1 局部线性嵌入(LLE)
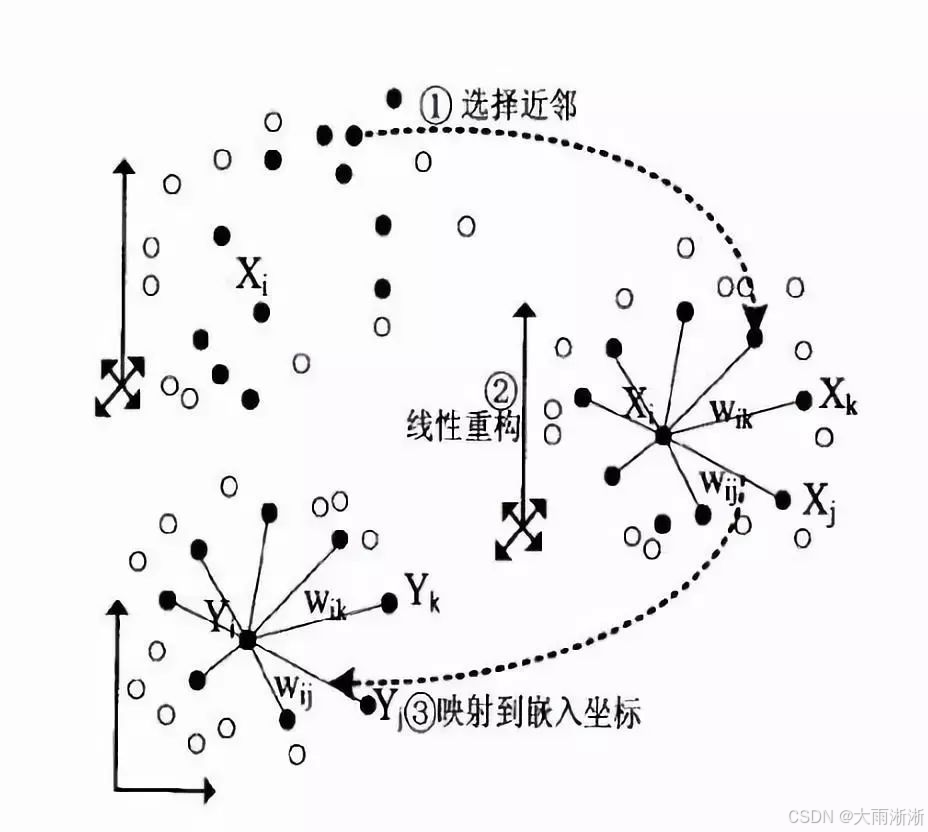
局部线性嵌入(Locally Linear Embedding,LLE)是一种基于局部线性假设的非线性降维方法,其核心思想是高维流形局部可近似为欧氏空间,通过保持样本邻域内的线性关系实现低维嵌入。该算法主要包括以下三个步骤 :
- 寻找近邻:对于数据集中的每个样本点\(x_i\),通过计算欧氏距离或余弦相似度等距离度量方式,找到其 k 个最近邻点,构成邻域集合\(N(i)\)。这个步骤的目的是确定每个样本点在局部范围内的邻居,以便后续计算局部线性关系 。
- 计算局部权重:假设样本点\(x_i\)可以由其邻域样本点\(x_j\)(\(j \in N(i)\))线性组合表示,即\(x_i \approx \sum_{j \in N(i)} W_{ij}x_j\),其中\(W_{ij}\)是权重系数。为了求解权重\(W_{ij}\),LLE 算法通过最小化重构误差来实现,即求解以下优化问题:
\(\min_{W} \sum_{i=1}^{N} \left| x_i - \sum_{j \in N(i)} W_{ij}x_j \right|^2 \quad \text{s.t.} \quad \sum_{j} W_{ij} =1\)
这个优化问题可以通过局部协方差矩阵求逆等方法得到闭式解。在实际计算中,为了避免矩阵奇异等问题,通常会对协方差矩阵进行正则化处理,例如添加一个小的对角矩阵 。通过求解这个优化问题,得到的权重\(W_{ij}\)反映了样本点\(x_i\)与其邻域点之间的线性关系 。
- 低维嵌入:在得到权重矩阵\(W\)后,LLE 算法在低维空间(维度为 d)中求解嵌入\(y_i\),使得低维空间中的点也满足与高维空间中相同的线性重构关系,即:
\(\min_{Y} \sum_{i=1}^{N} \left| y_i - \sum_{j \in N(i)} W_{ij}y_j \right|^2\)
这个问题等价于求稀疏矩阵\((I - W)^T(I - W)\)的最小 d + 1 个特征值对应的特征向量,其中\(I\)是单位矩阵。通常会排除最小特征值 0 对应的特征向量,因为它对应于一个平凡解(所有点都映射到同一个位置)。最终得到的特征向量就是样本点在低维空间中的嵌入表示 。
通过以上三个步骤,LLE 算法能够有效地将高维数据映射到低维空间中,同时保留数据的局部线性结构,在数据可视化、特征提取等领域有广泛的应用 。例如,在图像数据降维中,LLE 算法可以将高维的图像特征向量映射到低维空间,使得相似的图像在低维空间中也相邻,有助于图像的分类和检索;在生物信息学中,对于基因表达数据的降维,LLE 算法可以发现基因之间的潜在关系,帮助研究人员理解生物过程。
2.4.2 等距映射(Isomap)
等距映射(Isometric Feature Mapping,Isomap)是对经典多维尺度分析(Multidimensional Scaling,MDS)的扩展,它通过计算点之间的测地距离(即沿着流形的最短路径)来构造距离矩阵,并将其嵌入低维空间以保持全局结构 。MDS 是一种经典的降维方法,它的目标是在低维空间中保持高维空间中样本点之间的距离关系。具体来说,给定一个高维数据集中的距离矩阵\(D\),MDS 算法试图找到一个低维空间中的坐标矩阵\(Y\),使得在低维空间中计算得到的距离矩阵\(D'\)与原始的距离矩阵\(D\)尽可能相似。通常通过最小化某种距离度量(如应力函数)来实现这一目标,应力函数定义为:
\(Stress = \sqrt{\frac{\sum_{i \lt j} (d_{ij} - d_{ij}')^2}{\sum_{i \lt j} d_{ij}^2}}\)
