




 本文深入浅出地介绍了机器学习中的关键概念和技术,包括自动编码器、生成对抗网络(GAN)、迁移学习、模型可解释性、模型压缩、终身学习、进化算法、贝叶斯网络、粒子滤波、高斯定理及深度强化学习等。并通过实例帮助读者理解这些概念的实际应用。
本文深入浅出地介绍了机器学习中的关键概念和技术,包括自动编码器、生成对抗网络(GAN)、迁移学习、模型可解释性、模型压缩、终身学习、进化算法、贝叶斯网络、粒子滤波、高斯定理及深度强化学习等。并通过实例帮助读者理解这些概念的实际应用。
下面的都特别好理解,理解了思想很重要,代码很简单。
机器学习强化
1 自动编码器
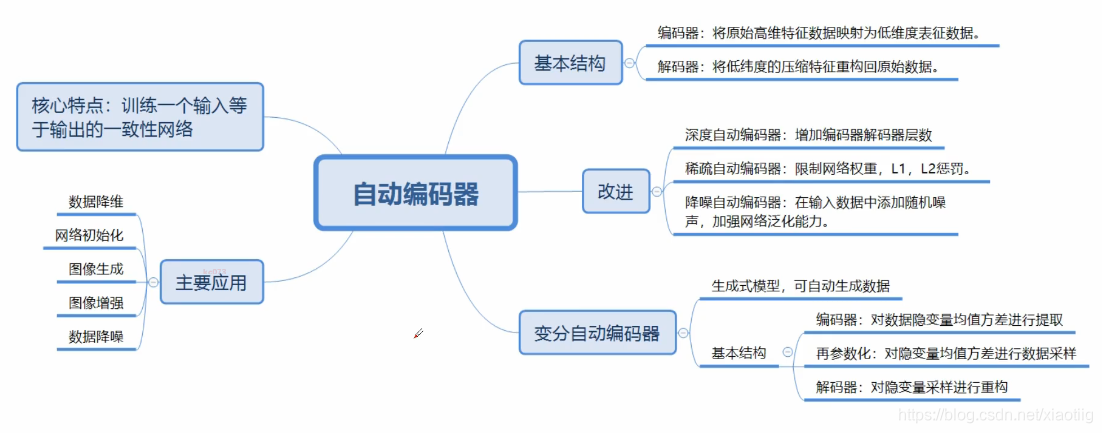
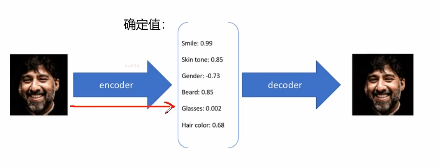
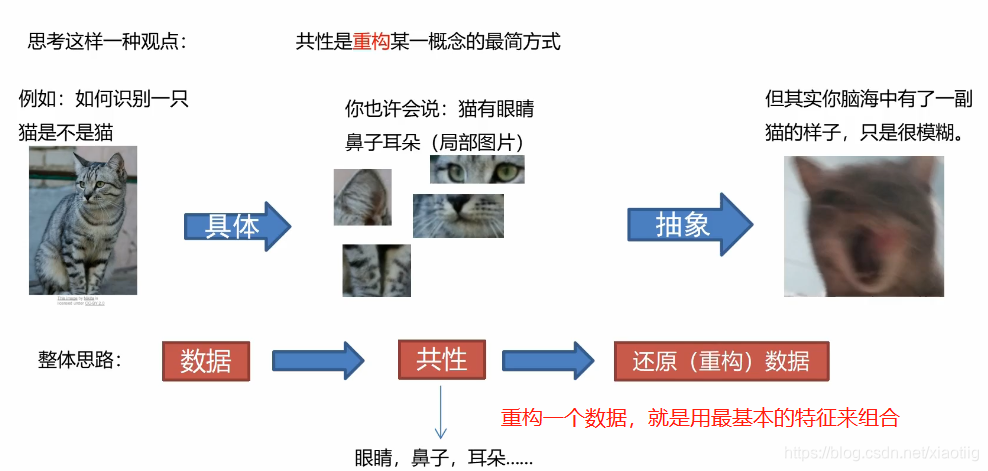
1.1 原理
自动编码器就是编码和解码两个过程,一点也不神秘!!!
编码就是抽象特征,解码就是再复原等
比如Unet就是一个自动编码器
卷积神经网络就是加强版的自动编码器,只不过它更强调结果,而不是中间的特征
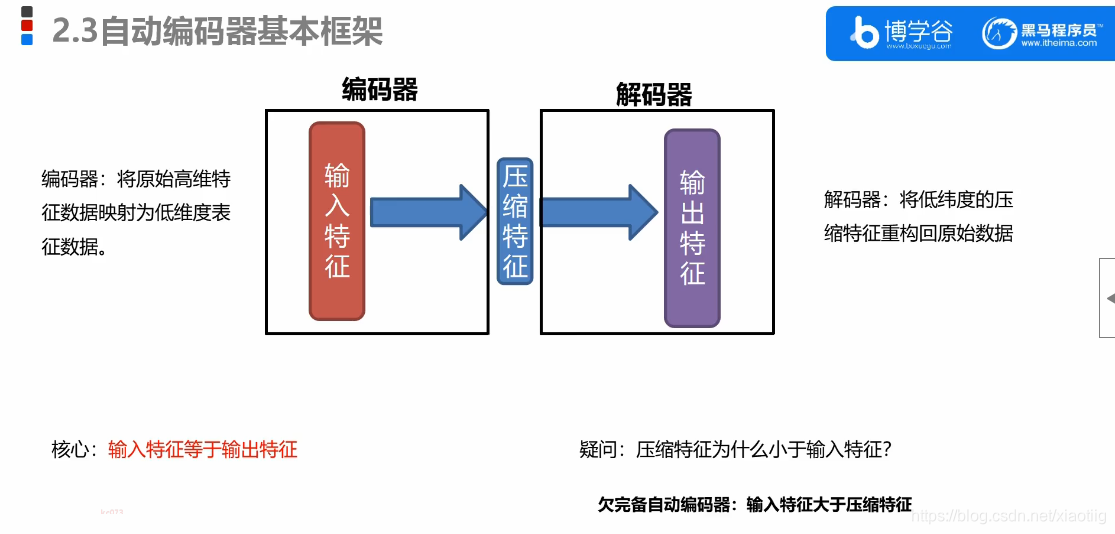
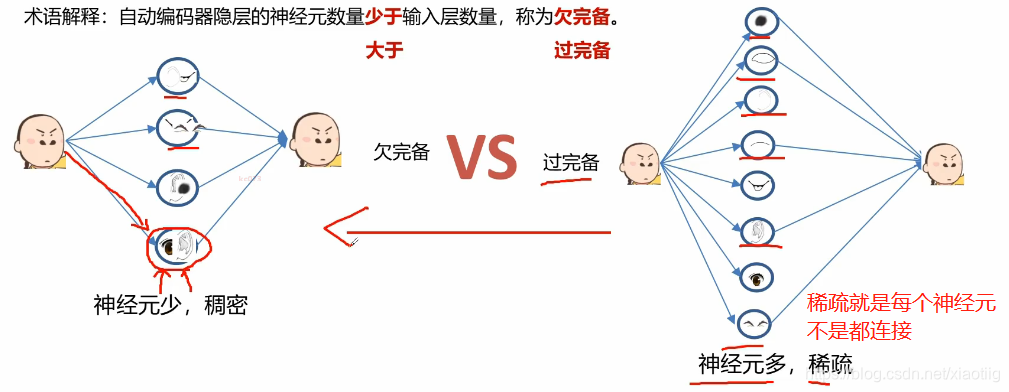
欠完备:特征变少,降维
过完备:特征变多,升维


