




 本文档详细介绍了如何使用TensorFlow 2.2实现Faster R-CNN算法,包括网络结构、前向传播、反向传播及关键代码解读。跟随步骤,理解Faster R-CNN将有助于深化深度学习理解。
本文档详细介绍了如何使用TensorFlow 2.2实现Faster R-CNN算法,包括网络结构、前向传播、反向传播及关键代码解读。跟随步骤,理解Faster R-CNN将有助于深化深度学习理解。
tf2.2实现Faster R-CNN,全网最好的代码实现,没有之一,进行了详细的代码标注解释。每行代码基本都有注释。
Faster R-CNN输入深度学习中中上等难度的代码,搞懂了Faster R-CNN,深度学习基本上没有多大问题了。
代码来源:
tf2.2实现Faster R-CNN
1 Faster R-CNN介绍
看懂了下面的三个资料就懂了Faster R-CNN了。
1、这个特别好 https://blog.youkuaiyun.com/happyday_d/article/details/85870358
2、https://blog.youkuaiyun.com/weixin_44791964/article/details/108513563
3、https://blog.youkuaiyun.com/xiaotiig/article/details/115859891
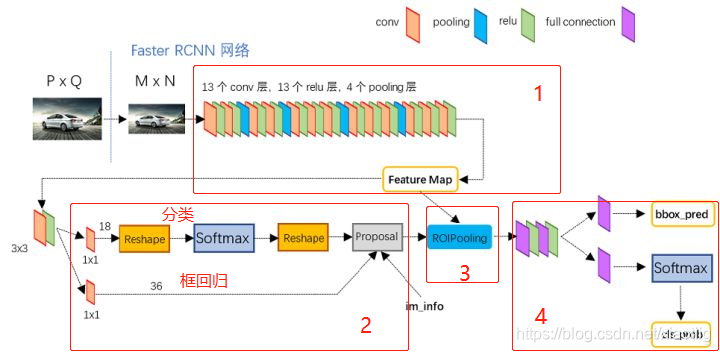
就是这样一个结构,分为4个部分
(1)就是普通的分类卷积网络,最基本的结构,输入600600,得到一个38381024的卷积层;
(2)rpn层,得到38389=12996的先验框,这里还要加入一些粗调,得到300个建议框。
(3)roipooling层,就是根据建议框截切共享特征层,得到14141024大小的一个个卷积层。
(4)将1414*1024的卷积层进行卷积或者神经元计算,得到输出的值,这一部分就是一个普通的分类模型,只不过得到的是两部分,一个是分类,一个是应该偏移的量。当然这里也加入了一些粗调的操作。
2 前向传播,反向传播
请先看readme的介绍,再执行代码,不要着急
2.1 前向传播
前向传播流程
1 选择预测的类型,图片、视频
2 前向传播代码的实现
3 得到12996(38389)行4列未经任何筛选的先验框
4 经过建议框的筛选,得到300个框
(1)根据先验框,模型到rpn层得到的框的粗调值,进行粗调(解码),得到应该标注的12996个框的置信度和位置。
(2)先从12996个框中,安置信度从大到小取出12000个框,只看一个类的置信度,即看是不是前景,不区分具体的类
(3)然后经过非极大值抑制得到最多300个建议框
5 进行最后的精调层,得到最终的框
(1)对建议框的置信度进行筛选,删除所有20个类都小于0.5置信度的框
(2)根据建议框,最后模型得到的值,进行精调(解码),得到应该标注的框,左上角和右下角坐标。
(3)对同一类的框进行非极大抑制,得到最终的框。
2.2 反向传播
注意:我们训练的是得到偏移量和类别,而不是框的具体位置和偏移量
1 先对原始图像进行了数据增强,得到预处理后的图像数据和标注框数据,左上角和右下角坐标,和类别
2 根据真实值和先验框,进行编码,得到我们想要的rpn层应该得到的偏移量(A),也就是粗调结果。再跟rpn本身得到的偏移量(B)对比,让rpn本身得到的偏移量(B)向我们想要的偏移量(A)靠近。
3 根据真实值和建议框,进行编码,得到我们想要的模型精调层应该得到的偏移量(C),也就是精调结果。
再跟模型最后精调层本身得到的偏移量(D)对比,让模型最后精调层本身得到的偏移量(D)向我们想要的偏移量(C)靠近。
4 共4个损失值,
(1)计算rpn层得到的偏移量和我们要的偏移量之间的损失值;
(2)背景与前景0和1之间的类的损失值;
(3)精调层得到的偏移量和我们要的偏移量之间的损失值;
(4)精调层得到的类的损失值.