其中\(d_{ij}\)是原始高维空间中样本点\(i\)和\(j\)之间的距离,\(d_{ij}'\)是低维空间中对应点之间的距离。通过迭代优化,MDS 算法可以找到使得应力函数最小的低维坐标矩阵\(Y\) 。
Isomap 算法在 MDS 的基础上,引入了测地距离的概念。由于在高维流形中,直接使用欧氏距离可能无法准确反映数据点之间的真实距离关系,而测地距离能够更好地描述沿着流形表面的距离。Isomap 算法首先构建一个近邻连接图,对于每个点,基于欧氏距离找出其近邻点,然后在图中近邻点之间建立连接,非近邻点之间不存在连接。这样,计算两点之间测地距离的问题就转变为计算近邻连接图上两点之间的最短路径问题,可以采用著名的 Dijkstra 算法或 Floyd 算法来计算 。在得到任意两点之间的测地距离后,Isomap 算法就可以利用 MDS 方法,将这些测地距离作为新的距离矩阵,进行低维嵌入,从而在低维空间中保持数据的全局结构 。
例如,在一个形状复杂的数据集上,如瑞士卷数据集,欧氏距离可能会将位于不同 “层” 但在欧氏空间中距离较近的点错误地认为是相近的,而测地距离能够准确地反映它们在流形上的真实距离,通过 Isomap 算法使用测地距离进行降维,可以更好地展示数据的内在结构,将瑞士卷的不同 “层” 在低维空间中清晰地分开 。Isomap 算法在处理具有复杂全局结构的数据时表现出色,能够有效地保留数据的全局几何信息,为数据分析和可视化提供了有力的工具。
2.4.3 t - 分布随机邻域嵌入(t-SNE)
t - 分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种基于概率建模的降维方法,特别适合用于可视化高维数据 。其核心思想是通过概率分布来表示数据点之间的相似度,将高维空间中的相似度转化为条件概率,并在低维空间中最小化两个分布之间的 KL 散度,从而实现数据的降维与可视化 。
在高维空间中,t-SNE 算法使用高斯分布来定义数据点之间的相似度。对于每个数据点\(x_i\),计算它与其他数据点\(x_j\)之间的条件概率\(p_{j|i}\),表示在给定\(x_i\)的情况下,\(x_j\)是其近邻的概率,公式为:
\(p_{j|i} = \frac{\exp(-\frac{\|x_i - x_j\|^2}{2\sigma_i^2})}{\sum_{k \neq i} \exp(-\frac{\|x_i - x_k\|^2}{2\sigma_i^2})}\)
其中\(\sigma_i\)是一个与数据点\(x_i\)相关的带宽参数,通常通过二分搜索来调整,使得每个数据点的平均困惑度(perplexity)保持在一个设定的值附近。困惑度是一个衡量数据点局部邻域大小的指标,定义为:
\(perplexity = 2^{-\sum_{j} p_{j|i} \log_2 p_{j|i}}\)
在低维空间中,t-SNE 算法使用 t 分布来定义数据点之间的相似度。对于低维空间中的点\(y_i\)和\(y_j\),计算它们之间的条件概率\(q_{j|i}\),公式为:
\(q_{j|i} = \frac{(1 + \|y_i - y_j\|^2)^{-1}}{\sum_{k \neq i} (1 + \|y_i - y_k\|^2)^{-1}}\)
t-SNE 算法的目标是最小化高维空间和低维空间中条件概率分布之间的 KL 散度,即优化以下目标函数:
\(C = KL(P \| Q) = \sum_{i} \sum_{j} p_{j|i} \log \frac{p_{j|i}}{q_{j|i}}\)
其中\(P\)是高维空间中的条件概率矩阵,\(Q\)是低维空间中的条件概率矩阵。通常使用梯度下降等优化算法来最小化这个目标函数,从而得到低维空间中的嵌入点\(y_i\) 。