1.2 稀疏自动编码器
本来应该是这幅图,一堆连接
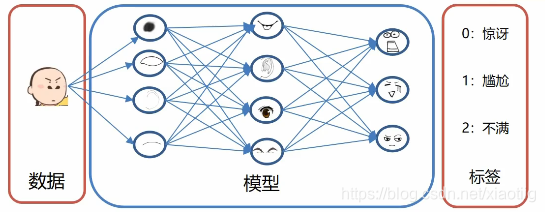
这样连接的网络就变少了

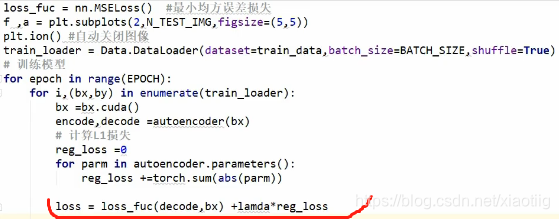
损失少和权重少两者不可兼得,所以要加入一个惩罚因子,给这两项赋予一个权重,看你的取舍。
下面把两者都放到损失中去
1.3 去噪自动编码器
主动将噪声加入到训练数据中,提升模型的鲁棒性
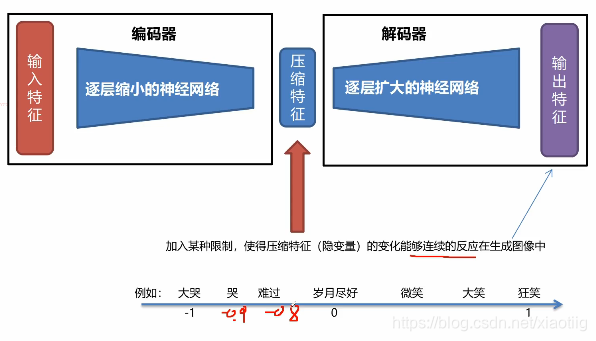
1.4 变分自动编码器
从无到有生成一些数据
为每个隐藏特征生成一个概率分布。
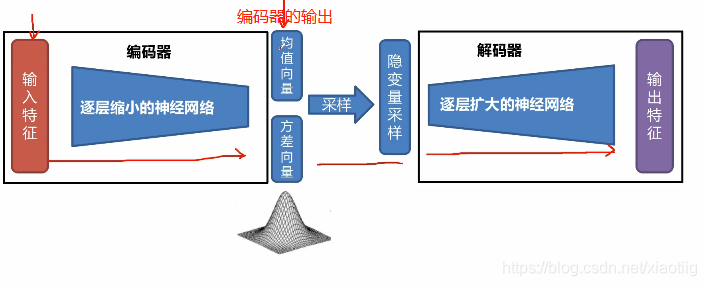
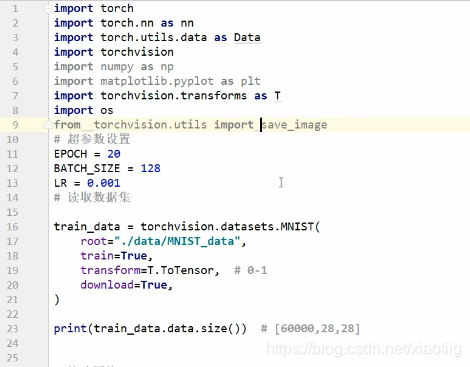
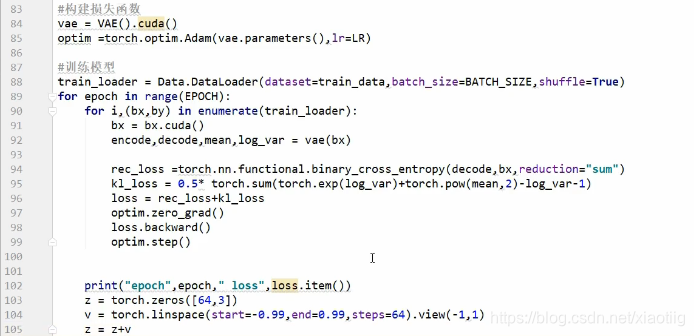
1.4.1 变分自动编码器代码
代码来自黑马课程




1.5 受限玻尔兹曼机

2 生成对抗网络GAN
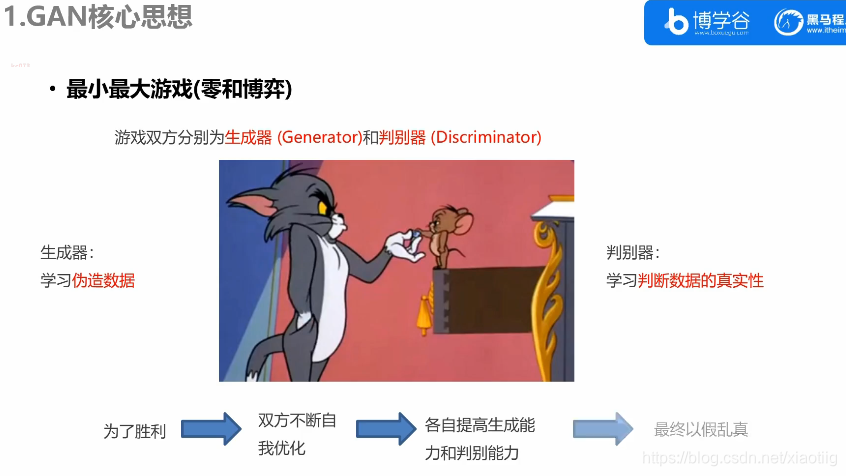
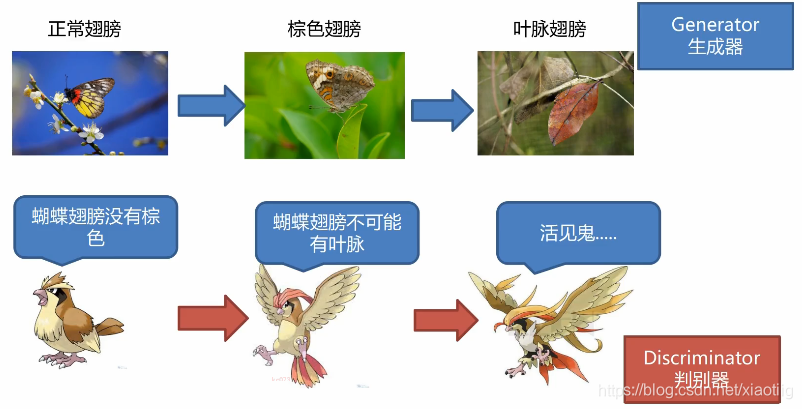
注意有两个网络,那么也就有两个输入输出:
生成器的输入是一组向量,输出是生成的数据
判别器的输入是生成器生成的数据和真实数据,输出是二分类结果。
2.1生成器
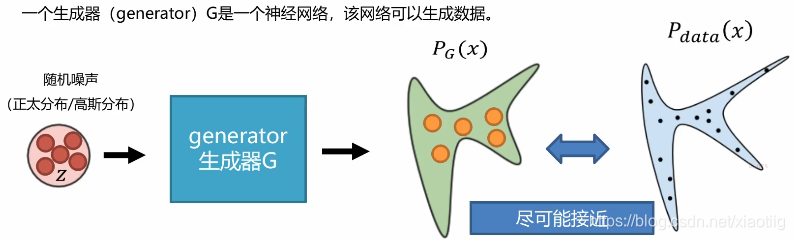
上面的随机噪声是一组组向量,看下图

2.2 判别器
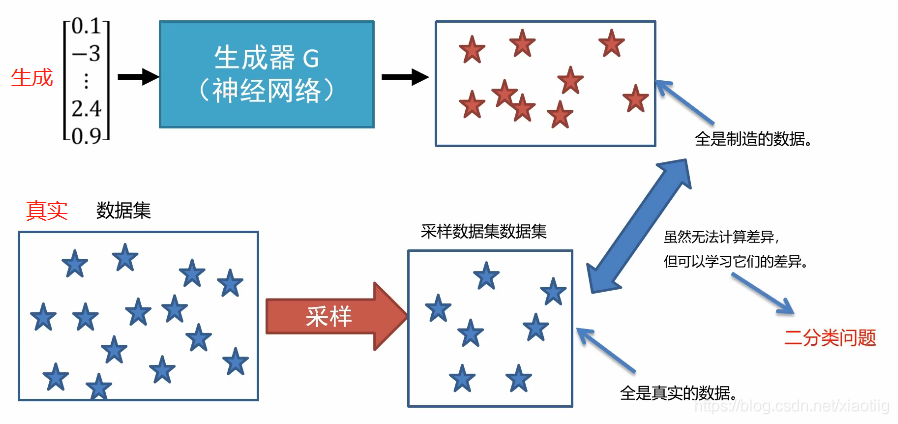
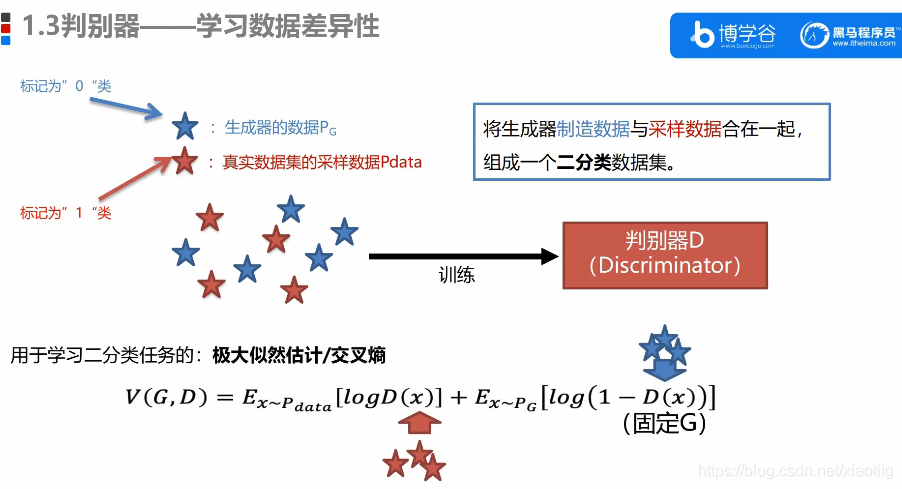
2.3 优化学习过程
就是周而复始的重复下面两个步骤:

