




目录
一、Oracle 初印象
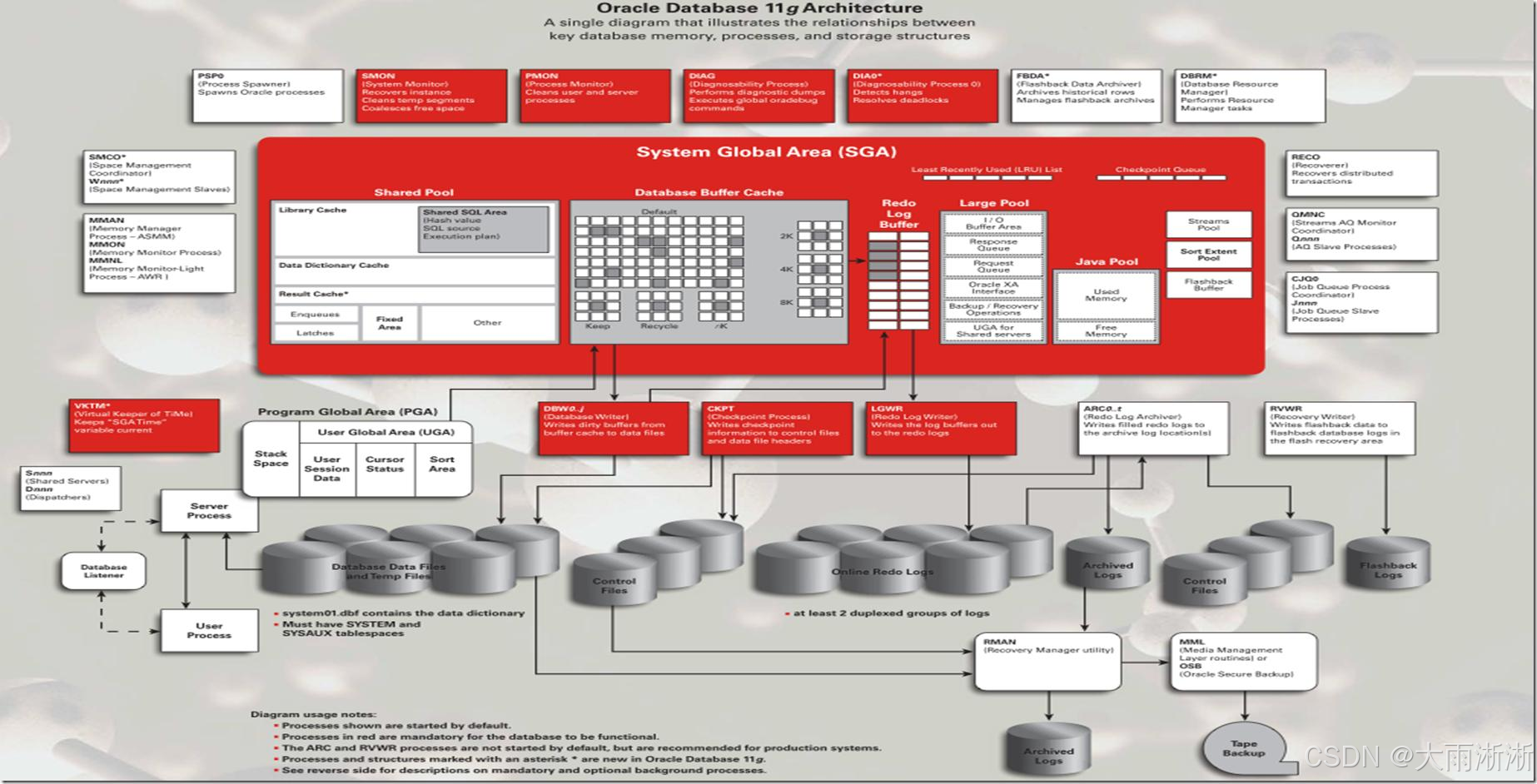
在数据库的广阔天地中,Oracle 堪称一位声名远扬的 “巨星”。自 1979 年首款商业化 SQL 关系数据库管理系统诞生以来,Oracle 便在数据库领域一路披荆斩棘,凭借不断革新的技术和强大稳定的性能,逐渐成为全球数据库市场的中流砥柱 。它广泛应用于金融、电信、政府、医疗等众多关键领域,承担着数据存储、管理与处理的重任,许多大型企业的核心业务系统都离不开它的支持。
Oracle 之所以备受青睐,稳定性是其一大王牌。面对海量数据和高并发的业务场景,它能够始终如一地保持高效运行,确保数据的完整性和一致性。就像一家大型银行,每天要处理数以万计的交易,Oracle 数据库可以稳定地记录每一笔账目,保证资金流转信息准确无误,即使在交易高峰时段也不会出现卡顿或数据丢失的情况。
强大的安全性也是 Oracle 的显著优势。在信息安全至关重要的今天,它提供了多层次的安全防护机制,从用户身份验证、权限管理到数据加密,全方位保障数据不被非法访问和篡改。在医疗行业,患者的个人隐私和病历数据极其敏感,Oracle 数据库的安全特性能够有效防止这些数据泄露,为患者信息安全保驾护航。
此外,Oracle 具备高度的可扩展性,无论是小型初创企业,还是业务庞大的跨国集团,都能根据自身发展需求,灵活地对数据库进行扩展,轻松应对不断增长的数据量和业务复杂度。
这样一款卓越的数据库系统,蕴含着丰富的知识与技术。接下来,就让我们一起踏上探索 Oracle 的奇妙之旅,从基础概念到实战应用,逐步揭开它神秘的面纱。
二、开启学习之门:环境搭建
在正式开启 Oracle 数据库的学习旅程前,搭建一个稳定且合适的学习环境是至关重要的第一步。这就好比建造房屋,稳固的地基是房屋安全与坚固的保障,良好的学习环境则是我们深入学习 Oracle 知识的基石。下面将为大家详细介绍在 Windows 系统下 Oracle 数据库的下载与安装步骤,以及安装过程中不可忽视的注意事项。
(一)下载 Oracle 安装文件
- 访问 Oracle 官方网站(https://www.oracle.com/database/) ,这是获取正版 Oracle 数据库软件的权威来源。网站界面可能会随着时间更新,但通常在首页就能找到明显的 “下载” 或 “Downloads” 相关链接。
- 由于 Oracle 数据库版本众多,如 Oracle Database 19c、Oracle Database 21c 等,我们需要根据自身学习需求和计算机配置选择合适的版本。如果是初学者进行学习和测试,当前较新且应用广泛的版本如 19c 就很合适,它在功能和稳定性上都有不错的表现。
- 若你是首次访问该网站下载软件,可能需要注册或登录 Oracle 账户。注册过程并不复杂,按照页面提示填写必要的信息,如邮箱、用户名、密码等完成注册。登录后,即可在下载页面找到对应的 Oracle 数据库版本下载选项。下载的文件一般是压缩包格式,如.zip 文件。例如,下载 Oracle Database 19c 时,可能会得到两个或多个压缩包文件,它们共同构成完整的安装文件。
(二)解压安装文件
- 在计算机磁盘中选择一个合适的解压目录,比如在 C 盘根目录下创建一个名为 “OracleInstall” 的文件夹。解压目录的选择要考虑磁盘空间和文件管理的便利性,确保所选磁盘分区有足够的剩余空间来存放解压后的文件,一般建议预留至少 10GB 以上的空间。
- 找到下载的 Oracle 安装压缩包文件,右键点击选择 “解压到当前文件夹” 或类似的解压选项(具体选项名称可能因使用的解压软件不同而略有差异,常见的解压软件如 WinRAR、360 压缩等都具备基本的解压功能)。解压过程可能需要一些时间,耐心等待解压完成。解压完成后,在解压目录中会出现众多文件和文件夹,这些就是安装 Oracle 数据库所需的文件。
(三)运行安装程序
- 进入解压后的文件夹,找到名为 “setup.exe” 的文件,它就是 Oracle 数据库的安装启动程序,通常显示为一个带有 Oracle 标志的图标。双击 “setup.exe” 文件,启动安装向导。
- 在安装向导的初始界面,可能会提示你选择安装类型,常见的有 “桌面类” 和 “服务器类”。对于个人学习和测试场景,“桌面类” 安装是比较合适的选择。它的安装过程相对简单,配置选项较少,更适合初学者快速搭建起学习环境。而 “服务器类” 安装则适用于生产环境或多用户环境,会提供更多高级的配置选项,如数据库存储位置的详细设置、字符集的深度定制等,但安装和配置过程也更为复杂。
(四)配置安装选项
- 选择安装位置:在安装过程中,会要求指定 Oracle 软件的安装目录。默认情况下,安装程序可能会给出一个建议路径,如 “C:\app\Oracle\product\19.0.0\dbhome_1”(这里以 Oracle Database 19c 为例)。在选择安装路径时,要注意路径中不要包含中文、空格或其他特殊字符,因为这些字符可能会导致安装或后续使用过程中出现兼容性问题。同时,要确保安装目录所在的磁盘分区有足够的空间,不仅要考虑 Oracle 软件本身的安装空间需求,还要预留出足够的空间用于存放数据库文件、日志文件等后续产生的数据文件,随着学习和使用中数据量的增加,这些文件可能会占用较大的磁盘空间。
- 配置数据库选项:此时可以选择创建数据库或者仅安装软件。如果是为了学习和实践 Oracle 数据库的各种功能,建议选择创建数据库。在创建数据库时,需要配置一些关键参数:
-