在实际应用中,t-SNE 算法在图像、文本等数据的可视化方面表现出色。例如,在图像分类任务中,将高维的图像特征向量通过 t-SNE 降维到二维或三维空间后,可以直观地观察不同类别的图像样本在低维空间中的分布情况,同一类别的图像通常会聚集在一起,不同类别的图像之间则会有明显的分离,有助于研究人员理解数据的分布特征和分类边界 。
2.4.4 均匀流形逼近与投影(UMAP)
均匀流形逼近与投影(Uniform Manifold Approximation and Projection,UMAP)是一种基于拓扑学理论的流形学习方法,它能够在保持局部结构的同时也较好地维护全局结构 。UMAP 算法的核心原理基于以下几个方面:
- 构建模糊拓扑:UMAP 通过构建一个模糊的、加权的图来表示数据点之间的关系。在这个图中,每个数据点是一个节点,节点之间的边权重表示两个数据点之间的相似度。与其他流形学习算法不同的是,UMAP 使用了一种基于黎曼流形上的测地线距离的近似方法来计算相似度,这种方法能够更好地捕捉数据的全局结构 。具体来说,UMAP 定义了一个邻域半径\(\epsilon\)和一个最小生成树(MST)构建过程。对于每个数据点,它首先找到在半径\(\epsilon\)内的所有邻居点,然后通过构建最小生成树来确定数据点之间的连接关系。在这个过程中,边的权重是根据数据点之间的距离和局部密度来计算的,密度较高的区域内的数据点之间的边权重会相对较大,这有助于保持数据的局部结构 。
- 低维嵌入:在构建了模糊拓扑图之后,UMAP 将高维数据点映射到低维空间中。它通过最小化一个基于 KL 散度的目标函数来实现这一映射,使得低维空间中的数据点之间的关系尽可能接近高维空间中的关系。具体的目标函数为:
\(L = KL(P \| Q) + \alpha KL(P' \| Q')\)
其中\(P\)和\(Q\)分别是高维空间和低维空间中数据点之间的概率分布,\(P'\)和\(Q'\)是在最小生成树上定义的概率分布,\(\alpha\)是一个平衡参数,用于调整局部结构和全局结构的保持程度 。通过优化这个目标函数,UMAP 能够在低维空间中同时保持数据的局部和全局结构 。
与 t-SNE 相比,UMAP 具有更高的计算效率,并且支持更广泛的嵌入维度选择。在处理大规模数据集时,UMAP 的计算速度明显优于 t-SNE,能够更快地完成降维任务 。在图像数据可视化中,UMAP 可以将高维的图像特征降维到二维或三维空间,清晰地展示不同图像类别的分布情况,同时能够保持图像之间的相似性和差异性,使得在低维空间中相邻的图像在高维空间中也具有较高的相似度 。在文本数据处理中,UMAP 可以将高维的文本向量降维,帮助分析文本之间的语义关系,发现文本数据中的主题结构和聚类信息 。
3. 流形学习的 Python 实现
3.1 准备工作
在 Python 中实现流形学习,我们需要借助一些强大的工具包,其中最常用的是 Scikit-learn 和 NumPy 。Scikit-learn 是一个广泛应用于机器学习领域的开源库,它提供了丰富的机器学习算法和工具,包括各种流形学习算法的实现 。NumPy 则是 Python 科学计算的基础库,它提供了高效的多维数组对象和各种数学函数,能够大大提高数据处理和计算的效率 。在使用之前,我们需要确保这些工具包已经安装。如果尚未安装,可以使用 pip 命令进行安装:
pip install scikit-learn numpy
除了这两个主要的工具包外,为了更好地展示流形学习的结果,我们还会用到 Matplotlib 库进行数据可视化 。Matplotlib 是 Python 中最常用的绘图库之一,它能够创建各种静态、动态和交互式的可视化图表,帮助我们直观地理解数据的分布和变化 。同样,可以使用 pip 命令安装 Matplotlib:
pip install matplotlib
3.2 数据集准备
为了更好地理解和演示流形学习的实现过程,我们选择使用经典的手写数字数据集 MNIST 。MNIST 数据集包含了 70,000 张 28x28 像素的手写数字图像,每个图像都对应一个 0 到 9 之间的数字标签,其中 60,000 张图像用于训练,10,000 张图像用于测试 。在 Scikit-learn 中,可以方便地加载 MNIST 数据集:
from sklearn.datasets import fetch_openml
# 加载MNIST数据集
mnist = fetch_openml('mnist_784', version=1)
X = mnist.data / 255.0 # 归一化处理,将像素值从0-255映射到0-1
y = mnist.target.astype(int)
在上述代码中,我们首先使用fetch_openml函数从 OpenML 数据库中获取 MNIST 数据集 。然后,对数据进行归一化处理,将像素值从 0 到 255 的范围缩放到 0 到 1 之间,这样可以使数据在后续的计算中具有更好的数值稳定性 。最后,将目标标签y的数据类型转换为整数类型,以便于后续的处理 。为了加快计算速度,我们可以选取部分样本进行实验:
# 取部分样本减少计算时间
n_samples = 5000
X_sampled = X[:n_samples]
y_sampled = y[:n_samples]
这里我们选取了前 5000 个样本,实际应用中可以根据需要调整样本数量 。
3.3 t-SNE 实现与可视化
接下来,我们使用 Scikit-learn 中的TSNE类来实现 t-SNE 降维,并将结果进行可视化 。t-SNE 是一种非常适合数据可视化的流形学习算法,它能够将高维数据映射到二维或三维空间中,同时较好地保留数据的局部结构 。下面是实现代码:
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# 设置t-SNE参数
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
# 执行t-SNE降维
X_tsne = tsne.fit_transform(X_sampled)
# 绘制二维可视化结果
plt.figure(figsize=(10, 8))
for i in range(10):
indices = y_sampled == i
plt.scatter(X_tsne[indices, 0], X_tsne[indices, 1], label=str(i))
plt.title('t-SNE Visualization of MNIST Dataset')
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.legend()
plt.show()
在上述代码中,我们首先创建了一个TSNE对象,并设置了几个重要的参数 。n_components参数指定了降维后的目标维度,这里我们设置为 2,以便在二维平面上进行可视化 。perplexity参数表示困惑度,它控制了每个数据点的有效近邻数量,影响着 t-SNE 对局部和全局结构的关注程度,这里设置为 30 。random_state参数用于设置随机种子,确保结果的可重复性,这里设置为 42 。然后,使用fit_transform方法对选取的样本数据X_sampled进行 t-SNE 降维,得到降维后的结果X_tsne 。最后,使用 Matplotlib 库绘制散点图,将不同数字类别的数据点用不同的颜色表示出来,从而直观地展示 t-SNE 降维后的效果 。从可视化结果中可以看出,t-SNE 能够将不同数字类别的数据点在二维空间中较好地分离开来,相同类别的数据点通常会聚集在一起,不同类别的数据点之间则有明显的间隔,这有助于我们直观地理解手写数字数据的内在结构和分布规律 。
