




目录
一、Python 递归:以简驭繁的编程艺术
在 Python 的编程世界里,递归就像是一把神奇的钥匙,能够打开许多复杂问题的大门。递归的核心思想简洁而深邃:一个函数在执行过程中调用自身。这听起来似乎有点 “套娃”,但正是这种独特的机制,赋予了递归强大的问题解决能力。
递归的应用场景极为广泛。在数学领域,计算阶乘是递归的经典用例。比如,计算 5 的阶乘,我们知道 5! = 5×4×3×2×1 ,使用递归函数来实现这个计算过程,代码可以简洁地写成:
def factorial(n):
if n == 0 or n == 1:
return 1
else:
return n * factorial(n - 1)
print(factorial(5)) # 输出120在这个函数中,当 n 为 0 或 1 时,我们直接返回 1,这是递归的终止条件;否则,就通过 n 乘以 n - 1 的阶乘来逐步计算,每一次递归调用都在缩小问题的规模,直至达到终止条件。
在数据结构遍历中,递归也大显身手。例如遍历目录下的所有文件和子目录。假设我们有一个目录,里面包含多个文件和子目录,子目录中又可能有更多的文件和子目录。使用递归,我们可以轻松地实现深度优先搜索:
import os
def traverse_directory(path):
for entry in os.scandir(path):
if entry.is_file():
print(f"文件: {entry.path}")
elif entry.is_dir():
print(f"目录: {entry.path}")
traverse_directory(entry.path)
traverse_directory('.')在这段代码中,traverse_directory函数接收一个路径参数,对于传入路径下的每一个条目,如果是文件就直接打印文件路径;如果是目录,就打印目录路径并递归调用traverse_directory函数来遍历这个子目录,如此层层深入,直到遍历完所有的文件和子目录。
递归在算法设计中也扮演着重要角色,像分治算法就常常借助递归的力量。以快速排序算法为例,其基本思想是通过选择一个基准元素,将数组分为两部分,小于基准的元素放在左边,大于基准的元素放在右边,然后递归地对左右两部分进行排序,最终得到一个有序的数组。虽然递归在很多场景下表现出色,但它也并非完美无缺。由于递归调用会在栈中保存大量的函数调用信息,当递归深度过深时,容易导致栈溢出错误。因此,在使用递归时,需要谨慎考虑问题的规模和递归的深度 ,必要时可以采用迭代等其他方式来替代递归,以提高程序的效率和稳定性。
二、递归的基本概念与工作原理
2.1 递归的定义与关键要素
递归函数,简单来说,就是在函数内部调用自身的函数。它就像是一个不断自我复制的程序片段,每次调用都会产生一个新的 “副本” 来处理问题的一部分。但递归函数并非可以无限制地自我调用下去,它必须包含两个关键要素:基准情况(Base Case)和递归情况(Recursive Case)。
基准情况是递归的终止条件,当满足这个条件时,递归就会停止,函数不再调用自身,而是直接返回一个确定的结果。比如在前面提到的阶乘函数中,n == 0 or n == 1就是基准情况,当n为 0 或 1 时,直接返回 1,不再进行递归调用。如果没有基准情况,递归函数就会陷入无限循环,导致程序崩溃。
递归情况则是函数调用自身来解决问题的核心部分。在递归情况中,函数会将问题分解为规模更小的子问题,通过递归调用自身来逐步解决这些子问题,最终将所有子问题的结果组合起来得到原问题的答案。例如,在计算n的阶乘时,n * factorial(n - 1)就是递归情况,它将计算n的阶乘问题转化为计算n - 1的阶乘问题,通过不断递归调用factorial函数,逐步缩小问题规模,直到达到基准情况。
2.2 递归的执行过程剖析
为了深入理解递归函数的执行过程,我们需要了解调用堆栈(Call Stack)的概念。调用堆栈是一种后进先出(LIFO,Last In First Out)的数据结构,它用于存储函数调用的相关信息,包括函数的参数、局部变量以及返回地址等。
当一个函数被调用时,系统会在调用堆栈上创建一个新的栈帧(Stack Frame),用于保存该函数的执行上下文。然后,将控制权转移到被调用函数的代码处开始执行。如果被调用函数在执行过程中又调用了其他函数,同样会在调用堆栈上创建新的栈帧,并将控制权转移到新的函数。