3 注意
(1)用置信度进行分类
(2)用iou进行非极大抑制
(3)一共进行了4次筛选过滤
(4)训练包括4个框:先验框,建议框,预测框,真实框
预测包括3个框:先验框,建议框,预测框
(5)每次模型得到的类是一个置信度,得到的框的4个值,不是框的坐标,而是相对于先验框的微调值,为了区分,我们通过rpn获得的叫粗调值,粗调值对先验框进行调整;最后模型得到的叫精调值,精调值对建议框进行调整。
(6)编码就是根据真实框和模型的先验框或建议框得到偏移值(对应训练过程),解码就是将偏移值变成预测框(对应预测过程)。
4 疑惑
(1)utils中的decode_boxes()为什么要乘以4,数量级变换是干什么?
(2)frcnn第223行,将x,y,宽高互换是为什么?
5 代码
自己注释难免有误,欢迎交流
完整代码放到了百度网盘:
链接:https://pan.baidu.com/s/1MYmiQGSX9R-LvHuBIbmBpg
提取码:mpyf
复制这段内容后打开百度网盘手机App,操作更方便哦–来自百度网盘超级会员V1的分享
resnet.py的代码
#-------------------------------------------------------------#
# ResNet50的网络部分
#-------------------------------------------------------------#
from __future__ import print_function
from tensorflow.keras import layers
from tensorflow.keras.initializers import RandomNormal
from tensorflow.keras.layers import (Activation, Add, AveragePooling2D, Conv2D, BatchNormalization,
MaxPooling2D, TimeDistributed,
ZeroPadding2D)
def identity_block(input_tensor, kernel_size, filters, stage, block):
"""
构建identity——block结构
"""
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), kernel_initializer=RandomNormal(stddev=0.02), name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(trainable=False, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size, padding='same', kernel_initializer=RandomNormal(stddev=0.02), name=conv_name_base + '2b')(x)
x = BatchNormalization(trainable=False, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), kernel_initializer=RandomNormal(stddev=0.02), name=conv_name_base + '2c')(x)
x = BatchNormalization(trainable=False, name=bn_name_base + '2c')(x)
x = layers.add([x, input_tensor])
x = Activation('relu')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
"""
构建conv_block结构
"""
filters1, filters2, filters3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), strides=strides, kernel_initializer=RandomNormal(stddev=0.02),
name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(trainable=False, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size, padding='same', kernel_initializer=RandomNormal(stddev=0.02),
name=conv_name_base + '2b')(x)
x = BatchNormalization(trainable=False, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), kernel_initializer=RandomNormal(stddev=0.02), name=conv_name_base + '2c')(x)
x = BatchNormalization(trainable=False, name=bn_name_base + '2c')(x)
shortcut = Conv2D(filters3, (1, 1), strides=strides, kernel_initializer=RandomNormal(stddev=0.02),
name=conv_name_base + '1')(input_tensor)
shortcut = BatchNormalization(trainable=False, name=bn_name_base + '1')(shortcut)
x = layers.add([x, shortcut])
x = Activation('relu')(x)
return x
def ResNet50(inputs):
"""
构建获得共享特征层的模型
"""
#-----------------------------------#
# 假设输入进来的图片是600,600,3
# https://blog.youkuaiyun.com/weixin_44791964/article/details/102790260?ops_request_misc=%257B%2522request%255Fid%2522%253A