- 数据库名称:可以使用默认的全局数据库名,也可以根据自己的喜好进行修改,但要注意命名规则,一般由字母、数字组成,不能以数字开头,且不能包含特殊字符。例如,可以将全局数据库名设置为 “orcl”。
-
- 数据库字符集:字符集的选择非常重要,它决定了数据库能够存储和处理的字符类型。UTF - 8 是一种广泛使用的字符集,它支持几乎所有的语言字符,具有良好的通用性和兼容性。在学习过程中,选择 UTF - 8 字符集可以避免很多因字符编码问题导致的数据存储和显示异常。
-
- 存储参数:需要指定数据文件的大小和位置。数据文件是存储数据库实际数据的文件,其大小可以根据预计存储的数据量进行合理设置。初始设置时,可以参考 Oracle 官方文档的建议值,后续也可以根据实际使用情况进行调整。数据文件的存储位置同样要选择在磁盘空间充足且读写性能较好的分区,并且要注意文件路径的规范性,避免出现路径错误。
- 设置管理员密码:为系统管理员账户(如 SYS 和 SYSTEM)设置密码。密码应足够复杂,包含字母(大写和小写)、数字和特殊字符,长度建议在 8 位以上,以提高账户的安全性。同时,务必牢记设置的密码,因为后续管理数据库,如登录数据库进行各种操作、修改数据库配置等都需要使用该密码。如果忘记密码,找回密码的过程可能会比较复杂,甚至可能导致数据丢失或系统无法正常运行。
(五)安装过程
确认上述安装选项后,安装程序会开始解压和安装文件。这个过程可能需要较长时间,具体时长取决于计算机的性能,如 CPU 处理速度、内存大小、磁盘读写速度等。在安装过程中,计算机的 CPU 和磁盘 I/O 可能会占用较高,此时尽量不要进行其他占用系统资源较大的操作,以免影响安装进度或导致安装失败。安装程序可能会提示运行一些脚本或者执行一些配置步骤,务必按照提示逐步操作。这些脚本和配置步骤对于完成数据库的安装和初始化至关重要,它们会完成如创建数据库实例、配置数据库服务、设置系统环境变量等一系列操作。
(六)完成安装并验证
- 安装完成后,安装程序会显示安装成功的提示信息。此时,可以通过以下方式验证 Oracle 数据库是否安装成功:
-
- 打开命令提示符(CMD),在命令行中输入 “sqlplus /as sysdba”。如果是在 Linux 或 Unix 系统下,则使用相应的终端命令。然后输入之前设置的管理员密码。如果能够成功登录到 SQLPlus 命令行界面,说明数据库的基本安装和配置是正确的。在 SQLPlus 命令行界面中,可以进一步执行一些简单的查询语句,如 “select * from v$version;”,该语句用于查看数据库的版本信息。如果能够正确显示出版本信息,如 Oracle Database 19c Release 19.0.0.0.0 - Production 等,则更充分地验证了数据库安装成功。
-
- 还可以通过查看 Oracle 相关的服务是否正常启动来验证。在 Windows 系统中,可以通过 “服务” 管理界面(在 “运行” 中输入 “services.msc” 并回车即可打开),找到以 “Oracle” 开头的服务,如 “OracleServiceORCL”(这里的 “ORCL” 是数据库实例名,根据安装时的设置可能会不同)和 “OracleOraDb19c_home1TNSListener”(监听服务)等。确保这些服务的状态为 “已启动”,如果服务未启动,可以手动启动它们。如果服务无法正常启动,可能是安装过程中出现了问题,需要根据错误提示进行排查和解决。常见的问题包括端口冲突、系统环境变量配置错误、安装文件损坏等。
(七)安装过程中的注意事项
- 端口冲突:Oracle 数据库默认使用一些端口进行通信,其中最常见的是 1521 端口用于监听客户端连接。如果在安装过程中提示端口冲突,说明当前计算机上已经有其他程序在使用该端口。解决方法如下:
-
- 可以通过修改 Oracle 的监听配置文件来更改监听端口。在 Windows 系统中,监听配置文件通常位于 “ORACLE_HOME\network\admin” 目录下,文件名为 “listener.ora”(其中 “ORACLE_HOME” 是指 Oracle 的安装目录,根据实际安装路径可能会有所不同)。在 Linux 系统中,路径类似,如 “/u001/app/oracle/product/19.0.0/dbhome_1/network/admin/listener.ora”(以 Oracle Database 19c 为例)。打开 “listener.ora” 文件,找到关于端口号的配置项,将其修改为一个未被占用的端口号,如 1522。修改完成后,保存文件,并重新启动监听服务。在 Windows 系统中,可以在 “服务” 管理界面中找到 “OracleOraDb19c_home1TNSListener” 服务,右键点击选择 “重启”;在 Linux 系统中,可以使用命令 “lsnrctl stop” 停止监听服务,修改文件后再使用 “lsnrctl start” 启动监听服务。
-
- 也可以通过检查占用端口的程序,判断是否可以停止或修改该程序的端口设置来解决冲突。在 Windows 系统中,可以使用命令 “netstat -an | find "1521"” 来查看占用 1521 端口的程序及相关信息;在 Linux 系统中,可以使用 “netstat -anp | grep 1521” 命令。如果发现占用端口的程序是一些非必要的临时程序,可以停止该程序,释放端口供 Oracle 使用;如果是重要程序且无法停止,可以考虑修改该程序的端口设置,使其不再占用 1521 端口。