2.4 存在问题

最大的困难就是很不稳定,很难让生成器和判别器均衡,无法让二者相互正好制衡,势均力敌。
2.5 代码
很简单
主要就是构建一个网络
前半部分就是一个生成器,后半部分就是判别器
训练的时候直接全训练,但是用分为两部分,先训练前半部分网络就是前半部分设置梯度,后半部分不设置梯度)再训练后半部分网络(就是前半部分不设置梯度,后半部分设置梯度)。
2.6 进一步理解
很简单
(1)比如坏蛋造假钞,和银行造验钞机,来回博弈
(2)比如unet从图像生成最后的结果,反过来生成器就是用最后的分布的数据点生成原始图像。 正好和语义分割相反
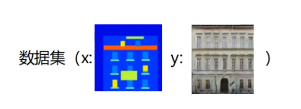
3 迁移学习
最重要作用的就是能加快训练速度

数据差不多叫域相似
分类任务相同叫任务相同
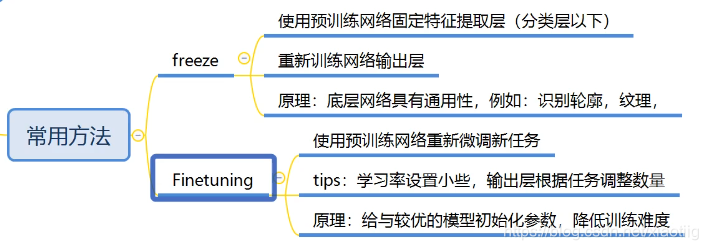
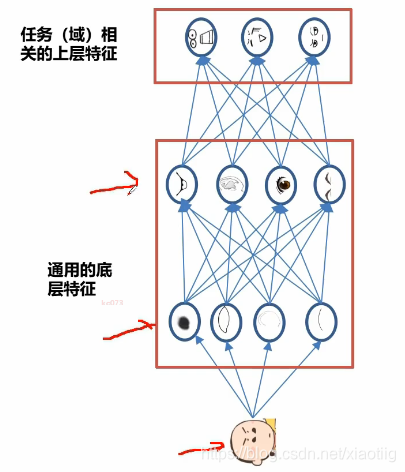
下面进行迁徙学习,就是微调其中的一部分,它的原理就是深度学习的浅层网络已经提取好了通用的底层特征,深层网络就是对特征进行组合。
我们相似的任务,它们的底层特征几乎一样,就不用再训练了。

4 模型可解释
给出理由是商业,法律和社会的要求。
要让模型可解释:
(1)侠义可解释:为什么这张图片是猫
(2)广义可解释:你认为猫是什么样子
原理:
通过反向传播,得到特征的热力图
比如你解释网络怎么判断是刷牙呢,你通过反向传递得到中间某层的热力图,发现模型在牙刷部分会高亮显示,相对而言做出了一些解释,而不是真的能完全解释。

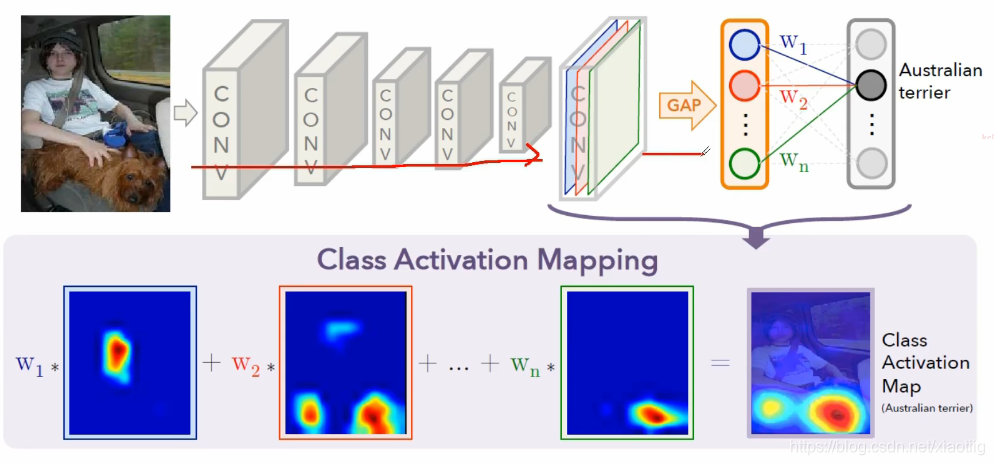
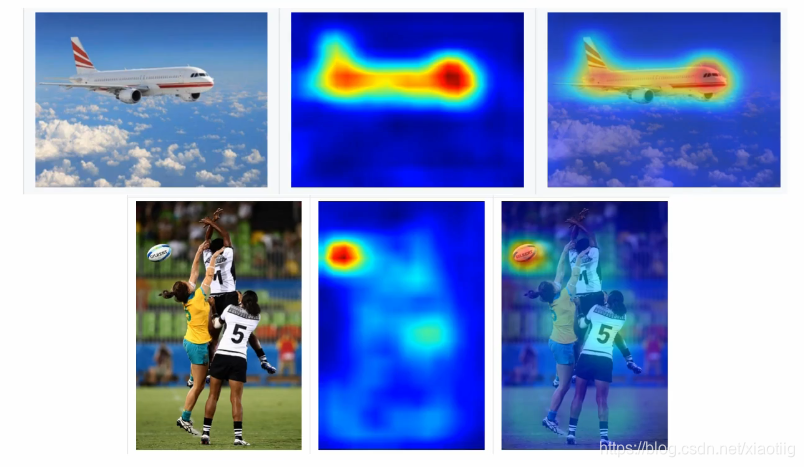
5 模型压缩
模型中存在很多无用的参数,导致模型参数量大,运算复杂。
模型压缩,压缩参数量和运算量

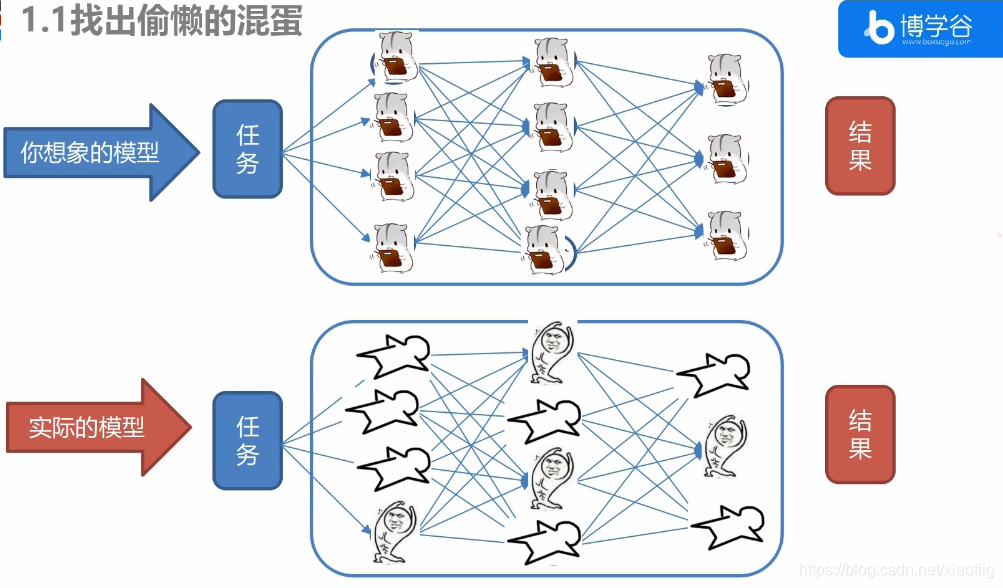
剪枝,剪枝以后挑选出剩余的那些参数和架构,因为剪枝就是在此基础上剪枝的,而不能将剪枝后的结果重新初始化,这样效果不好。
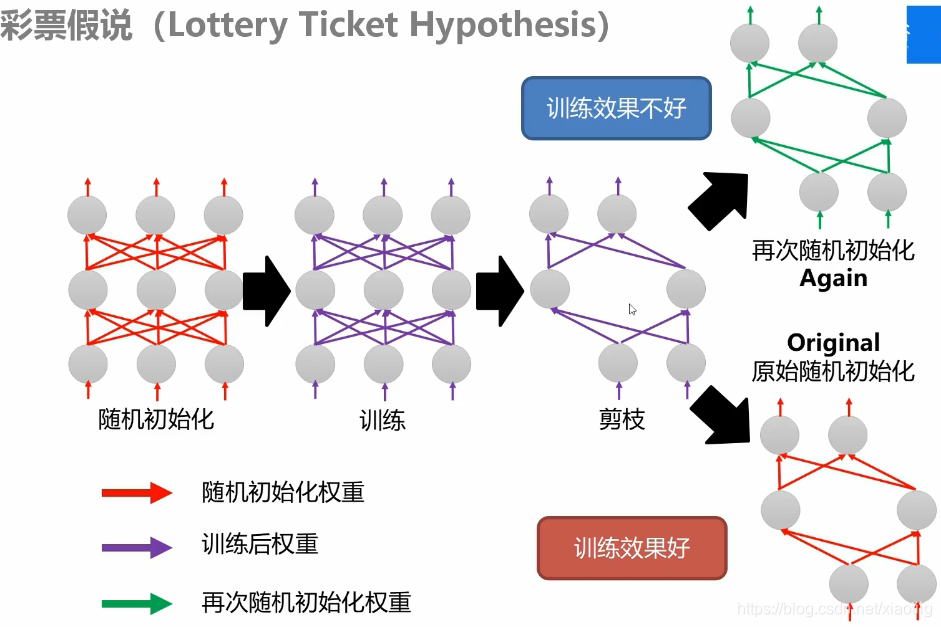

