






 本文深入解析了Flink 1.7版本的分布式执行机制,涵盖任务和算子链的优化、TaskManager与JobManager的角色、任务槽及资源管理策略、状态后端实现以及SavePoint功能,旨在帮助读者理解Flink高效执行原理。
本文深入解析了Flink 1.7版本的分布式执行机制,涵盖任务和算子链的优化、TaskManager与JobManager的角色、任务槽及资源管理策略、状态后端实现以及SavePoint功能,旨在帮助读者理解Flink高效执行原理。
Flink1.7官网文档翻译 -原创-flink.sojb.cn
目录
任务和算子链
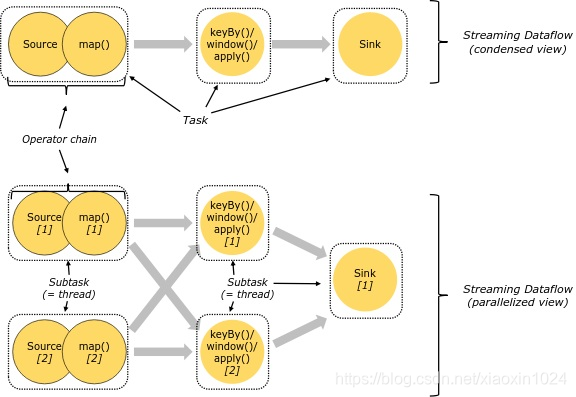
对于分布式执行,Flink链算子任务一起放入任务。每个任务由一个线程执行。将算子链接到任务中是一项有用的优化:它可以Reduce线程到线程切换和缓冲多的开销,并在降低延迟的同时提高整体吞吐量。可以配置链接行为;请参阅链接文档。
下图中的实例数据流由五个字任务执行,因此具有五个并行线程。
TaskManager,JobManager,客户端
Flink运行时包括两种类型的进程:
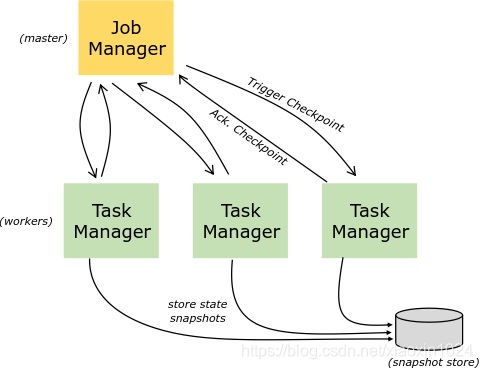
该JobManager(也称Masters)协调分布式执行。他们安排任务,协调检查点,协调故障恢复等。
总是至少有一个JobManager。高可用性设置将具有多个JobManager,其中一个始终是Leader,其它人处于待机状态。
该TaskManager(也叫工人)执行任务(或者更具体地说,子任务)的数据流,以及缓冲器和交换数据流。
必须始终至少有一个TaskManager。
JobManager和TaskManager可以通过多种方式启动:作为独立集群直接在计算机上,在容器中,或由YARN或Mesos等资源框架管理。TaskManager连接到JobManagers,宣布自己可用,并被分配工作。
-客户端不是运行时和程序执行的一部分,而是被用来准备和发送数据流的JobManager。之后,客户端可以断开连接或保持连接以接收进度报告。客户端既可以触发执行的Java/Scala程序的一部分运行们也可以在命令行中运行
./bin/flink run ...