3.4 UMAP 实现与对比
UMAP 是另一种强大的流形学习算法,它在保持数据局部结构的同时,也能较好地维护全局结构,并且计算效率相对较高 。下面我们使用 UMAP 对相同的手写数字数据集进行降维,并与 t-SNE 的结果进行对比 。首先,安装 UMAP 库(如果尚未安装):
pip install umap-learn
然后,实现 UMAP 降维并可视化:
import umap
import matplotlib.pyplot as plt
# 创建UMAP对象
reducer = umap.UMAP(random_state=42)
# 执行UMAP降维
X_umap = reducer.fit_transform(X_sampled)
# 绘制UMAP可视化结果
plt.figure(figsize=(10, 8))
for i in range(10):
indices = y_sampled == i
plt.scatter(X_umap[indices, 0], X_umap[indices, 1], label=str(i))
plt.title('UMAP Visualization of MNIST Dataset')
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.legend()
plt.show()
在这段代码中,我们首先创建了一个UMAP对象,并设置random_state参数为 42 以保证结果的可重复性 。然后,使用fit_transform方法对数据进行降维,得到降维后的结果X_umap 。最后,通过 Matplotlib 绘制散点图来展示 UMAP 的降维效果 。对比 t-SNE 和 UMAP 的可视化结果,可以发现它们都能够有效地将不同类别的手写数字数据点分离开来,但在具体的分布形态上存在一些差异 。t-SNE 的结果通常会使同类数据点更加紧密地聚集在一起,强调局部结构的保持;而 UMAP 在保持局部结构的同时,能够更好地展现数据的全局结构,使得不同类别之间的分布更加均匀 。此外,在计算效率方面,UMAP 通常比 t-SNE 更快,尤其是在处理大规模数据集时,UMAP 的优势更加明显 。这使得 UMAP 在实际应用中,特别是对于需要快速处理大量数据的场景,具有更高的实用价值 。
4. 应用案例与拓展
4.1 图像识别中的特征提取
在图像识别领域,流形学习展现出了强大的能力,尤其是在特征提取方面,为解决复杂的图像分类和识别问题提供了有效的途径 。传统的图像识别方法在面对高维的图像数据时,往往会遇到计算复杂度高、特征冗余等问题,而流形学习通过挖掘图像数据在低维流形上的内在结构,能够提取出更具判别性的低维特征,从而显著提升图像识别的性能 。
以人脸识别为例,人脸图像在高维空间中存在着复杂的非线性结构,不同个体的人脸图像以及同一人脸在不同表情、姿态和光照条件下的图像,在高维空间中呈现出多样化的分布 。流形学习算法如 Isomap,可以通过计算不同人脸图像之间的测地距离,构建一个能够反映人脸图像全局结构的距离矩阵 。然后,利用经典的多维尺度分析(MDS)方法,将这些测地距离映射到低维空间,实现对人脸图像的降维 。在这个低维空间中,相似的人脸图像(如同一个人的不同表情图像)会聚集在一起,不同人的人脸图像则会相互分离,从而清晰地展现出不同人脸之间的相似性和差异性 。这样提取出的低维特征,能够更好地代表人脸的本质特征,提高人脸识别的准确率 。
