




 本文介绍了如何使用描述性统计学在金融反欺诈中发现数据异常、离群值和标签占比问题。重点讲解了numpy、SciPy和pandas库在计算均值、中位数、标准差等统计量中的应用,并通过可视化工具matplotlib和seaborn进行数据分布的直观展示,以帮助识别潜在的欺诈行为。
本文介绍了如何使用描述性统计学在金融反欺诈中发现数据异常、离群值和标签占比问题。重点讲解了numpy、SciPy和pandas库在计算均值、中位数、标准差等统计量中的应用,并通过可视化工具matplotlib和seaborn进行数据分布的直观展示,以帮助识别潜在的欺诈行为。
统计学分为两大部分,描述性统计学和推断性统计学。而描述性统计学在建模的时候往往是很重要而又容易被人忽略的一步, 而它的作用往往如下:
1.发现数据中的异常
2.通过分布图发现离群值点
3.检查数据缺失情况
4.检查标签占比情况,如坏样本太少的话,需要抽样调整好坏样本比例
所需模块python模块
matplotlib
pandas
seaborn
numpy
SciPy
例子
首先用numpy来创造一组随机数,我这边创造一组正态分布的随机数,总共50个用于实验。
from numpy.random import normal, randint
datatest= normal(0, 50, size=50)
一般描述性统计的统计量有均值,众数,中位数,极差,标准差,方差
这三种重要的统计量,可以分别用numpy包,SciPy包,pandas包计算
Numpy包计算方法
from numpy import mean, median
import numpy as np
np.mean(datatest)---计算均值
np.median(datatest)—计算中位数
np.std(datatest)—计算标准差
np.var(datatest)—计算方差
scipy包计算方法
from scipy.stats import mode
mode(datatest)
pandas包计算方法
用pandas计算统计量,需要先把数据转换重pandas的数据框格式
先加列名’number’,转为字典
datatestn={'number':datatest}
再转为dataframe格式
datatestn =pd.DataFrame(datatestn)
就可以直接用
datatestn.mean()
datatestn.median()
datatestn.mode()
或者一步到位
datatestn.describe()
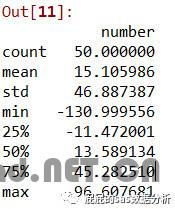
如上,产出数量,均值,标准差,最大最小值,以及各分位点。
datatestn.skew()
datatestn.kurt()
针对我们自己要分析的数据,可以在sas上面处理完,用python读取,例如:
datatestnnn=pd.read_sas(‘D:\dataplay.sas7bdat’)
datatestnnn['salary'].shape—取收入变量,再看行数和列数
然后用刚才提到的一系列方法分析,当用datatestnnn.skew()计算出来的偏度越大且为正数,说明数据的分布重尾在右边,右边的极端值较多,可能有较多的异常值。
可视化
可视化可以用matplotlib包和seaborn包,就可以从图片观察数据的分布,有直观的感觉。
import matplotlib.pyplot as plt
plt.hist(datatest,bins=50,color='b')
plt.xlabel('number')
plt.ylabel(Frequency’)
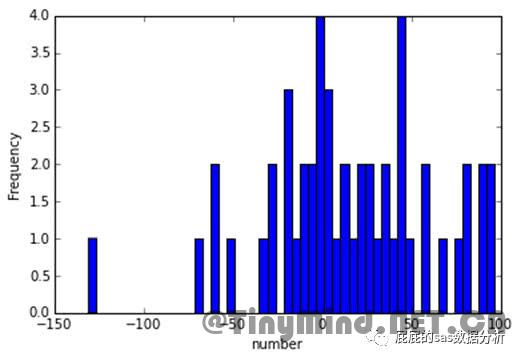
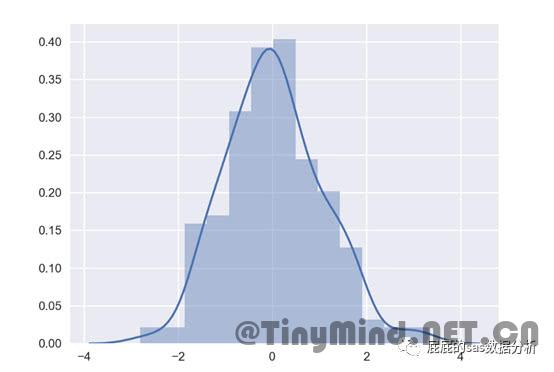
import seaborn as sns
sns.distplot(datatest)
要做箱线图的话可以执行以下代码
from pylab import *


















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