任务槽和资源
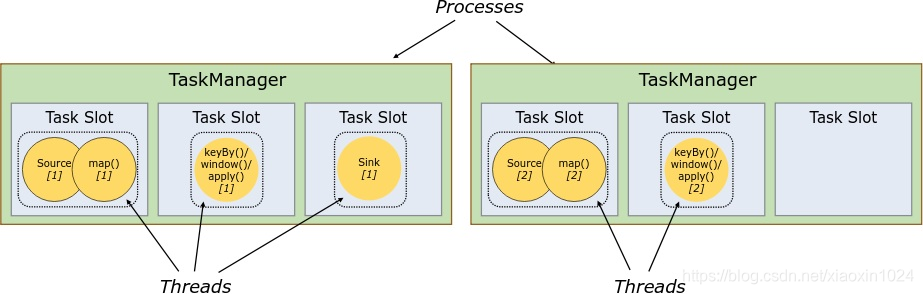
每个worker(TaskManager)都是一个JVM进程,可以在不同的线程中执行一个或多个子任务。为了控制worker接收的任务数量,worker有所谓的任务槽(至少一个)。
每个任务槽代表TaskManager的固定资源子集。例如,具有三个插槽的TaskManager将其1/3的托管内存专用于每个插槽。切换资源意味着子任务不会与来自其它作业的子任务竞争托管内存,而是具有一定数据量的保存托管内存。注意的是,这里不会发生CPU隔离;当前插槽指缝里任务的托管内存。
通过调整任务槽的数量,用户可以定义子任务如何相互隔离。每个TaskManager有一个插槽意味着每个任务组在一个单独的JVM中运行(例如,可以在以在单独的容器中启动)。拥有多个插槽意味着更多的子任务共享同一个JVM。同一个JVM中的任务共享TCP连接(通过多路复用)和心跳消息。他们还可以共享数据集和数据结构,从而减少每个任务的开销。
默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。允许此插槽共享有两个主要好处:
Flink集群需要使用与作业中最高并行度一样多的任务槽。无需计算程序总共包含多少任务(具有不同的并行性)
更容易获得更好的资源利用率。如果没有插槽共享,非密集Source/map() 子任务将阻止与资源密集型窗口子任务一样多的资源。通过插槽共享,将示例中的基本并行性从2增加到6可以充分利用时隙资源,同时确保繁重的子任务在TaskManager之间公平分配。
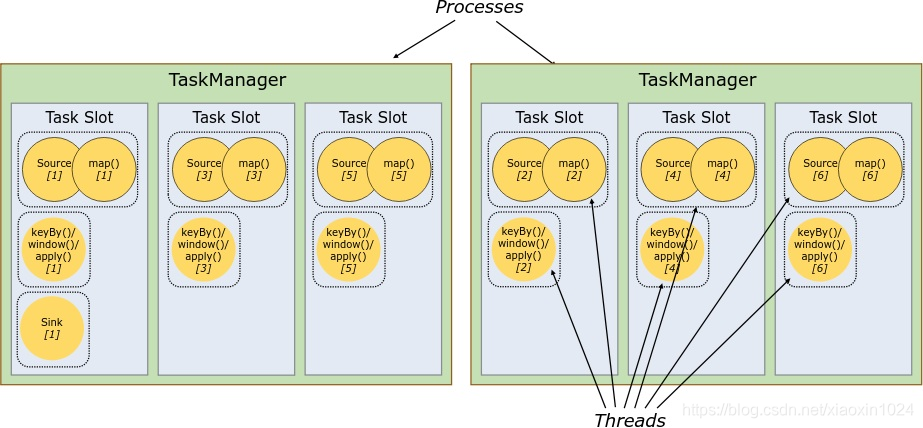
API还包括用于防止不期望的时隙共享的资源组机制。
根据经验,一个很好的默认任务槽数就是CPU核心数。使用超线程,每个插槽然后需要两个或者更多的硬件线程上下文。
状态后台
存储key/value索引的确切数据结构取决于所选的状态后台。一个状态后台将数据存储在内存中的哈希映射中,另一个状态后台还使用RocksDB作为key/value存储。除了定义保存状态多的数据结构之外,状态后台还实现了以获取key/value状态的时间点Snapshot的逻辑,并将该Snapshot存储为检查点的一部分。
SavePoint
用DtaStream API编写的程序可以从保存点恢复执行。保存点允许更新程序和Flink集群,而不是丢失数据。话说这是Flink的一个亮点功能(升级--什么的)。
savepoint是手动触发的检查点,他会获取程序的Snapshot并将其写入状态后台。它们依靠常规的检查点机制。在执行期间,程序会定期的在工作节点上创建Snapshot并生成检查点。对于恢复,仅需要最后完成的检查点,并且一旦新的检查点完成,就可以安全地丢弃旧的检查点。
savepoint这些与定期检查点类似,不同指出在于它们由用户触发,并且在较新地检查点完成时不会自动过期。可以从命令行或者REST API取消作业时创建的保存点。

















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