在图像分类任务中,流形学习同样发挥着重要作用 。对于包含多种物体类别的图像数据集,原始的高维图像特征可能包含大量的噪声和冗余信息,使得分类器难以准确地学习到不同类别之间的边界 。通过使用流形学习算法,如局部线性嵌入(LLE),可以将高维的图像数据映射到低维空间,同时保持数据的局部线性结构 。在低维空间中,同一类别的图像数据点会形成紧密的簇,不同类别的图像数据点之间则有明显的间隔,这使得分类器能够更容易地学习到不同类别之间的特征差异,从而提高图像分类的准确性 。例如,在对花卉图像进行分类时,LLE 算法可以提取出花朵的形状、颜色等关键特征的低维表示,使得分类器能够准确地区分不同种类的花卉 。
4.2 生物信息学中的基因数据分析
生物信息学中的基因表达数据通常具有极高的维度和复杂的结构,流形学习在分析这些数据时发挥着关键作用,能够揭示隐藏在基因数据背后的生物模式,为生物医学研究提供重要的线索 。
在基因表达数据分析中,不同细胞状态下的基因表达数据构成了高维空间中的复杂分布 。例如,在研究癌症相关的基因表达时,正常细胞和癌细胞的基因表达谱在高维空间中存在着复杂的非线性关系 。Isomap 算法可以帮助研究人员找到这些基因表达数据在低维流形上的分布规律 。通过构建基因表达数据点之间的近邻图,并计算测地距离,Isomap 能够将高维的基因表达数据映射到低维空间,使得正常细胞和癌细胞的基因表达数据在低维空间中能够明显地区分开来 。这有助于研究人员发现与癌症发生发展相关的关键基因,以及不同细胞状态之间的潜在联系,为癌症的诊断和治疗提供重要的依据 。
局部线性嵌入(LLE)算法则可以从局部角度分析基因之间的相互作用关系 。它假设每个基因的表达可以由其邻域内的其他基因的线性组合来近似表示,通过计算局部线性重构权重,LLE 能够在低维空间中保持这种局部线性关系 。在分析基因调控网络时,LLE 可以挖掘出对细胞功能和疾病发生发展起关键作用的基因模块 。例如,在研究神经退行性疾病时,LLE 算法可以帮助识别出与神经细胞功能相关的基因模块,以及这些基因模块在疾病状态下的变化,从而深入理解神经退行性疾病的发病机制 。
4.3 其他潜在应用领域
除了图像识别和生物信息学,流形学习在语音处理、社会科学数据分析等领域也展现出了潜在的应用价值 。
在语音处理中,语音信号通常被表示为高维的特征向量,流形学习可以用于提取语音信号的低维特征,从而提高语音识别和语音合成的性能 。例如,t-SNE 算法可以将高维的语音特征向量映射到二维或三维空间,用于可视化不同语音类别(如不同的语音命令、不同说话人的语音等)在低维空间中的分布情况 。通过这种可视化,研究人员可以更好地理解语音信号的内在结构,发现语音特征之间的潜在关系,从而改进语音识别模型的性能 。在语音合成中,流形学习可以帮助生成更加自然流畅的语音,通过学习语音数据的低维流形结构,能够更好地捕捉语音的韵律、音高和音色等特征,从而提高合成语音的质量 。
在社会科学数据分析中,流形学习也有广阔的应用前景 。例如,在分析社交网络数据时,流形学习可以用于挖掘用户之间的潜在关系和社区结构 。社交网络中的用户可以看作是高维空间中的数据点,用户之间的关系(如关注、点赞、评论等)可以作为数据点之间的连接 。通过构建邻域图并应用流形学习算法,如 UMAP,可以将高维的社交网络数据映射到低维空间,在低维空间中,具有相似兴趣和行为的用户会聚集在一起,形成不同的社区 。这有助于研究人员分析社交网络的结构和动态,理解信息在社交网络中的传播规律,为市场营销、舆情分析等提供有价值的信息 。在经济学领域,流形学习可以用于分析宏观经济数据,发现经济指标之间的潜在关系,预测经济趋势 。例如,将多个经济指标(如 GDP、通货膨胀率、失业率等)看作高维数据点,通过流形学习算法可以找到这些指标在低维流形上的分布规律,从而更好地理解经济系统的运行机制,为经济政策的制定提供参考 。
5. 总结与展望
5.1 流形学习的优势与不足