- 路径选择:如前文所述,安装路径不能包含中文、空格或其他特殊字符。此外,还要考虑磁盘空间和性能因素。选择磁盘空间充足的分区进行安装,避免在安装过程中或后续使用中因磁盘空间不足导致安装失败或数据库运行异常。同时,尽量选择读写性能较好的磁盘分区,如 SSD 固态硬盘分区,以提高数据库的读写速度和整体性能。如果安装在老旧的机械硬盘上,可能会因为磁盘读写速度较慢,导致数据库操作响应时间变长,影响学习和使用体验。
- 安装文件完整性:下载安装文件时,要确保网络稳定,避免下载过程中断。如果下载的安装文件损坏,可能会导致安装程序无法启动或在安装过程中出现各种错误。可以通过对比下载文件的大小与官方提供的文件大小是否一致,以及查看文件的哈希值(如果官方提供)来验证文件的完整性。如果发现文件损坏,应重新下载安装文件。在重新下载时,选择网络环境较好的时间段和稳定的网络连接,以确保下载过程顺利完成。
- 系统兼容性:在安装前,要确保计算机的操作系统版本符合 Oracle 数据库的要求。例如,Oracle Database 19c 支持 Windows Server 2016、Windows Server 2019 以及 Windows 10 等操作系统版本。如果操作系统版本不兼容,可能会导致安装失败或数据库运行不稳定。同时,还要检查系统是否安装了必要的组件和依赖项,如在 Windows 系统中,不同版本的 Oracle 可能对.NET Framework 有不同的要求,需要根据 Oracle 官方文档的说明,安装相应版本的.NET Framework 组件。
通过以上详细的步骤和注意事项,相信大家能够顺利地完成 Oracle 数据库的安装,为后续的学习和实践打下坚实的基础。
三、SQL 语句基础
在 Oracle 数据库的学习旅程中,SQL 语句无疑是我们与数据库进行交互的关键工具。它就像是一把万能钥匙,能够开启数据库中各种数据操作的大门。SQL 语句主要分为数据定义语言(DDL)、数据操作语言(DML)、数据查询语言(DQL)和数据控制语言(DCL),每一类语句都有着独特的功能和用途,下面我们就来深入了解一下。
(一)数据定义语言(DDL)
数据定义语言(DDL)主要用于创建、修改和删除数据库对象,这些对象包括表、视图、索引等,它们是构成数据库的基本元素。比如在一家电商企业的数据库中,需要创建 “商品表” 来存储商品信息,“订单表” 来记录订单数据,这些表的创建就依赖于 DDL 语句。
- CREATE 语句:用于创建各种数据库对象。以创建表为例,其基本语法为:
CREATE TABLE 表名 (
列1 数据类型 [约束条件],
列2 数据类型 [约束条件],
......
);
例如,创建一个名为 “employees” 的员工表,包含员工编号(employee_id)、姓名(employee_name)、工资(salary)等字段,并为员工编号设置主键约束,确保每个员工的编号唯一且不能为空:
CREATE TABLE employees (
employee_id NUMBER(10) PRIMARY KEY,
employee_name VARCHAR2(50),
salary NUMBER(10, 2)
);
在这个例子中,“NUMBER (10)” 表示员工编号是一个最多 10 位的数字类型,“VARCHAR2 (50)” 表示姓名是一个可变长度的字符串类型,最大长度为 50 个字符,“NUMBER (10, 2)” 表示工资是一个最多 10 位,其中小数部分占 2 位的数字类型。
- ALTER 语句:用于修改已存在的数据库对象的结构。比如向 “employees” 表中添加一个新的字段 “hire_date”,表示员工的入职日期,可以使用以下语句:
ALTER TABLE employees
ADD hire_date DATE;
如果要修改某个字段的数据类型,例如将 “salary” 字段的数据类型改为 “NUMBER (12, 2)”,可以这样操作:
ALTER TABLE employees
MODIFY salary NUMBER(12, 2);
- DROP 语句:用于删除数据库对象。若要删除 “employees” 表,可以执行以下语句:
DROP TABLE employees;
需要注意的是,使用 DROP 语句删除对象时要格外谨慎,因为一旦执行,相关对象及其数据将被永久删除,无法恢复。
(二)数据操作语言(DML)
数据操作语言(DML)主要用于对数据库中的数据进行插入、更新和删除操作,它直接影响数据库中存储的数据内容。
- INSERT 语句:用于向表中插入新的数据行。基本语法有两种常见形式:
-
- 插入所有列的数据:
INSERT INTO 表名 VALUES (值1, 值2,......);
例如,向 “employees” 表中插入一条员工记录:
INSERT INTO employees VALUES (1, '张三', 5000.00, TO_DATE('2023 - 01 - 01', 'YYYY - MM - DD'));
这里使用TO_DATE函数将字符串 '2023 - 01 - 01' 转换为日期类型,以匹配 “hire_date” 字段的日期格式。
- 插入指定列的数据:
INSERT INTO 表名 (列1, 列2,......) VALUES (值1, 值2,......);
比如,只插入员工编号和姓名:
INSERT INTO employees (employee_id, employee_name) VALUES (2, '李四');
- UPDATE 语句:用于更新表中已存在的数据。语法为:
UPDATE 表名
SET 列1 = 值1, 列2 = 值2,......