# %2522162279667116780366569459%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id
# =162279667116780366569459&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v2~rank_v29-1-102790260.
# pc_v2_rank_blog_default&utm_term=resnet&spm=1018.2226.3001.4450
#-----------------------------------#
img_input = inputs
# 600,600,3 -> 300,300,64
x = ZeroPadding2D((3, 3))(img_input)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x)
x = BatchNormalization(trainable=False, name='bn_conv1')(x)
x = Activation('relu')(x)
# 300,300,64 -> 150,150,64
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
# 150,150,64 -> 150,150,256
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
# 150,150,256 -> 75,75,512
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
# 75,75,512 -> 38,38,1024
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
# 最终获得一个38,38,1024的共享特征层
return x
def identity_block_td(input_tensor, kernel_size, filters, stage, block):
"""
最后的精调层用
"""
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# https://blog.youkuaiyun.com/u011913417/article/details/110875054 TimeDistributed的解释
x = TimeDistributed(Conv2D(nb_filter1, (1, 1), kernel_initializer='normal'), name=conv_name_base + '2a')(input_tensor)
x = TimeDistributed(BatchNormalization(trainable=False), name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), kernel_initializer='normal',padding='same'), name=conv_name_base + '2b')(x)
x = TimeDistributed(BatchNormalization(trainable=False), name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter3, (1, 1), kernel_initializer='normal'), name=conv_name_base + '2c')(x)
x = TimeDistributed(BatchNormalization(trainable=False), name=bn_name_base + '2c')(x)
x = Add()([x, input_tensor])
x = Activation('relu')(x)
return x
def conv_block_td(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
"""
最后的精调层用
"""
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = TimeDistributed(Conv2D(nb_filter1, (1, 1), strides=strides, kernel_initializer='normal'), name=conv_name_base + '2a')(input_tensor)
x = TimeDistributed(BatchNormalization(trainable=False), name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', kernel_initializer='normal'), name=conv_name_base + '2b')(x)
x = TimeDistributed(BatchNormalization(trainable=False), name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = TimeDistributed(Conv2D(nb_filter3, (1, 1), kernel_initializer='normal'), name=conv_name_base + '2c')(x)
x = TimeDistributed(BatchNormalization(trainable=False), name=bn_name_base + '2c')(x)
shortcut = TimeDistributed(Conv2D(nb_filter3, (1, 1), strides=strides, kernel_initializer='normal'), name=conv_name_base + '1')(input_tensor)
shortcut = TimeDistributed(BatchNormalization(trainable=False), name=bn_name_base + '1')(shortcut)
x = Add()([x, shortcut])
x = Activation('relu')(x)
return x
def classifier_layers(x):
"""
"""
# num_rois, 14, 14, 1024 -> num_rois, 7, 7, 2048
x = conv_block_td(x, 3, [512, 512, 2048], stage=5, block='a', strides=(2, 2))
# num_rois, 7, 7, 2048 -> num_rois, 7, 7, 2048
x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='b')
# num_rois, 7, 7, 2048 -> num_rois, 7, 7, 2048
x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='c')
# num_rois, 7, 7, 2048 -> num_rois, 1, 1, 2048
x = TimeDistributed(AveragePooling2D((7, 7)), name='avg_pool')(x)
return x
utils.py代码:
import math
import numpy as np
import tensorflow as tf
from PIL import Image
class BBoxUtility(object):
def __init__(self, overlap_threshold=0.7, ignore_threshold=0.3, rpn_pre_boxes=12000, rpn_nms=0.7, classifier_nms=0.3, top_k=300):
self.overlap_threshold = overlap_threshold
self.ignore_threshold = ignore_threshold
self.rpn_pre_boxes = rpn_pre_boxes
self.rpn_nms = rpn_nms
self.classifier_nms = classifier_nms
self.top_k = top_k
def iou(self, box):
"""
输入:一个真实框的左上角和右下角坐标
输出:计算出每个真实框与所有的先验框的iou
"""
# 判断真实框与先验框的重合情况
# self.priors比如是12996个先验框
inter_upleft = np.maximum(self.priors[:, :2], box[:2])
