




| 什么是梯度消失? 神经元的权重w和偏置b是和激活函数的梯度成正比的,激活函数导数越大,则w,b调整越快,如果激活函数梯度很小,在反向传播时,多个小于0的导数相乘,随着神经网络层数的加深,梯度方向传播到浅层网络时,基本无法引起全职的波动,也就是没有将loss的信息传递到浅层网络,这样网络就无法训练学习了。这就是所谓的梯度消失。 以sigmoid激活函数为例: sigmoid(x)=1/1+e^−x 该函数可以将实数压缩到开区间(0,1),其导数为: σ′(x)=e^−x/(1+e^−x)^2=σ(x)/(1−σ(x)) 函数图像如下: 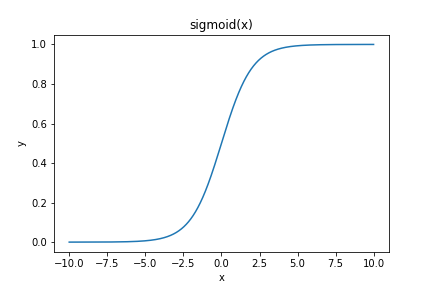 数两侧十分平滑,两端无限接近0和1,只有中间一段导数较大。当x=0时,其导数取最大值0.25。选择sigmoid函数作为激活函数的优势:1)可以引入非线性;2)容易求导;3)可以将实数压缩至(0,1)
神经网络主要的训练方法是BP算法,BP算法的基础是导数的链式法则,也就是多个导数的乘积。而sigmoid的导数最大为0.25,且大部分数值都被推向两侧饱和区域,这就导致大部分数值经过sigmoid激活函数之后,其导数都非常小,多个小于等于0.25的数值相乘,其运算结果很小。
|
神经网络中的梯度消失
最新推荐文章于 2024-12-21 00:00:00 发布
 本文深入探讨了神经网络中常见的梯度消失现象,解释了其原因并提出了一些解决方案,包括使用激活函数和归一化技术等。通过对反向传播过程的理解,读者将更好地掌握如何避免训练深层模型时遇到的梯度消失问题。
本文深入探讨了神经网络中常见的梯度消失现象,解释了其原因并提出了一些解决方案,包括使用激活函数和归一化技术等。通过对反向传播过程的理解,读者将更好地掌握如何避免训练深层模型时遇到的梯度消失问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