[WHERE 条件];
例如,将员工编号为 1 的员工工资增加 1000:
UPDATE employees
SET salary = salary + 1000
WHERE employee_id = 1;
如果省略 WHERE 子句,会将表中所有记录的 “salary” 字段都进行更新,所以在使用 UPDATE 语句时,务必谨慎设置 WHERE 条件,确保只更新目标数据。
3. DELETE 语句:用于删除表中的数据行。语法为:
DELETE FROM 表名 [WHERE 条件];
例如,删除员工编号为 2 的员工记录:
DELETE FROM employees WHERE employee_id = 2;
同样,如果不写 WHERE 条件,会删除表中的所有数据,保留表结构,在执行删除操作时一定要确认好删除条件,避免误删数据。
(三)数据查询语言(DQL)
数据查询语言(DQL)中最核心的就是 SELECT 语句,它用于从数据库中检索数据,是我们获取所需信息的重要手段。SELECT 语句功能强大,用法丰富多样,可以进行简单查询,也能完成复杂的多表关联查询。
- 简单查询:查询表中的所有列数据,语法为:
SELECT * FROM 表名;
例如,查询 “employees” 表中的所有员工信息:
SELECT * FROM employees;
若只查询指定列,比如只查询员工姓名和工资:
SELECT employee_name, salary FROM employees;
- 条件查询:通过 WHERE 子句添加查询条件,筛选出符合特定条件的数据。例如,查询工资大于 8000 的员工信息:
SELECT * FROM employees WHERE salary > 8000;
还可以使用多种条件运算符,如等于(=)、不等于(<> 或!=)、大于(>)、小于(<)、大于等于(>=)、小于等于(<=),以及逻辑运算符 AND、OR、NOT 等进行复杂条件组合。比如,查询工资在 5000 到 8000 之间(包括 5000 和 8000)的员工信息:
SELECT * FROM employees WHERE salary BETWEEN 5000 AND 8000;
- 分组查询:使用 GROUP BY 子句将查询结果按照指定列进行分组,通常会结合聚合函数(如 SUM、AVG、COUNT、MAX、MIN 等)一起使用。例如,统计每个部门的员工人数:
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id;
这里COUNT(*)用于统计每个分组中的记录数,AS employee_count为统计结果起了一个别名 “employee_count”,方便查看结果。
4. 连接查询:当需要从多个相关表中获取数据时,就会用到连接查询。连接类型主要有内连接(INNER JOIN)、左外连接(LEFT JOIN)、右外连接(RIGHT JOIN)和全外连接(FULL JOIN)。以内连接为例,假设存在 “departments” 表,存储部门信息,包含部门编号(department_id)和部门名称(department_name),现在要查询每个员工所属的部门名称,可以使用内连接:
SELECT e.employee_name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id;
这条语句通过 “e.department_id = d.department_id” 条件将 “employees” 表和 “departments” 表进行关联,查询出每个员工对应的部门名称。
(四)数据控制语言(DCL)
数据控制语言(DCL)主要用于管理数据库用户的权限,确保数据库的安全性和数据访问的合理性。通过 DCL 语句,可以决定哪些用户能够执行哪些数据库操作,就像给不同的人分配不同权限的钥匙,允许他们在授权范围内访问和操作数据库资源。
- GRANT 语句:用于赋予用户权限。权限类型包括系统权限和对象权限。系统权限允许用户执行特定的数据库操作,如创建会话(CREATE SESSION)、创建表(CREATE TABLE)等;对象权限则针对特定的数据库对象,如对表的查询(SELECT)、插入(INSERT)、更新(UPDATE)、删除(DELETE)权限等。
-
- 赋予系统权限,例如创建一个新用户 “test_user”,并赋予其创建会话和创建表的权限:
CREATE USER test_user IDENTIFIED BY test_password;
GRANT CREATE SESSION, CREATE TABLE TO test_user;
- 赋予对象权限,假设 “test_user” 需要对 “employees” 表有查询和插入权限:
GRANT SELECT, INSERT ON employees TO test_user;
- REVOKE 语句:用于收回用户已被赋予的权限。比如,要收回 “test_user” 对 “employees” 表的插入权限:
REVOKE INSERT ON employees FROM test_user;
通过合理运用 GRANT 和 REVOKE 语句,可以灵活地管理用户对数据库的访问权限,保障数据库的安全稳定运行 。在实际应用中,权限管理至关重要,不同的用户角色应被授予与其工作职责相匹配的权限,避免权限过大导致数据安全风险,或权限不足影响业务正常开展。
四、深入探索:PL/SQL 编程
(一)语法基础
PL/SQL 是 Oracle 对 SQL 语言的过程化扩展,它将 SQL 与过程化编程结构相结合,使得我们能够编写更复杂、功能更强大的数据库程序。PL/SQL 程序以块(block)为基本单位,一个完整的 PL/SQL 块由三个主要部分组成:声明部分(Declaration)、执行部分(Execution)和异常处理部分(Exception Handling) 。
- 声明部分:这部分以关键字DECLARE开头,用于声明在 PL/SQL 块中使用的变量、常量、游标、自定义数据类型等。声明部分是可选的,如果不需要声明任何内容,可以省略。例如,声明一个整型变量num和一个字符串变量name:
DECLARE
num NUMBER;
name VARCHAR2(50);
BEGIN
-- 执行部分代码
END;
- 执行部分:以关键字BEGIN开始,是 PL/SQL 块的主体部分,包含了要执行的 SQL 语句和 PL/SQL 语句,如数据操作、流程控制等。执行部分是必需的,至少要有一条可执行语句。比如给上述声明的变量赋值并输出:
DECLARE
num NUMBER;
name VARCHAR2(50);
BEGIN
num := 10;
name := '张三';
DBMS_OUTPUT.PUT_LINE('数字: ' || num || ', 姓名: ' || name);
END;
这里使用了DBMS_OUTPUT.PUT_LINE过程来输出变量的值,需要注意的是,在 SQL*Plus 中使用该过程前,需要先执行SET SERVEROUTPUT ON语句开启输出功能。
3. 异常处理部分:以关键字EXCEPTION开头,用于捕获和处理在执行部分可能出现的异常情况。这部分也是可选的。当执行部分的语句发生错误时,程序会跳转到异常处理部分进行处理。例如,处理可能出现的除零错误:
DECLARE
num1 NUMBER := 10;
num2 NUMBER := 0;
result NUMBER;
BEGIN
result := num1 / num2;
DBMS_OUTPUT.PUT_LINE('结果: ' || result);
EXCEPTION
WHEN ZERO_DIVIDE THEN
DBMS_OUTPUT.PUT_LINE('错误:除数不能为零');
END;
在这个例子中,如果num2为零,执行result := num1 / num2;时会触发ZERO_DIVIDE异常,程序会跳转到WHEN ZERO_DIVIDE分支进行处理,输出错误提示信息。
(二)变量与数据类型