inter_botright = np.minimum(self.priors[:, 2:4], box[2:])
inter_wh = inter_botright - inter_upleft
inter_wh = np.maximum(inter_wh, 0)
inter = inter_wh[:, 0] * inter_wh[:, 1]
# 真实框的面积
area_true = (box[2] - box[0]) * (box[3] - box[1])
# 先验框的面积
area_gt = (self.priors[:, 2] - self.priors[:, 0])*(self.priors[:, 3] - self.priors[:, 1])
# 计算iou
union = area_true + area_gt - inter
iou = inter / union
#print("iou的结果:")
#print(iou)
#print(iou.shape)
return iou
def encode_ignore_box(self, box, return_iou=True):
"""
输入:真实的一个框5列,左上角和右下角坐标,还有类
输出:编码好的框,还有要忽略的先验框
"""
iou = self.iou(box)
ignored_box = np.zeros((self.num_priors, 1))
#---------------------------------------------------#
# 找到处于忽略门限值范围内的先验框
#---------------------------------------------------#
assign_mask_ignore = (iou > self.ignore_threshold) & (iou < self.overlap_threshold)
ignored_box[:, 0][assign_mask_ignore] = iou[assign_mask_ignore]
encoded_box = np.zeros((self.num_priors, 4 + return_iou))
#---------------------------------------------------#
# 找到每一个真实框,重合程度较高的先验框
#---------------------------------------------------#
assign_mask = iou > self.overlap_threshold
if not assign_mask.any():
assign_mask[iou.argmax()] = True
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
assigned_priors = self.priors[assign_mask]
#---------------------------------------------#
# 逆向编码,将真实框转化为FRCNN预测结果的格式
# 先计算真实框的中心与长宽
#---------------------------------------------#
# 这里要进行编码,就是要得到,rpn层应该得到的粗调的结果,这个结果是我们想得到的,这里也是相当于真实值
box_center = 0.5 * (box[:2] + box[2:])
box_wh = box[2:] - box[:2]
#---------------------------------------------#
# 再计算重合度较高的先验框的中心与长宽
#---------------------------------------------#
assigned_priors_center = 0.5 * (assigned_priors[:, :2] +
assigned_priors[:, 2:4])
assigned_priors_wh = (assigned_priors[:, 2:4] -
assigned_priors[:, :2])
#------------------------------------------------#
# 逆向求取efficientdet应该有的预测结果
# 先求取中心的预测结果,再求取宽高的预测结果
#------------------------------------------------#
encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center
encoded_box[:, :2][assign_mask] /= assigned_priors_wh
encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh)
return encoded_box.ravel(), ignored_box.ravel()
def assign_boxes(self, boxes, anchors):
"""
输入:真实框的小数坐标,左上角和右下角;还有比如(12996,4)的先验框
输出:还有编码好的先验框,还标注好正负样本,数量和anchors的数量一致
"""
self.num_priors = len(anchors)
self.priors = anchors
#---------------------------------------------------#
# assignment分为2个部分
# :4 的内容为网络应该有的回归预测结果
# 4 的内容为先验框是否包含物体,默认为背景
#---------------------------------------------------#
assignment = np.zeros((self.num_priors, 4 + 1))
assignment[:, 4] = 0.0
# 如果真实框数量为0,直接返回0
if len(boxes) == 0:
return assignment
#---------------------------------------------------#
# 对每一个真实框都进行iou计算
#---------------------------------------------------#
# 对每一行都应用encode_ignore_box方法,就是每个框都这样计算,编码好的框,还有要忽略的先验框
apply_along_axis_boxes = np.apply_along_axis(self.encode_ignore_box, 1, boxes[:, :4])
# 编码好的框
encoded_boxes = np.array([apply_along_axis_boxes[i, 0] for i in range(len(apply_along_axis_boxes))])
# 需要忽略的框
ingored_boxes = np.array([apply_along_axis_boxes[i, 1] for i in range(len(apply_along_axis_boxes))])
#---------------------------------------------------#
# 在reshape后,获得的ingnored_boxes的shape为:
# [num_true_box, num_priors, 1] 其中1为iou
#---------------------------------------------------#
ingored_boxes = ingored_boxes.reshape(-1, self.num_priors, 1)
ignore_iou = ingored_boxes[:, :, 0].max(axis=0)
# 看对所有真实框而言最大的IOU,如果不大于0,就忽略
ignore_iou_mask = ignore_iou > 0
# 直接就是忽略的样本-1是忽略,
assignment[:, 4][ignore_iou_mask] = -1
#---------------------------------------------------#
# 在reshape后,获得的encoded_boxes的shape为:
# [num_true_box, num_priors, 4+1]
# 4是编码后的结果,1为iou
#---------------------------------------------------#
# -1维是真实框的数量
encoded_boxes = encoded_boxes.reshape(-1, self.num_priors, 5)
#---------------------------------------------------#