5.1 权重剪枝
不是说那些没有连接的地方没有权重了,只是把权重设置为0了,这样参数量还是不变的。

5.2 神经元剪枝

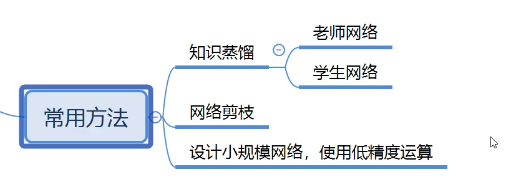
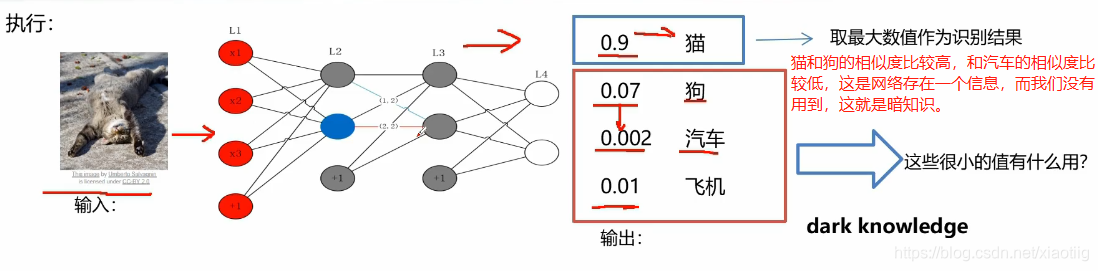
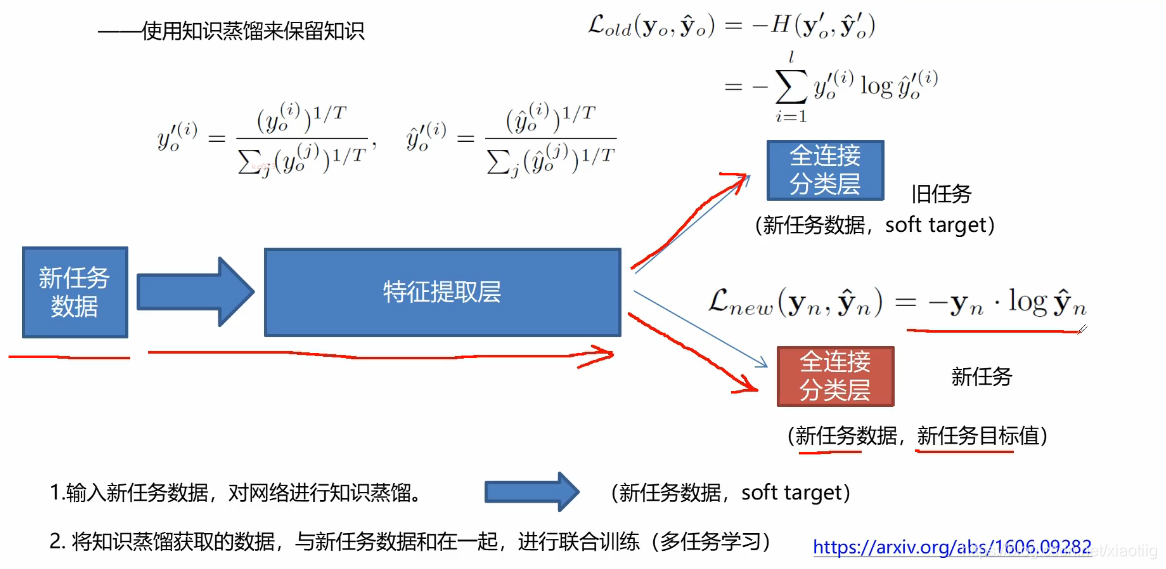
5.3 暗知识和知识蒸馏
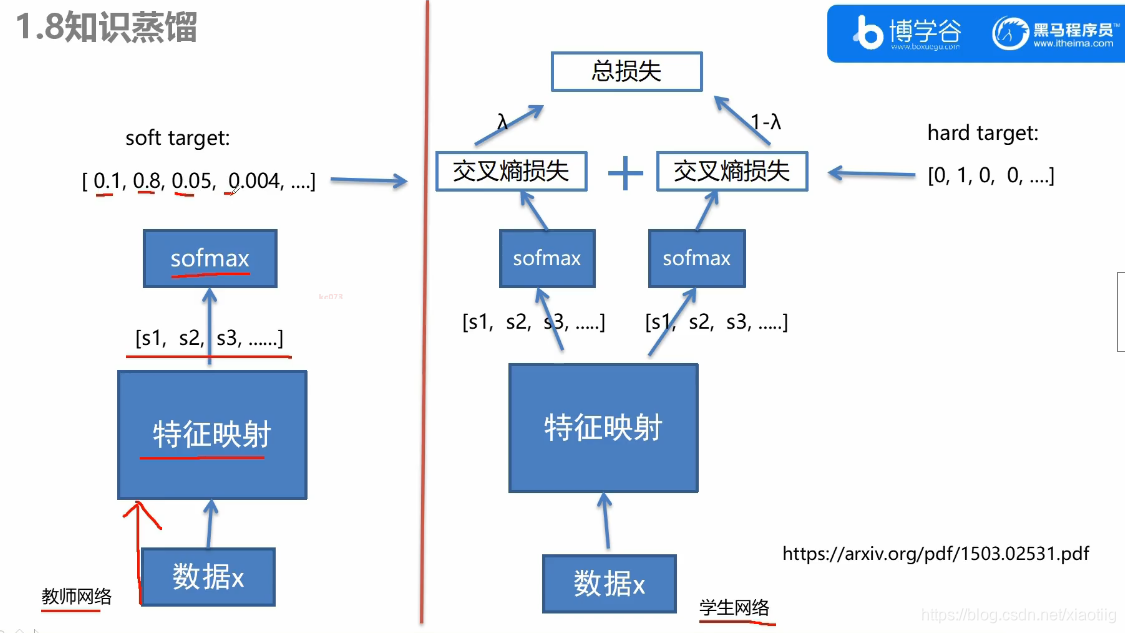
知识蒸馏,就是把教师网络的结果拿过来,训练学生网络。
构建两个网络:
(1)教师网络(参数多,特征提取能力强)
(2)学生网络(参数少,特征提取能力弱)
先训练教师网络,然后利用教师网络的值训练学生网络。
它们两个网络是一样的,先把教师网络训练好,
训练学生网络的时候,需要把训练数据通过教师网络得到的结果传入到学生网络,这个结果就是每个类的概率,来求学生网络的损失,更好的训练学生网络。
学生网络训练时求损失,有两个损失,一个是与教师网络的结果求损失,一个是与真实结果求损失。