- 变量定义与赋值:在 PL/SQL 中,变量必须先声明后使用。声明变量时需要指定变量的数据类型,常见的声明语法为变量名 数据类型 [:=初始值]; 。例如:
DECLARE
-- 声明一个整型变量并初始化为10
count NUMBER := 10;
-- 声明一个字符串变量
message VARCHAR2(100);
BEGIN
-- 给字符串变量赋值
message := '这是一条测试消息';
DBMS_OUTPUT.PUT_LINE('计数: ' || count || ', 消息: ' || message);
END;
变量的赋值可以在声明时进行初始化,也可以在执行部分通过赋值语句(:=)进行。
2. 作用域:变量的作用域是指变量在程序中有效的范围。在 PL/SQL 块中声明的变量,其作用域从声明处开始,到该 PL/SQL 块结束。如果在嵌套块中声明了与外层块同名的变量,内层块中的变量会覆盖外层块的变量。例如:
DECLARE
num NUMBER := 100; -- 外层块变量
BEGIN
DBMS_OUTPUT.PUT_LINE('外层块变量num: ' || num);
DECLARE
num NUMBER := 200; -- 内层块变量,覆盖外层块的num
BEGIN
DBMS_OUTPUT.PUT_LINE('内层块变量num: ' || num);
END;
DBMS_OUTPUT.PUT_LINE('回到外层块,变量num: ' || num);
END;
上述代码中,在内层块中声明的num变量仅在内层块有效,当离开内层块后,使用的仍然是外层块的num变量。
3. 常用数据类型:
- 数值型:NUMBER是最常用的数值类型,可以表示整数和浮点数,定义时可以指定精度和小数位数,如NUMBER(10, 2)表示总位数为 10 位,其中小数部分占 2 位的数值。还有PLS_INTEGER和BINARY_INTEGER,它们表示有符号整数,范围在 -2147483648 到 2147483647 之间,PLS_INTEGER在执行算术运算时如果发生溢出会引发异常,而BINARY_INTEGER在溢出时会截断结果。
- 字符型:VARCHAR2用于存储可变长度的字符串,需要指定最大长度,如VARCHAR2(50)表示最大长度为 50 个字符的字符串;CHAR用于存储固定长度的字符串,无论实际存储的字符数多少,都会占用指定的长度,例如CHAR(10),如果存储的字符串不足 10 个字符,会用空格填充。
- 日期型:DATE类型用于存储日期和时间,精确到秒,范围从公元前 4712 年至公元 9999 年。可以使用TO_DATE函数将字符串转换为DATE类型,例如TO_DATE('2024 - 01 - 01', 'YYYY - MM - DD') 。还有TIMESTAMP类型,它比DATE类型具有更高的时间精度,可以精确到小数秒。
(三)流程控制语句
- IF - THEN - ELSE 语句:用于条件判断,根据条件的真假执行不同的代码块。基本语法有三种形式:
-
- 简单的 IF 语句:
IF 条件 THEN
语句;
END IF;
例如,判断一个数是否大于 10:
DECLARE
num NUMBER := 15;
BEGIN
IF num > 10 THEN
DBMS_OUTPUT.PUT_LINE(num || ' 大于 10');
END IF;
END;
- IF - ELSE 语句:
IF 条件 THEN
语句1;
ELSE
语句2;
END IF;
比如判断一个数是奇数还是偶数:
DECLARE
num NUMBER := 7;
BEGIN
IF MOD(num, 2) = 0 THEN
DBMS_OUTPUT.PUT_LINE(num || ' 是偶数');
ELSE
DBMS_OUTPUT.PUT_LINE(num || ' 是奇数');
END IF;
END;
这里使用了MOD函数来计算余数,判断num是否能被 2 整除。
- IF - ELSIF - ELSE 语句:用于多条件判断。
IF 条件1 THEN
语句1;
ELSIF 条件2 THEN
语句2;
...
ELSE
语句n;
END IF;
例如,根据学生成绩判断等级:
DECLARE
score NUMBER := 85;
BEGIN
IF score >= 90 THEN
DBMS_OUTPUT.PUT_LINE('成绩等级为 A');
ELSIF score >= 80 THEN
DBMS_OUTPUT.PUT_LINE('成绩等级为 B');
ELSIF score >= 60 THEN
DBMS_OUTPUT.PUT_LINE('成绩等级为 C');
ELSE
DBMS_OUTPUT.PUT_LINE('成绩等级为 D');
END IF;
END;
- CASE 语句:用于多分支选择,根据不同的条件值执行相应的代码块。语法有两种形式:
-
- 简单 CASE 语句:
CASE 表达式
WHEN 值1 THEN 结果1;
WHEN 值2 THEN 结果2;
...
ELSE 结果n;
END CASE;
比如根据星期几的数字显示对应的星期名称:
DECLARE
day_number NUMBER := 3;
day_name VARCHAR2(10);
BEGIN
CASE day_number
WHEN 1 THEN day_name := '星期一';
WHEN 2 THEN day_name := '星期二';
WHEN 3 THEN day_name := '星期三';
WHEN 4 THEN day_name := '星期四';
WHEN 5 THEN day_name := '星期五';
WHEN 6 THEN day_name := '星期六';
WHEN 7 THEN day_name := '星期日';
ELSE day_name := '无效的数字';
END CASE;
DBMS_OUTPUT.PUT_LINE('对应的星期是: ' || day_name);
END;
- 搜索 CASE 语句:
CASE
WHEN 条件1 THEN 结果1;
WHEN 条件2 THEN 结果2;
...
ELSE 结果n;
END CASE;
例如,根据员工工资范围给予不同的奖金:
DECLARE
salary NUMBER := 8000;
bonus NUMBER;
BEGIN
CASE
WHEN salary < 5000 THEN bonus := salary * 0.1;
WHEN salary < 8000 THEN bonus := salary * 0.15;
ELSE bonus := salary * 0.2;
END CASE;
DBMS_OUTPUT.PUT_LINE('奖金为: ' || bonus);
END;
- LOOP 语句:用于实现循环,重复执行一段代码。基本语法为:
LOOP
语句;
EXIT WHEN 条件; -- 当条件满足时退出循环
END LOOP;
例如,计算 1 到 10 的累加和:
DECLARE
i NUMBER := 1;
sum NUMBER := 0;
BEGIN
LOOP
sum := sum + i;
i := i + 1;
EXIT WHEN i > 10;
END LOOP;
DBMS_OUTPUT.PUT_LINE('1到10的累加和为: ' || sum);
END;
- FOR 语句:适用于已知循环次数的情况,循环变量会自动递增或递减。语法为:
FOR 循环变量 IN [REVERSE] 下限..上限 LOOP
语句;
END LOOP;
使用REVERSE关键字时,循环变量会从上限递减到下限。例如,输出 1 到 5 的数字:
BEGIN
FOR i IN 1..5 LOOP
DBMS_OUTPUT.PUT_LINE(i);
END LOOP;
END;
- WHILE 语句:根据条件判断是否继续循环,条件为真时执行循环体。语法为:
WHILE 条件 LOOP
语句;
END LOOP;
比如,当某个条件满足时循环执行操作:
DECLARE
num NUMBER := 1;
