




 Spark 1.6.0 引入了统一内存管理,突破了之前shuffle和storage内存的静态分配限制。在非统一管理中,通过spark.shuffle.memoryFraction和spark.storage.memoryFraction设置内存大小。而在统一管理中,如果一方内存不足,可借用另一方的剩余内存,实现了更加灵活的资源调配。这一变化提高了内存利用率,确保了在不同需求之间的平衡。
Spark 1.6.0 引入了统一内存管理,突破了之前shuffle和storage内存的静态分配限制。在非统一管理中,通过spark.shuffle.memoryFraction和spark.storage.memoryFraction设置内存大小。而在统一管理中,如果一方内存不足,可借用另一方的剩余内存,实现了更加灵活的资源调配。这一变化提高了内存利用率,确保了在不同需求之间的平衡。
spark统一内存管理是spark1.6.0的新特性,是对shuffle memory 和 storage memory 进行统一的管理,打破了以往的参数限制。
非统一内存管理
spark在1.6 之前都是非统一内存管理,通过设置spark.shuffle.memoryFraction 和 spark.storage.memoryFraction来设置shuffle 和storage的memory 大小。看下StaticMemoryManager的获得最大shuffle和storage memory的函数。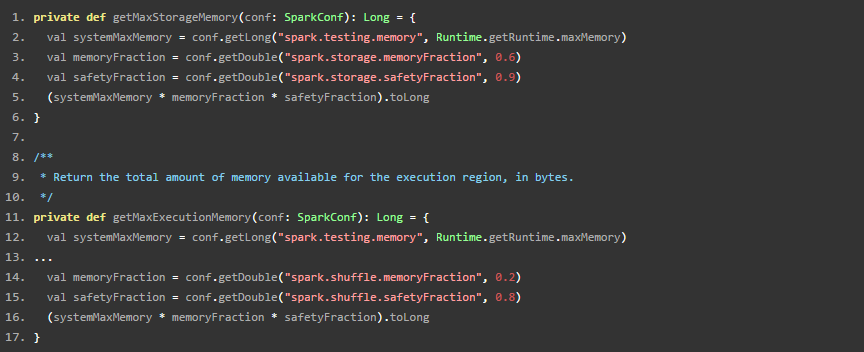
可以看出,systemMaxMemory是通过参数spark.testing.memory来获得,如果这个参数没有设置,就取虚拟机内存,然后shuffle 和 storage都有安全系数,最后可用的最大内存都是:系统最大内存*比例系数*安全系数。
统一内存管理
spark 1.6.0 出现了统一内存管理,是打破了shuffle 内存和storage内存的静态限制。通俗的描述,就是如果storage内存不够,而shuffle内存剩余就能借内存,如果shuffle内存不足,此时如果storage已经超出了storageRegionSize,那么就驱逐当前使用storage内存-storageRegionSize,如果storage 使用没有超过storageRegionSize,那么则把它剩余的都可以借给shuffle使用。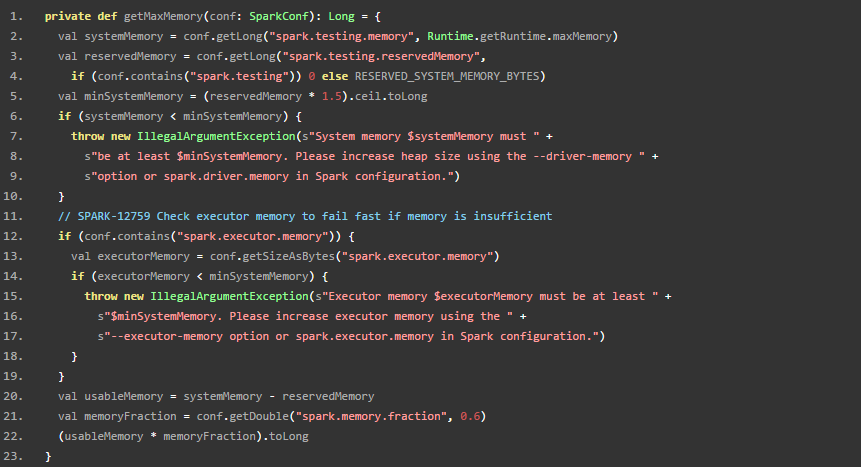
这个是统一内存管理的获得最大内存的函数,因为shuffle和storage是统一管理的,所以只有一个获得统一最大内存的函数。usableMemory = systemMemory - reservedMemory.
最大内存=usableMemory * memoryFraction.
统一内存管理的使用##
UnifiedMemoryManager是在一个静态类里面的apply方法调用的。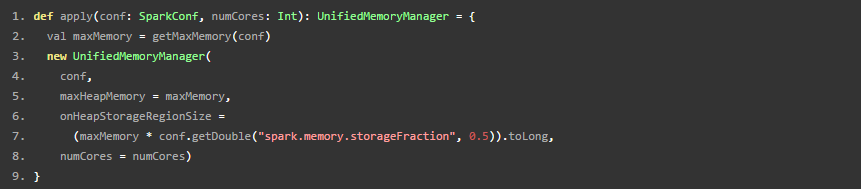
然后通过 find Uages 找到是在 sparkEnv里面调用。
是通过判断参数,判断是使用统一内存管理还是非内存管理。
然后通过查看usages 发现是在 CoarseGrainedExecutorBackEnd 和 MesosExecutorBackEnd里面调用的,所以是每个executor都有一个统一内存管理的实例(…很显然,逻辑也是这样)。

















 2149
2149




 到【灌水乐园】发言
到【灌水乐园】发言