6 终身学习(让模型拥有记忆能力)
实际应用非常不成熟
我们的模型比如你开始给它一个任务,它学习的特别好,
再给第2 个任务进行训练,学习的也特别好,但是此时,它对任务1 的测试结果就不行了,它只对最后一个任务的学习效果好。
也就是它会遗忘之前的任务。没法让它记忆。
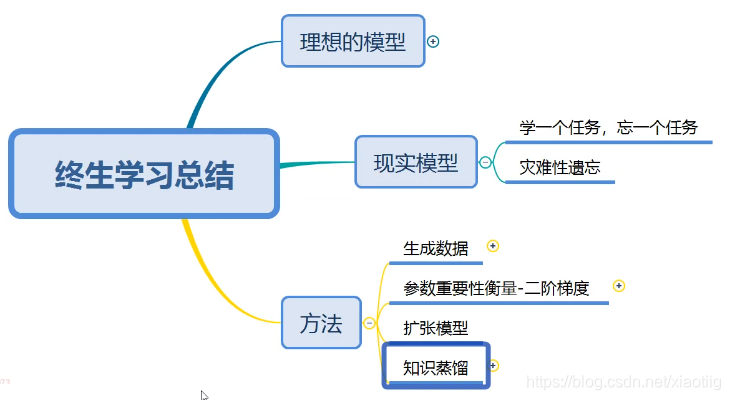
6.1 多任务训练
将多个任务放在一起训练
6.2 利用GAN生成每个任务的数据
每种任务都可以生成
6.3 保留重要权重
把重要的权重参数保留下来
6.4 扩张模型
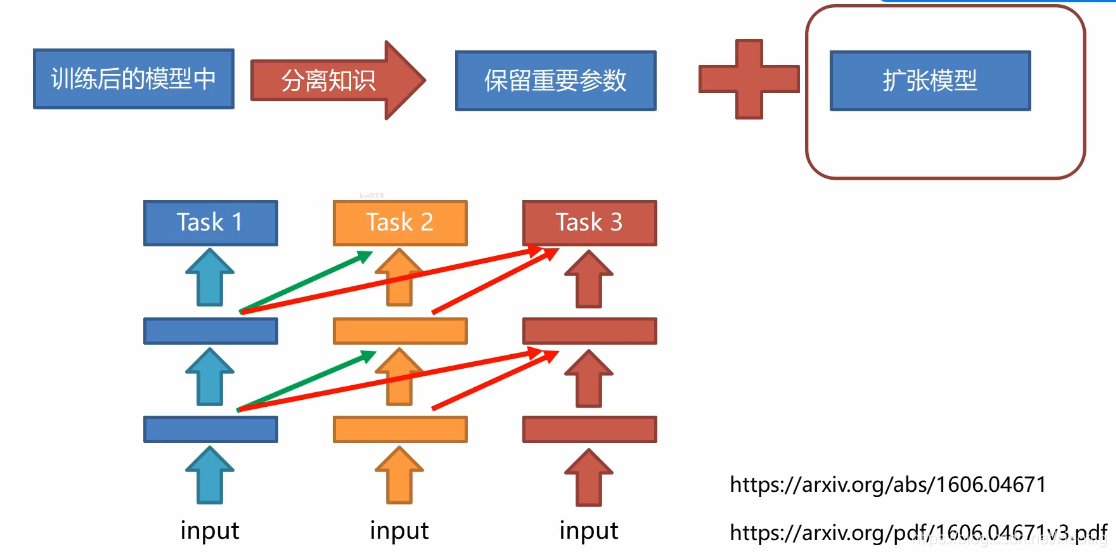
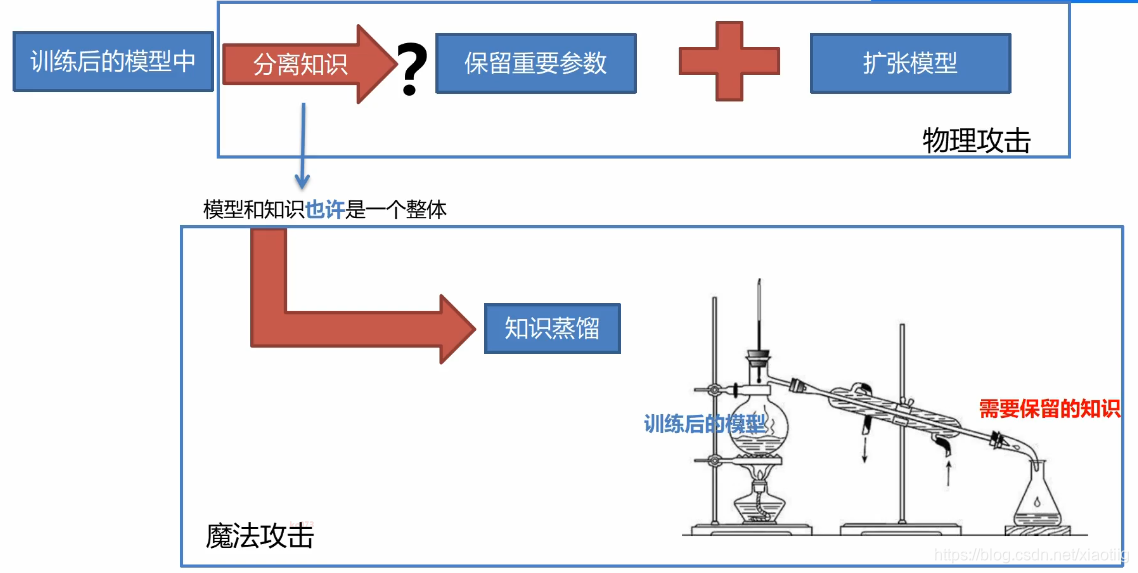
6.5 知识蒸馏
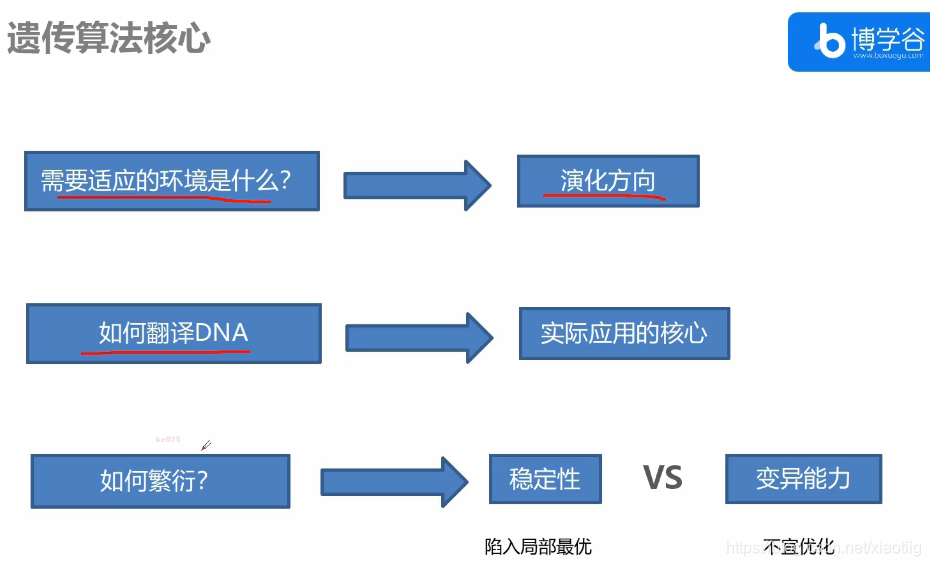
7 进化算法
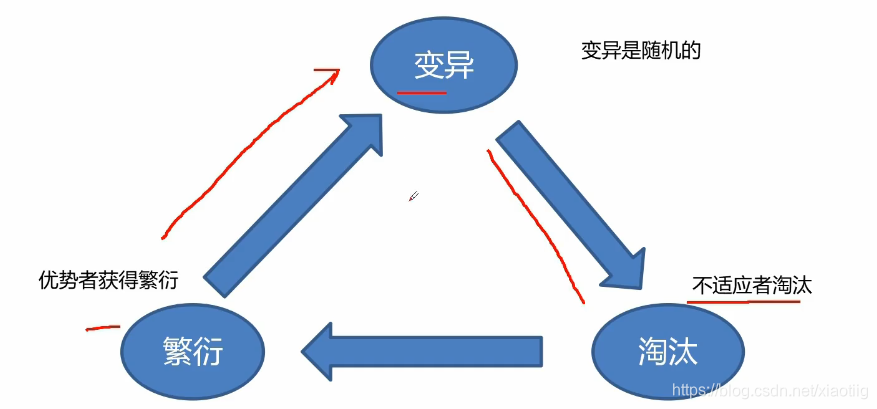
进化学习有:遗传算法,模拟退火,蚁群算法等。就是加入随机,防止陷入最小值。
7.1 遗传算法
在一个条件改变的情况下,对现有的结果进行改进变化,得到条件改变后的最优值。
8 贝叶斯网络
8.1 贝叶斯思想

两个派别:
(1)频率派:研究样本的分布就能大致知道概率分布
(2)贝叶斯派:人为样本是固定不变的,但是抽取的结果参数是一个随机变量,它不是固定的,不是安照计算的概率那样分布的。