BEGIN
WHILE num < 10 LOOP
DBMS_OUTPUT.PUT_LINE(num);
num := num + 1;
END LOOP;
END;
(四)游标
- 概念和作用:游标(Cursor)是 PL/SQL 中用于处理查询结果集的一种机制。在 SQL 查询中,通常返回的是一个结果集,而游标可以将这个结果集逐行读取出来,以便进行更细致的处理,比如对每一行数据进行计算、更新等操作。游标主要用于需要逐行处理数据的场景,如报表生成、数据校验等。
- 显式游标和隐式游标:
-
- 显式游标:需要我们手动声明、打开、提取数据和关闭。声明显式游标时需要指定对应的查询语句。例如,查询员工表中所有员工的信息并逐行输出:
-- 创建员工表并插入示例数据
CREATE TABLE employees (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
salary NUMBER
);
INSERT INTO employees (employee_id, first_name, last_name, salary) VALUES (1, 'John', 'Doe', 5000);
INSERT INTO employees (employee_id, first_name, last_name, salary) VALUES (2, 'Jane', 'Smith', 6000);
INSERT INTO employees (employee_id, first_name, last_name, salary) VALUES (3, 'Alice', 'Brown', 7000);
COMMIT;
-- 使用显式游标
DECLARE
-- 声明游标
CURSOR emp_cursor IS
SELECT employee_id, first_name, last_name, salary
FROM employees;
-- 定义变量来存储游标提取的数据
v_employee_id employees.employee_id%TYPE;
v_first_name employees.first_name%TYPE;
v_last_name employees.last_name%TYPE;
v_salary employees.salary%TYPE;
BEGIN
-- 打开游标
OPEN emp_cursor;
LOOP
-- 提取游标中的数据到变量
FETCH emp_cursor INTO v_employee_id, v_first_name, v_last_name, v_salary;
-- 退出循环的条件:游标已提取完所有数据
EXIT WHEN emp_cursor%NOTFOUND;
-- 处理提取的数据
DBMS_OUTPUT.PUT_LINE('Employee ID: ' || v_employee_id || ', Name: ' || v_first_name || ' ' || v_last_name || ', Salary: ' || v_salary);
END LOOP;
-- 关闭游标
CLOSE emp_cursor;
END;
在这个例子中,首先声明了一个名为emp_cursor的游标,关联了查询employees表的语句。然后打开游标,通过FETCH语句逐行提取数据到定义的变量中,并在循环中处理数据,最后关闭游标释放资源。
- 隐式游标:由 PL/SQL 引擎自动创建和管理,用于处理单行查询结果,通常用于SELECT INTO语句。例如:
DECLARE
v_first_name employees.first_name%TYPE;
v_last_name employees.last_name%TYPE;
v_salary employees.salary%TYPE;
BEGIN
-- 使用隐式游标执行单行查询
SELECT first_name, last_name, salary
INTO v_first_name, v_last_name, v_salary
FROM employees
WHERE employee_id = 1;
-- 输出查询结果
DBMS_OUTPUT.PUT_LINE('Name: ' || v_first_name || ' ' || v_last_name || ', Salary: ' || v_salary);
END;
这里通过SELECT INTO语句查询employee_id为 1 的员工信息,PL/SQL 引擎自动创建隐式游标来处理这个查询,将查询结果直接赋值给对应的变量。
五、数据库管理与优化
(一)用户与权限管理
在 Oracle 数据库中,用户与权限管理是保障数据安全的重要防线。通过合理的用户管理,可以确保只有经过授权的人员能够访问和操作数据库中的数据,防止数据泄露和非法篡改。
创建用户是用户管理的基础操作。使用CREATE USER语句可以创建一个新用户,例如:
CREATE USER test_user IDENTIFIED BY test_password;
这条语句创建了一个名为test_user的用户,密码为test_password。在实际应用中,为了增强安全性,密码应设置得足够复杂,包含字母、数字和特殊字符,并且定期更换。
创建用户后,需要为其分配角色和权限,以确定用户能够执行的操作。角色是一组权限的集合,通过赋予用户角色,可以简化权限管理。例如,CONNECT角色允许用户连接到数据库,RESOURCE角色则赋予用户创建表、视图等数据库对象的权限。使用GRANT语句可以为用户授予角色和权限:
GRANT CONNECT, RESOURCE TO test_user;
除了角色权限,还可以授予用户具体的系统权限和对象权限。系统权限允许用户执行特定的数据库操作,如创建会话(CREATE SESSION)、创建表(CREATE TABLE)等;对象权限则针对特定的数据库对象,如对表的查询(SELECT)、插入(INSERT)、更新(UPDATE)、删除(DELETE)权限等。例如,授予test_user对employees表的查询和插入权限:
GRANT SELECT, INSERT ON employees TO test_user;
用户管理在数据库安全中起着举足轻重的作用。不同的用户角色应被授予与其工作职责相匹配的权限,避免权限过大导致数据安全风险,或权限不足影响业务正常开展。比如在一个企业的财务系统中,财务人员需要对财务数据进行查询、更新等操作,就应授予其相应的表的查询和更新权限;而普通员工可能只需要查询部分业务数据的权限,不应拥有修改数据的权限。定期审查和管理用户权限,及时收回不再需要的权限,也是保障数据库安全的重要措施。
(二)表空间与数据文件管理
表空间是 Oracle 数据库中一种重要的逻辑结构,它是数据库中数据文件的逻辑集合,用于存储数据库对象,如数据表、索引等。表空间与数据文件紧密相关,数据文件是实际存储数据的物理文件,一个表空间可以包含一个或多个数据文件 。
创建表空间是数据库管理的重要操作之一。使用CREATE TABLESPACE语句可以创建一个新的表空间,例如:
CREATE TABLESPACE user_tablespace
DATAFILE 'C:\oracle\data\user_tablespace.dbf' SIZE 100M
AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED;
这条语句创建了一个名为user_tablespace的表空间,数据文件为C:\oracle\data\user_tablespace.dbf,初始大小为 100MB,并且设置为自动扩展,每次扩展 10MB,最大扩展到无限制。在创建表空间时,还可以指定其他参数,如存储管理方式(EXTENT MANAGEMENT)、段空间管理方式(SEGMENT SPACE MANAGEMENT)等,以满足不同的业务需求。
修改表空间可以调整其属性和状态。例如,将表空间设置为只读模式,以防止数据被意外修改:
ALTER TABLESPACE user_tablespace READ ONLY;
如果需要增加表空间的大小,可以通过增加数据文件或扩大现有数据文件的方式来实现。增加数据文件的语句如下:
ALTER TABLESPACE user_tablespace
ADD DATAFILE 'C:\oracle\data\user_tablespace2.dbf' SIZE 50M;
删除表空间则使用DROP TABLESPACE语句,例如:
DROP TABLESPACE user_tablespace INCLUDING CONTENTS AND DATAFILES;
这条语句将删除user_tablespace表空间及其包含的所有内容和数据文件。在删除表空间时要格外谨慎,确保不会误删重要数据。
合理管理表空间和数据文件对于数据库的性能和稳定性至关重要。不同类型的数据可以存储在不同的表空间中,以提高数据访问效率和管理便利性。例如,将频繁访问的数据表和索引存储在不同的表空间中,避免 I/O 冲突;将临时数据存储在临时表空间中,减少对其他表空间的影响。定期检查表空间的使用情况,及时扩展或收缩表空间,确保数据库有足够的存储空间且不会浪费磁盘资源。
(三)备份与恢复
在数据库管理中,备份与恢复是至关重要的环节,它就像为数据库数据买了一份 “保险”,确保在数据遭遇丢失、损坏或其他意外情况时能够快速恢复,保障业务的连续性。Oracle 提供了多种备份与恢复方法,下面将详细介绍逻辑备份和物理备份方法,以及相关工具的使用。
- 逻辑备份:逻辑备份主要是对数据库中的逻辑组件,如表、存储过程等数据库对象进行备份。在 Oracle 中,常用的逻辑备份工具是EXPDP(Export Data Pump)。EXPDP是服务端的工具程序,它可以高效地导出数据库中的数据和元数据。
导出数据时,首先需要创建一个用于存放备份文件的目录,并授予相应的权限。例如,在 Linux 系统下,可以使用以下命令创建目录:
mkdir /backup/oracle
chown oracle:oinstall /backup/oracle
chmod 775 /backup/oracle
然后在 SQL*Plus 中创建逻辑目录并授权:
CREATE DIRECTORY backup_dir AS '/backup/oracle';
GRANT READ, WRITE ON DIRECTORY backup_dir TO your_username;
接下来就可以使用EXPDP进行数据导出了。例如,全量导出数据库的命令如下:
expdp system/password@your_service_name dumpfile=full_db.dmp directory=backup_dir full=y logfile=full_db.log
这条命令以system用户身份登录,将整个数据库导出到full_db.dmp文件中,存储在backup_dir目录下,并生成日志文件full_db.log。
如果只需要导出某个用户的所有对象,可以使用schemas参数,例如:
expdp user1/password@your_service_name schemas=user1 dumpfile=user1.dmp directory=backup_dir logfile=user1.log
导入数据时使用IMPDP(Import Data Pump)工具,它是EXPDP的配套工具,用于将导出的数据文件导入到数据库中。例如,全量导入数据库的命令如下:
impdp system/password@your_service_name directory=backup_dir dumpfile=full_db.dmp full=y
- 物理备份:物理备份是对数据库操作系统的物理文件,包括数据文件、控制文件和日志文件进行备份。RMAN(Recovery Manager)是 Oracle 提供的强大的物理备份和恢复工具,它可以在数据库运行时进行备份,并且支持多种备份策略,如全量备份、增量备份等。
使用RMAN进行全量备份的基本步骤如下:
首先,需要启动RMAN并连接到目标数据库,例如在 Linux 系统下,可以使用以下命令启动RMAN:
rman target /
然后执行全量备份命令:
BACKUP DATABASE;
这条命令会对整个数据库进行全量备份,备份文件会存储在默认的备份位置,或者根据配置存储在指定的位置。
增量备份则只备份自上次备份以来更改的数据,这样可以减少备份的数据量和备份时间。例如,进行增量备份的命令如下:
BACKUP INCREMENTAL LEVEL 1 DATABASE;
这里的LEVEL 1表示一级增量备份,它会备份自上次全量备份或一级增量备份以来更改的数据。
在恢复数据时,如果是基于物理备份的恢复,当数据库出现故障时,可以使用RMAN进行恢复。例如,当数据文件损坏时,可以使用以下命令进行恢复:
RESTORE DATAFILE 'datafile_path';
RECOVER DATAFILE 'datafile_path';
RESTORE命令用于从备份中恢复数据文件,RECOVER命令用于应用归档日志和联机重做日志,将数据文件恢复到故障前的状态。
备份与恢复策略应根据业务需求和数据重要性进行合理制定。对于关键业务数据库,可能需要每天进行全量备份,并在业务高峰期间进行多次增量备份,以确保数据的安全性和可恢复性。同时,定期进行备份验证,模拟数据丢失场景进行恢复测试,确保备份数据的有效性和恢复流程的正确性。
(四)性能优化
在 Oracle 数据库的管理与应用中,性能优化是一个永恒的主题。高效的数据库性能能够提升业务系统的响应速度,增强用户体验,为企业的稳定运营提供有力支持。下面将从 SQL 语句优化、索引优化、参数调整等方面深入阐述数据库性能优化策略。
- SQL 语句优化:SQL 语句是与数据库交互的核心,编写高效的 SQL 语句对于提升数据库性能至关重要。在编写 SQL 语句时,应尽量避免全表扫描,合理利用索引。例如,在查询语句中,确保WHERE子句中的条件能够使用索引,可以大大减少查询的数据量,提高查询效率。
-- 未使用索引的查询
SELECT * FROM employees WHERE UPPER(employee_name) = 'JOHN';
-- 优化后使用索引的查询
SELECT * FROM employees WHERE employee_name = 'John';
在上述例子中,第一个查询使用了UPPER函数对employee_name字段进行转换,这会导致索引无法使用,从而进行全表扫描;而第二个查询直接使用字段进行比较,能够利用employee_name字段上的索引,查询效率更高。
此外,合理使用表连接方式也能提升查询性能。在进行多表连接时,要根据表之间的关系和数据量选择合适的连接类型,如内连接(INNER JOIN)、左外连接(LEFT JOIN)等。同时,尽量将连接条件写在WHERE子句的前面,以减少数据的处理量。
-- 合理的连接条件写法
SELECT e.employee_name, d.department_name
FROM employees e
INNER JOIN departments d
ON e.department_id = d.department_id
WHERE e.salary > 5000;
- 索引优化:索引就像是数据库的 “目录”,能够快速定位到所需数据,大大提高查询速度。创建索引时,要根据业务需求和数据特点选择合适的字段。一般来说,经常用于查询条件、排序或连接的字段适合创建索引。
-- 创建索引
CREATE INDEX idx_employees_salary ON employees(salary);
上述语句在employees表的salary字段上创建了一个索引。但需要注意的是,索引并非越多越好,过多的索引会占用额外的存储空间,并且在数据插入、更新和删除时会增加系统开销,因为数据库需要同时更新索引。因此,要定期评估索引的使用情况,删除那些不再使用或效率低下的索引。