流形学习作为一种强大的非线性降维技术,在数据处理和分析领域展现出了诸多显著的优势 。首先,流形学习能够有效处理非线性数据,挖掘其内在的低维结构 。与传统的线性降维方法(如主成分分析 PCA)不同,流形学习假设数据分布在低维流形上,通过探索数据点之间的局部和全局几何关系,能够发现隐藏在高维数据中的复杂结构和模式 。在图像识别中,流形学习可以提取出更具判别性的低维特征,从而提高图像分类和识别的准确率 。在生物信息学中,它能够揭示基因表达数据中的潜在关系,为生物医学研究提供重要线索 。
其次,流形学习在数据可视化方面表现出色 。通过将高维数据映射到二维或三维空间,流形学习算法如 t-SNE 和 UMAP 可以直观地展示数据的分布情况,帮助研究人员更好地理解数据的内在结构和规律 。在手写数字数据集的可视化中,t-SNE 能够将不同数字类别的数据点在二维空间中清晰地分离开来,使得我们可以直观地观察到不同数字之间的差异和相似性 。
然而,流形学习也存在一些不足之处 。其中一个主要问题是计算复杂度较高 。许多流形学习算法,如 Isomap 和 LLE,在构建邻域图和计算低维嵌入时需要进行大量的矩阵运算,这使得它们在处理大规模数据时计算成本高昂,运行时间较长 。在处理包含数百万个数据点的图像数据集时,这些算法可能需要数小时甚至数天的时间才能完成降维操作 。此外,流形学习算法对数据的噪声和离群点比较敏感 。由于算法通常依赖于数据点之间的局部几何关系,噪声和离群点可能会干扰邻域图的构建,从而影响低维嵌入的准确性和稳定性 。在实际应用中,需要对数据进行预处理,去除噪声和离群点,以提高流形学习算法的性能 。
5.2 未来研究方向
为了克服流形学习现有的不足,并进一步拓展其应用领域,未来的研究可以从以下几个方向展开 。首先,流形学习与深度学习的结合是一个极具潜力的研究方向 。深度学习在特征提取和模式识别方面表现出了强大的能力,但在处理高维数据和复杂结构时仍面临挑战 。将流形学习的思想融入深度学习模型中,可以帮助深度学习更好地理解数据的内在结构,提高模型的泛化能力和鲁棒性 。可以将流形学习算法作为深度学习模型的预处理步骤,对数据进行降维处理,减少模型的计算负担;或者将流形学习的损失函数引入深度学习模型的训练过程中,使得模型在学习过程中能够更好地保持数据的几何结构 。在图像生成任务中,结合流形学习和生成对抗网络(GAN),可以生成更加真实和多样化的图像 。
其次,针对大规模数据的处理,研究高效的流形学习算法也是未来的重要研究方向之一 。随着数据量的不断增长,传统的流形学习算法在计算效率上的不足愈发凸显 。因此,需要开发新的算法和技术,以提高流形学习在大规模数据上的处理能力 。这可以包括研究分布式计算和并行计算技术在流形学习中的应用,将大规模数据划分为多个子数据集,在多个计算节点上并行地进行流形学习计算,从而加快计算速度 。还可以探索基于采样的方法,从大规模数据中选取代表性的样本进行流形学习,减少计算量的同时尽可能保留数据的关键信息 。
此外,流形学习在更多领域的应用拓展也是未来研究的重点 。除了已经广泛应用的图像识别、生物信息学等领域,流形学习在自然语言处理、金融数据分析、物联网等领域也有很大的应用潜力 。在自然语言处理中,流形学习可以用于文本分类、情感分析、语义理解等任务,帮助挖掘文本数据中的潜在语义结构 。在金融数据分析中,流形学习可以用于风险评估、股票价格预测等,通过分析金融数据的内在结构,提高预测的准确性和可靠性 。随着技术的不断发展和研究的深入,相信流形学习将在更多领域发挥重要作用,为解决各种复杂的实际问题提供有力的支持 。


















 1895
1895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