敲黑板
敲黑板
敲黑板

8.2 贝叶斯公式

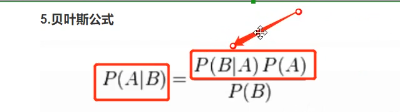
把分母乘过去,就是两边都等于联合概率
8.3 应用理解

8.4 贝叶斯网络
参考资料:
https://www.cnblogs.com/mantch/p/11179933.html
https://blog.youkuaiyun.com/leida_wt/article/details/88743323
贝叶斯网络=信念网络=有向无环图=概率图模型
就是两部分构成
(1)节点,也就是变量
(2)节点间的箭头,也就是变量的条件概率


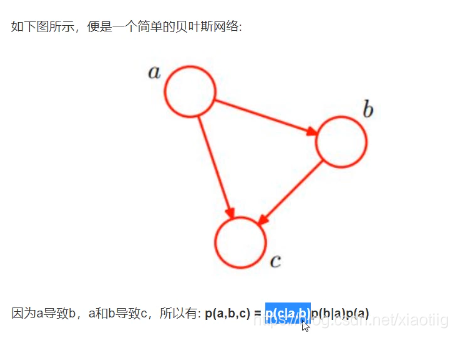
8.4.1 贝叶斯网络实例理解
理解了这个就对贝叶斯网络有了清晰的认识了

8.4.2 贝叶斯网络3种基本结构
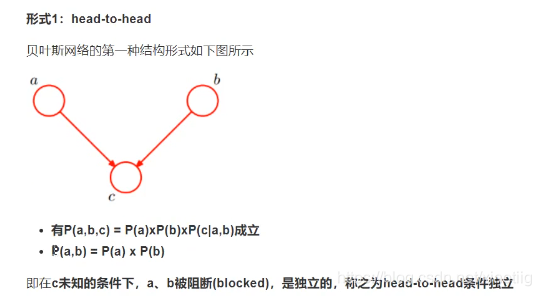
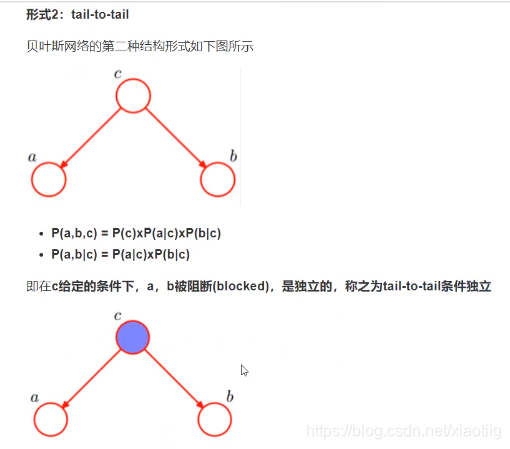
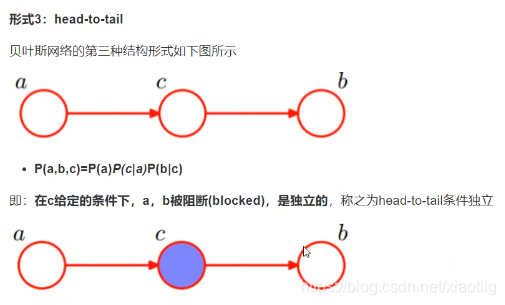
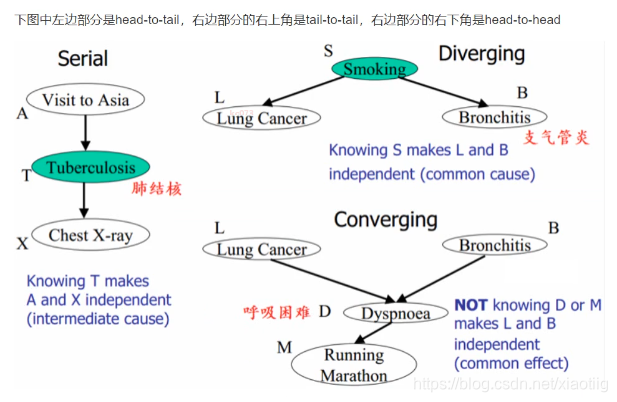
上面的3中网络结构是构成贝叶斯网络的基础
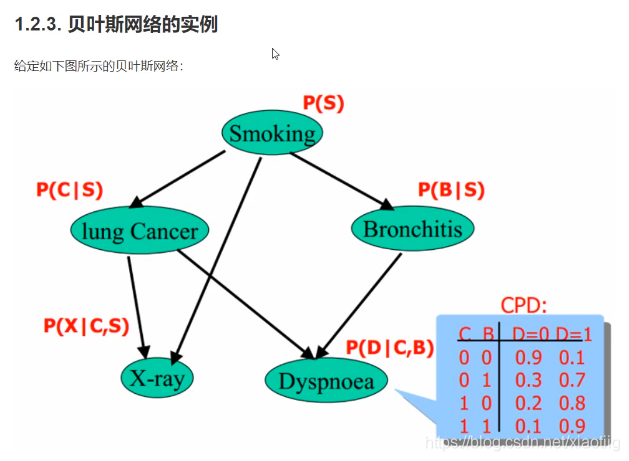
8.4.3 贝叶斯网络构建
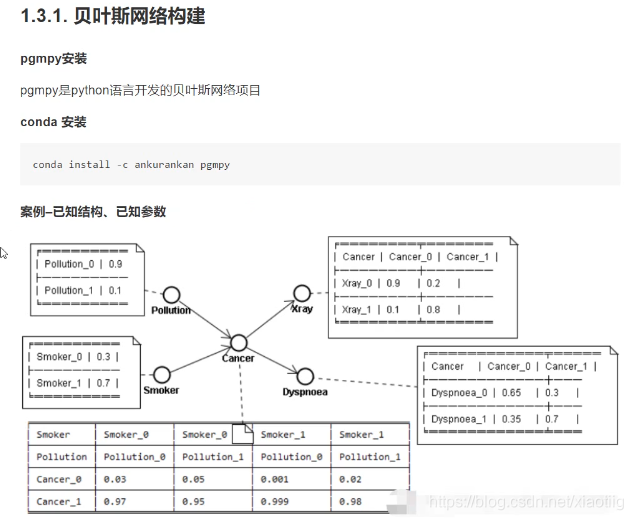
上图中0代表不发生,1代表发生。

8.4.3.1构建网络模型的代码特别简单
(1)构建网络结构
(2)构建概率分布的CPD表格
(3)将CPD数据添加到贝叶斯网络结构中,完成贝叶斯网络的构造。
第1个步骤:

第2个步骤:构建概率分布


第3个步骤:将CPD数据加到贝叶斯网络中,并预测
预测的是发生还是不发生

9 粒子滤波(非线性求解器)
(刚开始可能不理解,看完这一整部分就理解了)
就是不断的改变粒子权重大小
(1)开始随机得到一些预测值,每个值的权重都一样
(2)与真实值比较,估算每个粒子的权重
(3)根据每个离子的权重,产生新粒子,每个粒子的权重仍然一样,但是每个粒子分布的频率由上次得到的权重所决定,这也就是权重的作用。
9.1 图像化理解
现在第一幅图,无法用函数拟合这条曲线,我们就根据黑点求平均值来拟合
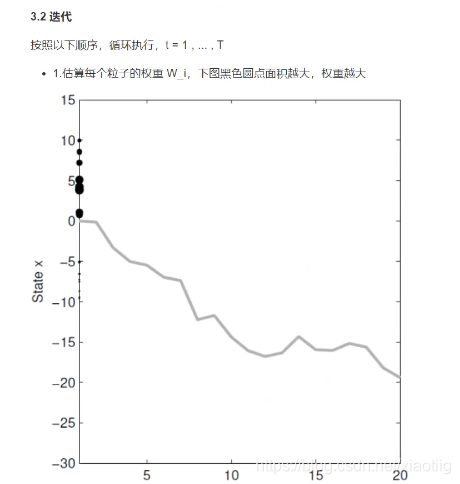
拟合5轮
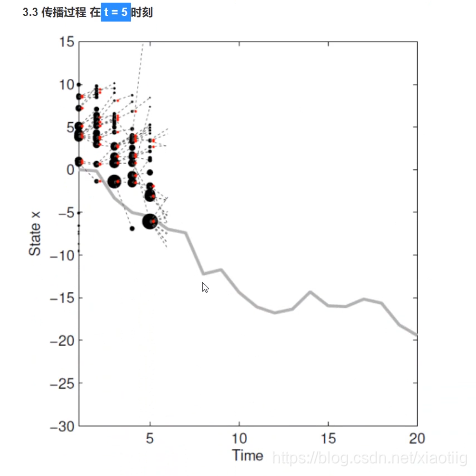
注意:
(1)预测:本次的粒子分布是由上次带权重的粒子决定的,本次粒子的平均值就是本次的预测结果。也就是本次的预测结果是由上一轮的粒子和权重决定的。
(2)更新权重,用本次粒子的分布和真实值的大小进行对比,离真实值较近的粒子赋予更大的权重,离真实值较远的粒子赋予更小的权重,离真实值特别远的粒子直接权重设为0.
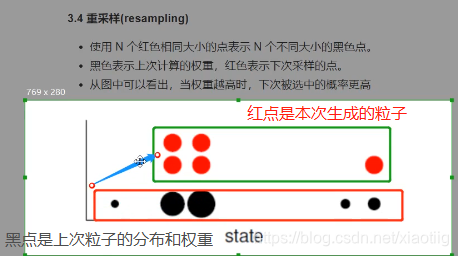
权重的作用(重采样):某个粒子权重越大,那么在下次传播中,在这个粒子周围生成更多的粒子。
(3)对于目标变化剧烈的预测结果较差,因为都是基于上一次的结果进行下一次预测。
我们比如设置每次生成的粒子个数相同(也可以不同),下图中的黑色点就是根据上次真实值给上次粒子赋予了权重,根据上次粒子的分布和权重生成了本次的粒子,可以看出它和粒子的分布和权重有关。一开始红色的点权重都是相同的。红色的点的平均值就是本次的预测结果。————这样就实现了预测过程
训练的时候,红色的点跟本次真实值进行比较,然后对红色的点赋予权重,生成下一次的粒子分布。
9.2 粒子滤波深入理解