3. 参数调整:Oracle 数据库提供了众多的参数,通过合理调整这些参数,可以优化数据库的性能。其中,系统全局区(SGA)和程序全局区(PGA)的参数设置尤为重要。SGA 是 Oracle 实例分配的共享内存区域,包含数据库高速缓冲区、共享池等;PGA 是每个服务器进程分配的私有内存区域。
可以通过修改init.ora或spfile文件来调整相关参数。例如,增加数据库高速缓冲区的大小,可以提高数据的缓存命中率,减少磁盘 I/O:
ALTER SYSTEM SET db_cache_size = 512M SCOPE = BOTH;
这条语句将db_cache_size参数设置为 512MB,SCOPE = BOTH表示立即生效并且在下次实例启动时仍然有效。
此外,还可以调整共享池的大小,以优化 SQL 语句的解析和执行效率。共享池用于缓存 SQL 语句和数据字典信息,如果共享池过小,可能会导致 SQL 语句频繁解析,降低性能;而共享池过大,则会浪费内存资源。
ALTER SYSTEM SET shared_pool_size = 256M SCOPE = BOTH;
除了 SGA 和 PGA 相关参数,还有许多其他参数也会影响数据库性能,如db_file_multiblock_read_count(控制一次 I/O 操作读取的数据块数量)、optimizer_mode(优化器模式,影响查询执行计划的生成)等,需要根据具体的业务场景和数据库负载进行合理调整。
性能优化是一个综合性的工作,需要从多个方面入手,并且要根据实际的业务需求和数据库运行状况进行持续的监控和调整。通过不断优化 SQL 语句、合理管理索引以及精准调整数据库参数,可以使 Oracle 数据库始终保持高效稳定的运行状态,为企业的业务发展提供坚实的数据支持。
六、学习资源推荐
在学习 Oracle 的道路上,丰富的学习资源就像是得力的助手,能够帮助我们更加高效地掌握知识,少走弯路。以下为大家精心推荐一些优质的学习资源,涵盖书籍、在线课程、论坛等多个方面,满足不同学习习惯和阶段的需求。
(一)书籍推荐
- 《Oracle Database 12c:The Complete Reference》:这本书堪称学习 Oracle 数据库的入门宝典,无论是初涉数据库领域的新手,还是经验丰富的数据库管理员(DBA),都能从中汲取到宝贵的知识。它全面且深入地涵盖了从 Oracle 数据库的基本概念到高级功能的所有内容,详细描述了安装和配置 Oracle 数据库的步骤、管理数据库实例的方法、处理备份与恢复的技巧以及优化性能的策略等多方面的内容。对于初学者而言,它提供了广泛而扎实的知识基础,引导学习者逐步建立起对 Oracle 数据库的认知体系;对于有经验的用户,它则是一个方便实用的参考工具,在遇到技术难题或需要深入了解某个功能时,随时都能从中找到答案。
- 《Oracle PL/SQL Programming》:如果想要深入学习 Oracle 编程,那么这本书绝对是必读书籍。它由美国 Oracle 技术专家 Steven Feuerstein 精心编写,详细介绍了 PL/SQL 编程语言的语法和功能,从基本的变量声明、控制结构,到高级的存储过程、函数、触发器等内容,无一遗漏。书中不仅有丰富的理论知识讲解,还提供了大量的实例和实践技巧,特别强调了代码优化和性能调优,帮助读者编写高效、可维护的 PL/SQL 代码。通过学习这本书,读者不仅能够掌握 PL/SQL 的基础知识,还能学会如何在实际项目中灵活应用这些知识,解决各种复杂的编程问题。
- 《Oracle Performance Survival Guide》:对于那些渴望优化 Oracle 数据库性能的学习者来说,这本书无疑是一本不可多得的佳作。它详细描述了各种性能问题的解决方法,涵盖了从硬件配置到 SQL 优化的各个方面。书中特别注重实践技巧,通过大量的案例分析和解决方案,帮助读者在实际工作中快速识别和解决性能瓶颈,从而提高系统的整体性能和稳定性。无论是数据库新手想要了解性能优化的基本方法,还是经验丰富的 DBA 需要深入研究性能问题的解决方案,这本书都能提供有价值的参考。
(二)在线课程推荐
- Oracle 官方在线课程:Oracle 官方提供了丰富的在线学习资源,这些课程由 Oracle 的专业技术团队精心打造,具有极高的权威性和专业性。课程内容涵盖了 Oracle 数据库的各个方面,从基础的安装配置、SQL 语句编写,到高级的数据库管理、性能优化等,都有详细的讲解和实践指导。通过学习这些课程,学习者能够系统地掌握 Oracle 数据库的知识和技能,并且能够及时了解 Oracle 的最新技术和发展动态。此外,Oracle 官方还提供了在线实验室环境,让学习者可以在实际的数据库环境中进行操作练习,加深对知识的理解和掌握。
- 慕课网 - Oracle 数据库从入门到精通:慕课网的这门课程适合初学者快速入门 Oracle 数据库。课程从 Oracle 的基础概念讲起,逐步深入到 SQL 语句、PL/SQL 编程、数据库管理等核心内容。授课方式生动有趣,通过大量的实际案例和操作演示,帮助学习者轻松理解复杂的知识点。同时,课程还配备了在线编程环境和课后练习题,方便学习者进行实践操作和巩固所学知识,让学习者在实践中逐步提升自己的技能水平。
- 网易云课堂 - Oracle 数据库高级开发与优化实战:这门课程侧重于 Oracle 数据库的高级开发和优化,适合有一定基础的学习者进一步提升自己的技能。课程内容包括复杂的 SQL 优化、存储过程和函数的高级应用、数据库性能调优的实战技巧等。讲师结合自己丰富的项目经验,分享了许多实际项目中遇到的问题和解决方案,让学习者能够深入了解 Oracle 数据库在实际应用中的各种技巧和注意事项,提升解决实际问题的能力。
(三)论坛推荐
- Oracle 官方社区:Oracle 官方社区是全球最大的 Oracle 技术交流平台之一,汇聚了众多 Oracle 技术专家、数据库管理员和开发者。在这个社区中,学习者可以与同行们交流经验、分享技术心得,获取最新的 Oracle 技术资讯和解决方案。社区中设有多个板块,涵盖了 Oracle 数据库的各个方面,无论是遇到技术难题寻求帮助,还是想要了解行业动态和最新技术趋势,都能在这里找到丰富的资源和有价值的信息。
- 墨天轮数据库社区:墨天轮数据库社区是一个专注于数据库技术的交流平台,其中 Oracle 相关的板块非常活跃。在这里,学习者可以找到大量关于 Oracle 数据库的技术文章、实战经验分享、问题解答等内容。社区还定期举办各种技术活动和问答交流,为学习者提供了与其他数据库爱好者互动学习的机会,帮助学习者拓宽技术视野,提升技术水平。
七、总结与展望
学习 Oracle 数据库是一段充满挑战与收获的旅程。从初窥门径时搭建环境的摸索,到深入掌握 SQL 语句和 PL/SQL 编程,再到学会数据库管理与优化的技巧,每一步都凝聚着努力与探索。在这个过程中,我们了解到 Oracle 强大的功能和广泛的应用领域,它不仅是企业级数据管理的重要工具,更是培养逻辑思维和数据处理能力的绝佳平台。
然而,学习 Oracle 并非一蹴而就,需要持续不断的努力和实践。在实际项目中应用所学知识,是巩固和深化理解的关键。可能会遇到各种复杂的问题,比如高并发场景下的性能优化、数据一致性的维护等,但这些挑战也正是成长的机遇。通过解决实际问题,能够更加深入地理解 Oracle 的工作原理,提升自己的技术水平。
同时,数据库技术在不断发展,Oracle 也在持续更新迭代,新的特性和功能不断涌现。因此,保持学习的热情和好奇心至关重要。关注行业动态,学习最新的技术知识,将有助于我们紧跟时代步伐,更好地适应未来的工作需求。
希望大家在学习 Oracle 的道路上持之以恒,不断探索,将所学知识灵活运用到实际项目中,收获满满的成就感。也期待大家能在数据库领域中发现更多的精彩,为自己的职业发展打下坚实的基础 。如果你在学习过程中有任何疑问或心得,欢迎在评论区留言交流,让我们一起共同进步!


















 2849
2849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











