






上次成功的通过Flume收集到了阿里云日志服务的日志,今天就把从Flume从阿里云日志服务采集过来的日志sink到Kafka
启动Kafka
[hadoop@hadoop004 kafka_2.11-0.10.0.0]$ nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &
[1] 25052
Kafka创建topic
[hadoop@hadoop004 kafka_2.11-0.10.0.0]$ bin/kafka-topics.sh \
> --create \
> --zookeeper hadoop004:2181/kafka \
> --replication-factor 1 \
> --partitions 3 \
> --topic sls
Created topic "sls".
[hadoop@hadoop004 kafka_2.11-0.10.0.0]$ bin/kafka-topics.sh \
> --list \
> --zookeeper hadoop004:2181/kafka
sls
启动Kafka的consumer
[hadoop@hadoop004 kafka_2.11-0.10.0.0]$ bin/kafka-console-consumer.sh \
> --zookeeper hadoop004:2181/kafka \
> --topic sls \
> -from-beginning
配置agent文件
sls-flume-kafka.sources = sls-source
sls-flume-kafka.channels = sls-memory-channel
sls-flume-kafka.sinks = kafka-sink
sls-flume-kafka.sources.sls-source.type = com.aliyun.loghub.flume.source.LoghubSource
sls-flume-kafka.sources.sls-source.endpoint = cn-shenzhen.log.aliyuncs.com
sls-flume-kafka.sources.sls-source.project = <Your Loghub project>
sls-flume-kafka.sources.sls-source.logstore = <Your Loghub logstore>
sls-flume-kafka.sources.sls-source.accessKeyId = <Your Accesss Key Id>
sls-flume-kafka.sources.sls-source.accessKey = <Your Access Key>
sls-flume-kafka.sources.sls-source.deserializer = JSON
sls-flume-kafka.sources.sls-source.sourceAsField = true
sls-flume-kafka.sources.sls-source.timeAsField = true
sls-flume-kafka.sources.sls-source.topicAsField = true
sls-flume-kafka.sources.sls-source.fetchInOrder = true
sls-flume-kafka.sources.sls-source.initialPosition = timestamp
sls-flume-kafka.sources.sls-source.timestamp = 1562299808
sls-flume-kafka.channels.sls-memory-channel.type = memory
sls-flume-kafka.channels.sls-memory-channel.capacity = 20000
sls-flume-kafka.channels.sls-memory-channel.transactionCapacity = 100
#sls-flume-kafka.sinks.kafka-sink.type = logger
sls-flume-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
sls-flume-kafka.sinks.kafka-sink.topic = sls
sls-flume-kafka.sinks.kafka-sink.brokerList = hadoop004:9092
sls-flume-kafka.sinks.kafka-sink.requiredAcks = 1
sls-flume-kafka.sinks.kafka-sink.batchSize = 20
sls-flume-kafka.sources.sls-source.channels = sls-memory-channel
sls-flume-kafka.sinks.kafka-sink.channel = sls-memory-channel启动Flume
[hadoop@hadoop004 bin]$ ./flume-ng agent --name sls-flume-kafka --conf /data/aaron/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/conffile --conf-file /data/aaron/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/conffile/sls-flume.conf -Dflume.root.logger=INFO,console
稍等片刻。。。
成功了,Kafka的消费端接收到阿里云日志服务的日志了
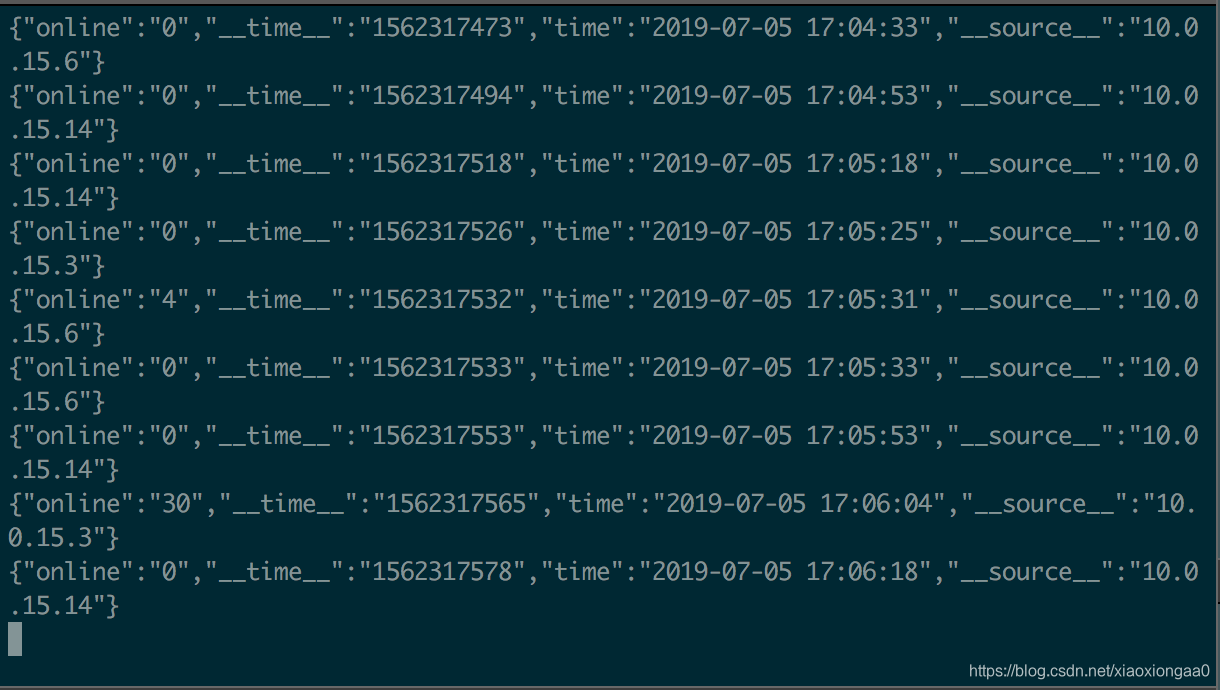
下一步是使用Spark Streaming来消费,敬请期待!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