求vk和nk
9.2.1 实现代码


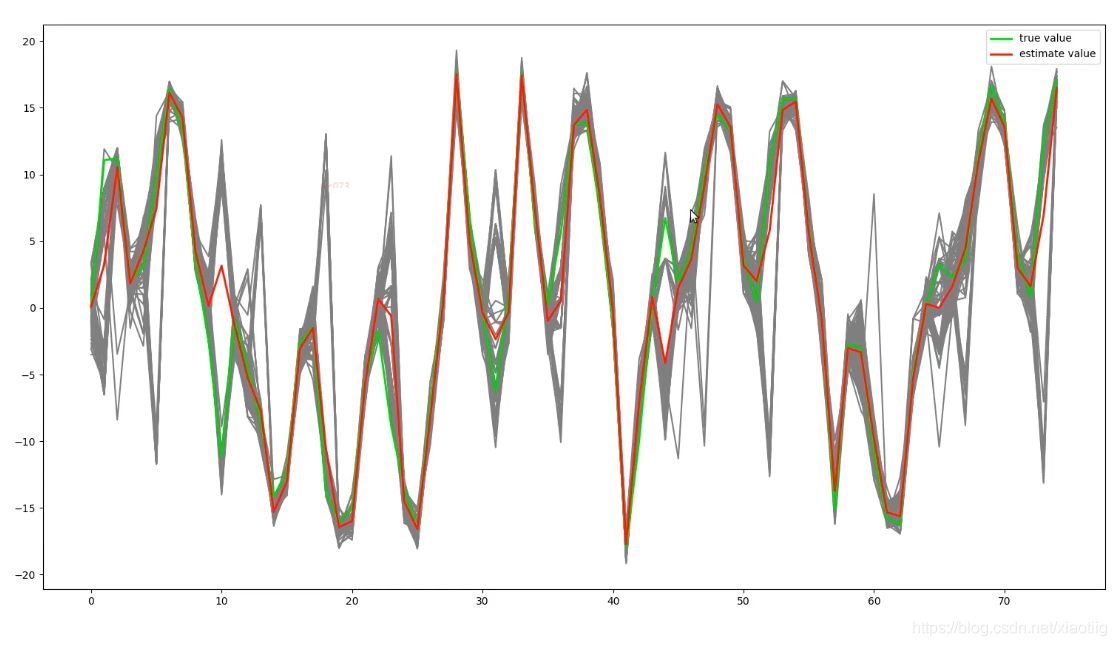
红色的线来追踪绿色的线
补充上面看不清楚的那两行代码:

10 高斯定理
数据的分布类似于高斯分布
使用sklearn工具包实现
既可以实现回归,也可以实现分类
四步:
一维高斯分布——多维高斯分布——无限元高斯分布——回归分类



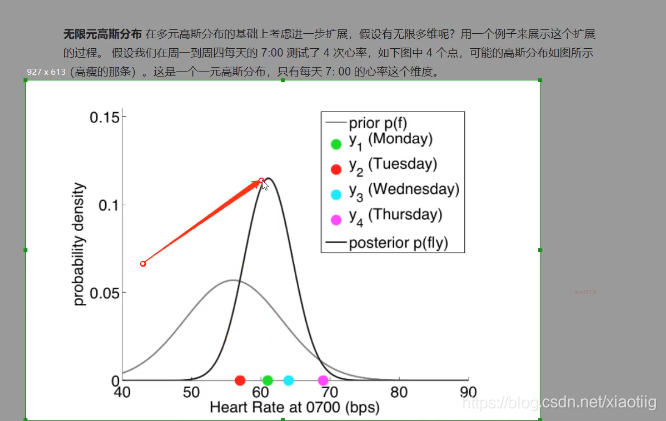
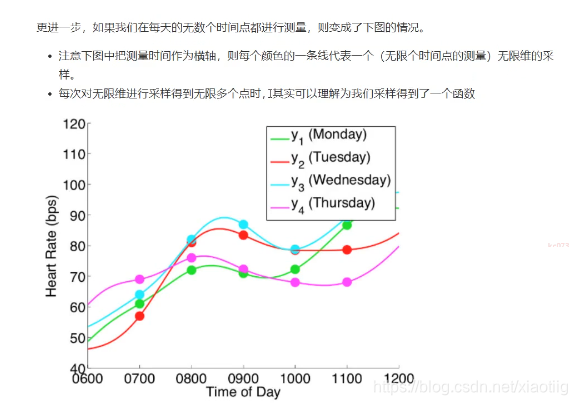
每个维度服从高斯分布
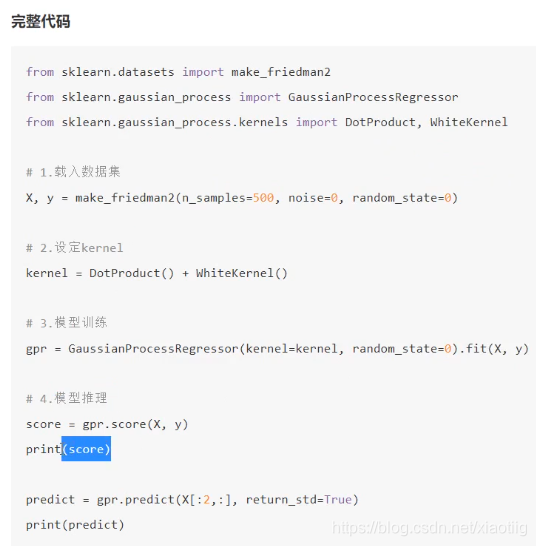
10.1 回归
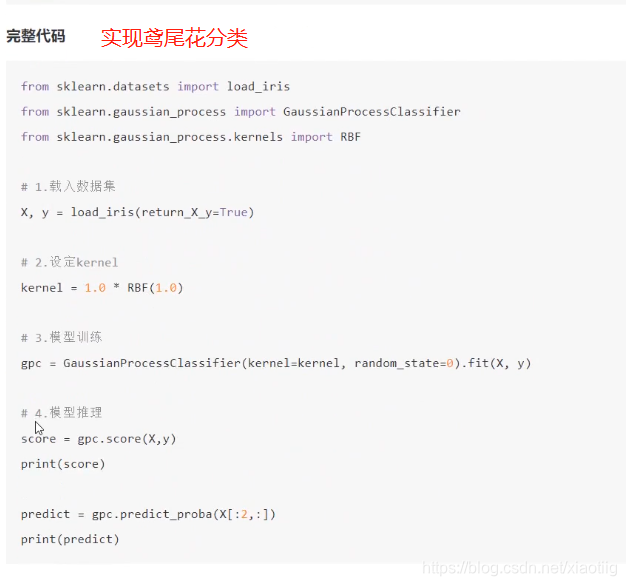
10.2 分类
这里理解比较困难

11 深度强化学习((Deep Reinforcement Learning))
强化学习介绍
https://zhuanlan.zhihu.com/p/25239682
通过很少的行为规则控制不能解决实际问题,可采用强化学习方式。
强化学习是机器学习的一个分支,相较于机器学习经典的有监督学习、无监督学习问题,强化学习最大的特点是在交互中学习(Learning from Interaction)。Agent在与环境的交互中根据获得的奖励或惩罚不断的学习知识,更加适应环境。RL学习的范式非常类似于我们人类学习知识的过程,也正因此,RL被视为实现通用AI重要途径。
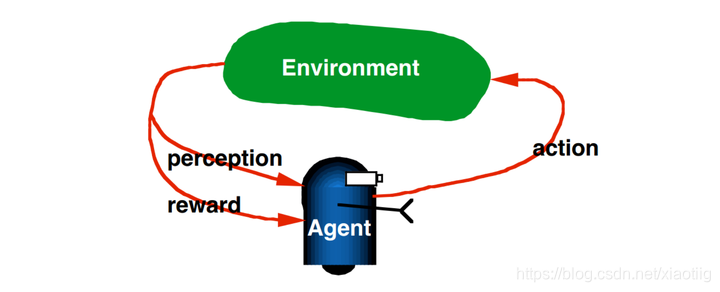