在递归函数中,每次递归调用都会在调用堆栈上创建一个新的栈帧,这些栈帧层层叠加,就像一个不断堆积的 “栈塔”。当递归达到基准情况时,函数开始返回。每次返回时,系统会从调用堆栈的栈顶弹出当前函数的栈帧,恢复上一个函数的执行上下文,并将控制权返回给上一个函数。如此反复,直到所有的递归调用都返回,调用堆栈恢复为空。
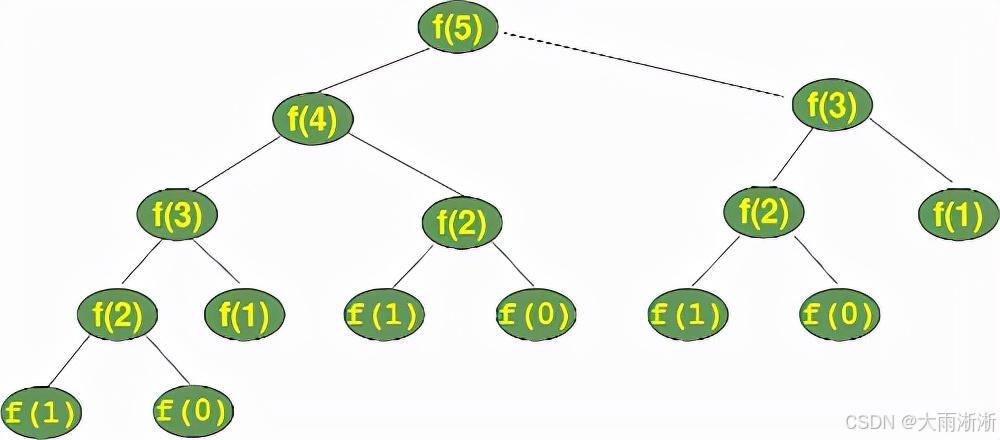
以计算 5 的阶乘为例,factorial(5)的执行过程如下:
-
调用factorial(5),系统在调用堆栈上创建第一个栈帧,保存n = 5等信息。
-
由于n != 0且n != 1,进入递归情况,调用factorial(4),创建第二个栈帧,保存n = 4等信息。
-
同理,依次调用factorial(3)、factorial(2)、factorial(1),分别创建第三、四、五个栈帧。
-
当调用factorial(1)时,满足基准情况n == 1,返回 1,此时第五个栈帧弹出。
-
factorial(2)接收到factorial(1)返回的 1,计算2 * 1,返回 2,第四个栈帧弹出。
-
依此类推,factorial(3)返回3 * 2 = 6,factorial(4)返回4 * 6 = 24,factorial(5)返回5 * 24 = 120,调用堆栈上的栈帧依次弹出,最终得到 5 的阶乘结果 120。
通过调用堆栈的机制,我们可以清晰地看到递归函数在执行过程中的层层调用和返回过程,理解递归如何将一个复杂问题逐步分解并解决。
三、递归的经典应用场景
2.3 数学计算领域
递归在数学计算领域有着诸多经典的应用,其中阶乘和斐波那契数列是最为人熟知的例子。
阶乘是一个正整数与所有小于它的正整数的乘积,0 的阶乘定义为 1。在 Python 中,使用递归计算阶乘的代码如下:
def factorial(n):
if n == 0 or n == 1:
return 1
else:
return n * factorial(n - 1)在这个函数中,if n == 0 or n == 1是基准情况,当满足这个条件时,递归停止,返回 1。else分支则是递归情况,通过n * factorial(n - 1)不断调用自身,将计算n的阶乘问题转化为计算n - 1的阶乘问题,逐步缩小问题规模,直到达到基准情况。
斐波那契数列同样是递归的经典应用。该数列从第 3 项开始,每一项都等于前两项之和,其前几项为:0、1、1、2、3、5、8、13、21、34、…… 用数学公式表示为:
\(F(n) = \begin{cases} 0 & \text{if } n = 0 \\ 1 & \text{if } n = 1 \\ F(n-1) + F(n-2) & \text{if } n > 1 \end{cases}\)
使用 Python 递归实现计算斐波那契数列第n项的代码如下:
def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)在这个实现中,if n == 0和elif n == 1是基准情况,分别返回 0 和 1。else分支是递归情况,通过fibonacci(n - 1) + fibonacci(n - 2)递归计算前两项的和,从而得到第n项的值。不过需要注意的是,这种递归实现虽然简洁直观,但由于存在大量的重复计算,时间复杂度为指数级\(O(2^n)\) ,当n较大时,计算效率会非常低。
2.4 数据结构遍历
在数据结构遍历中,递归也发挥着重要作用,尤其是在处理树、图等复杂数据结构时。以二叉树的遍历为例,二叉树是一种每个节点最多有两个子节点的树形结构,常见的遍历方式有前序遍历、中序遍历和后序遍历,递归可以很自然地实现这些遍历方式。
前序遍历是先访问根节点,然后递归地前序遍历左子树,最后递归地前序遍历右子树。Python 代码实现如下:
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def preorder_traversal(root):
if root:
print(root.value, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