Reward Signal定义的是评判一次交互中的立即的(immediate sense)回报好坏。而Value function则定义的是从长期看action平均回报的好坏。比如象棋中,吃掉对方一个“车”的即时收益很大,但如果因为吃“车”,老“将”被对方吃掉,显然长期看吃“车”这个action是不好的。即一个状态s的value是其长期期望Reward的高低。
Model of the environment:model是对真实世界(environment)的模拟,model建模的是agent采样action后环境的反应。RL中,使用model和planning的方法被称为model-based,反之不使用model而是通过try-and-error学习policy的方法被称为model-free。本文范畴即是model-free。
这个model很难建立
深度学习只是强化学习实现的手段中的一种
11.1 深度学习来实现
(1)AlphaGo
(2)谷歌DeepMind仅根据原始图片就学习和玩2600种雅达利游戏。

小鸟飞过障碍物:

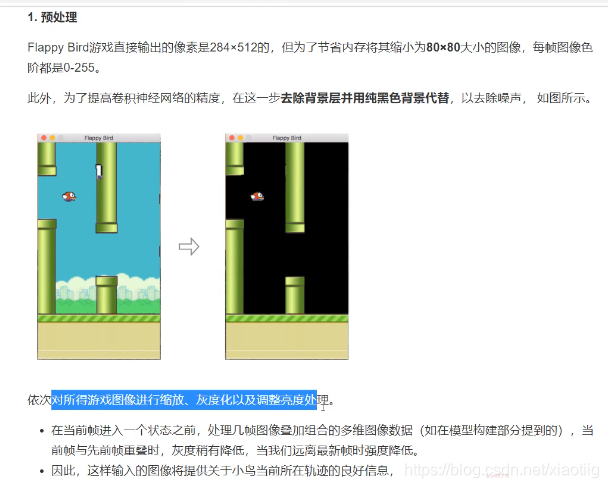
11.2 预处理
实现二分类,但是输入不是单张图像,是多帧图像


11.3 构建模型
输入是4帧图像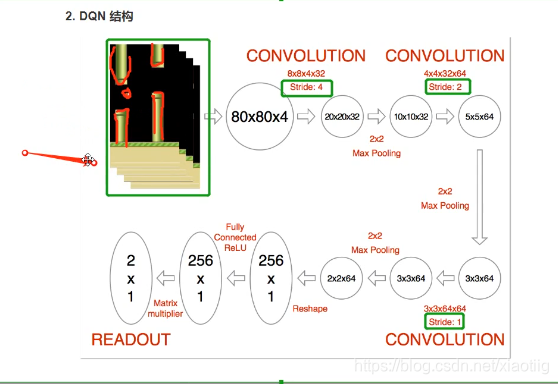
11.4 模型训练


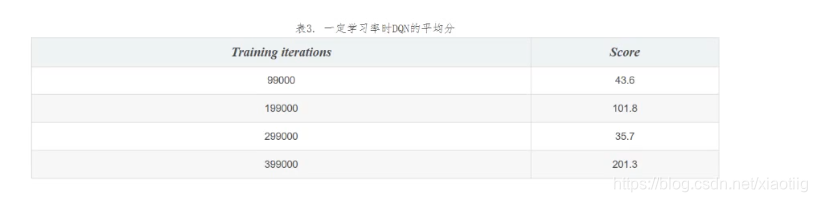
11.5 结果
小鸟可以很好的飞行,穿越障碍物
11.6 最重要的理解
在深度学习实现强化学习的过程中,那么对应的强化学习的4元组为:
(1)输入的4张图像就是环境State,就是世界的状态
(2)网络模型就是P则是Agent所交互世界,也被称为model,就是它与环境的交互。
(3)模型得到的结果分类就是A,A代表的是Agent的所有动作;
(4)模型训练中的损失就是回报Reward,Reward是一个实数值,代表奖励或惩罚。
12 模拟退火法
这个视频很好:
https://www.bilibili.com/video/BV1NA41187RV?from=search&seid=8716321192059488420
模拟退火法就是在可接受的循环条件下,可以大概率跳出局部最优解的一种算法。
解决了局部最优和循环次数太多的问题
模拟退火法实现求断点,从而让一个q值为最大的案例
# 将模拟退火法运用到地理探测器,模拟退火法
import xlrd
import random
import numpy as np
def q_value(y_value):
"""用于计算q值,分为7类"""
# 获取要计算的y
y_number = len(y_value) # y的个数
# 2、从第2个数到倒数第1个数随机选取6个不一样从大到小排列的数,存到breakpoint列表中
break_point = random.sample(range(1809, y_number-1), 6)
break_point.sort()
# 3、得到各层y片段
y_1 = break_point[0]
y_class1 = y_value[0:y_1] # 获取y中第1个数到第一个断点的值,因为已经去掉表头
y_2 = break_point[1]
y_class2 = y_value[y_1:y_2]
y_3 = break_point[2]
y_class3 = y_value[y_2:y_3]
y_4 = break_point[3]
y_class4 = y_value[y_3:y_4]
y_5 = break_point[4]
y_class5 = y_value[y_4:y_5]
y_6 = break_point[5]
y_class6 = y_value[y_5:y_6]
y_class7 = y_value[y_6:] # 从第6个断点到最后
# 4、计算sst=n*方差,ssw,选每两个断点之间的数。
var_class1 = np.var(y_class1) # 第一层方差
num_class1 = len(y_class1) # 第一层个数
ssw = num_class1*var_class1 # 开始的ssw
var_class2 = np.var(y_class2)
num_class2 = len(y_class2)
ssw += num_class2*var_class2 # ssw累加
var_class3 = np.var(y_class3)
num_class3 = len(y_class3)
ssw += num_class3*var_class3
var_class4 = np.var(y_class4)
num_class4 = len(y_class4)
ssw += num_class4*var_class4
var_class5 = np.var(y_class5)
num_class5 = len(y_class5)
ssw += num_class5*var_class5
var_class6 = np.var(y_class6)
num_class6 = len(y_class6)
ssw += num_class6*var_class6
var_class7 = np.var(y_class7)
num_class7 = len(y_class7)
ssw += num_class7*var_class7 # 得到最后的ssw
sst = y_number*np.var(y_value) # 得到sst
q = 1-ssw/sst
return q,break_point
def main():
# 1、打开excel表,找到发生率那一行数据,转换为一个向量y
table = xlrd.open_workbook("../1模拟退火法数据/2十公里格网数据/9松墨天牛发生率.xlsx", 'rb') # 得到表格
sheet1 = table.sheets()[0] # 得到第一个表格
y_col = sheet1.col_values(12) # 获取第13列的列表
# print("读取的数据",y_col)
y_value = y_col[1:] # 去掉第一行的列名
y_num = len(y_value) # y的个数
print("一共有%d个数" % y_num)
# 实现模拟退火
# 1、定义初试值
T = 0.1 # 开始温度
Tmin = 10**(-8) # 最低温度
per = 0.98 # 退火速率
k = 1000 # 循环次数
q = 0.000001 # q越大越好
breakout = list()
tab = 0 # 用于计数,看看一共循环了多少次
# 2、循环,两个循环
while (T>Tmin):
for i in range(1,k+1):
tab +=1
q_new,break_new = q_value(y_value) # 随机获得断点和新q
compare = q_new-q # 看新得到的q是不是比当前的大
# 如果新得到的q大,那就直接赋值
if (compare>0):
q = q_new
breakout = break_new
# 否则还要比那个概率
else:
# 看看符不符合Metropolis概率
ekcl = random.random() #生成0到1之间的随机数
ekcl +=0.01 #防止最后的时候ekcl几乎为0,导致程序失败,也可以通过多运行两次程序的方法来做
p = np.e**(compare/T) #T怎么取T比较合适(e的-2次是0.1多,t最后几乎为0.001,那q的差小于0.002才可以)
if (p>ekcl):
q = q_new
breakout = break_new
T = T*per
print("执行到第%d次" % tab)
print("q值为:", q)
print("断点为:", breakout)
# 3、取出最后的值
print("最优的q值为:",q)
print("断点为:",breakout)
if __name__ == "__main__":
main()


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