# [num_priors]求取每一个先验框重合度最大的真实框
#---------------------------------------------------#
best_iou = encoded_boxes[:, :, -1].max(axis=0)
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
best_iou_mask = best_iou > 0
best_iou_idx = best_iou_idx[best_iou_mask]
#---------------------------------------------------#
# 计算一共有多少先验框满足需求
#---------------------------------------------------#
assign_num = len(best_iou_idx)
# 将编码后的真实框取出
encoded_boxes = encoded_boxes[:, best_iou_mask, :]
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4]
#----------------------------------------------------------#
# 4代表为当前先验框是否包含目标
#----------------------------------------------------------#
assignment[:, 4][best_iou_mask] = 1
return assignment
def decode_boxes(self, mbox_loc, mbox_priorbox):
"""
解码
输入模型预测得到的预测值,还有先验框的左上角和右下角坐标
输出应该标注的框的左上角和右下角坐标
"""
# 获得先验框的宽与高
prior_width = mbox_priorbox[:, 2] - mbox_priorbox[:, 0]
prior_height = mbox_priorbox[:, 3] - mbox_priorbox[:, 1]
# 获得先验框的中心点
prior_center_x = 0.5 * (mbox_priorbox[:, 2] + mbox_priorbox[:, 0])
prior_center_y = 0.5 * (mbox_priorbox[:, 3] + mbox_priorbox[:, 1])
# 真实框距离先验框中心的xy轴偏移情况
# 这里除以4才能对比,具体还没搞清楚,因为不除以4,有3.2等0-4之间的值,需要把它们限制在0-1之间才能对比
decode_bbox_center_x = mbox_loc[:, 0] * prior_width / 4
decode_bbox_center_x += prior_center_x
decode_bbox_center_y = mbox_loc[:, 1] * prior_height / 4
decode_bbox_center_y += prior_center_y
# 真实框的宽与高的求取
decode_bbox_width = np.exp(mbox_loc[:, 2] / 4)
decode_bbox_width *= prior_width
decode_bbox_height = np.exp(mbox_loc[:, 3] / 4)
decode_bbox_height *= prior_height
# 获取真实框的左上角与右下角
decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_width
decode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_height
decode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_width
decode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height
# 真实框的左上角与右下角进行堆叠
decode_bbox = np.concatenate((decode_bbox_xmin[:, None],
decode_bbox_ymin[:, None],
decode_bbox_xmax[:, None],
decode_bbox_ymax[:, None]), axis=-1)
# 防止超出0与1
decode_bbox = np.minimum(np.maximum(decode_bbox, 0.0), 1.0)
return decode_bbox
def detection_out_rpn(self, predictions, mbox_priorbox):
"""
预测值和先验框进行比较
"""
#---------------------------------------------------#
# 获得种类的置信度
#---------------------------------------------------#
#print("看看输入的predictions是什么:")
#print(predictions)
#print(len(predictions))
mbox_conf = predictions[0]
#print("看看这个置信度:")
#print(mbox_conf)
#print(mbox_conf.shape)
#---------------------------------------------------#
# mbox_loc是回归预测结果
#---------------------------------------------------#
mbox_loc = predictions[1]
#print("看看mbox_loc是啥玩意:")
#print(mbox_loc)
#print(mbox_loc.shape)
#---------------------------------------------------#
# 获得网络的先验框
#---------------------------------------------------#
mbox_priorbox = mbox_priorbox
#print("看看先验框")
#print(mbox_priorbox)
#print(mbox_priorbox.shape) (1,12996,4)
results = []
# 对每一张图片进行处理,由于在predict.py的时候,我们只输入一张图片,所以for i in range(len(mbox_loc))只进行一次
for i in range(len(mbox_loc)):
#--------------------------------#
# 利用回归结果对先验框进行解码
#--------------------------------#
decode_bbox = self.decode_boxes(mbox_loc[i], mbox_priorbox)
#print("输出decode_bbox")
#print(decode_bbox)
#print(decode_bbox.shape)
#print("输出完毕")
# 输入为38*38时,decode_bbox的形状为(12996,4) 38*38*9=12996,值全部为小数
#--------------------------------#
# 取出12996个先验框内包含物体的概率
#--------------------------------#
c_confs = mbox_conf[i, :, 0]
# https://blog.youkuaiyun.com/qq_38486203/article/details/80967696
# 从大到小进行排序,存的是索引位置
argsort_index = np.argsort(c_confs)[::-1]
# 取出前12000个框
c_confs = c_confs[argsort_index[:self.rpn_pre_boxes]]
# 得到解码好的12000个框,
decode_bbox = decode_bbox[argsort_index[:self.rpn_pre_boxes], :]
#print("看看这里是不是选出来了12000个置信度高的框")
#print(decode_bbox.shape)
# 这里的形状为(12000, 4)
# 进行iou的非极大抑制,最后最多出来300个框,得到300个框的索引位置
# 参数:框坐标,置信度,最多个数,iou阈值
idx = tf.image.non_max_suppression(decode_bbox, c_confs, self.top_k, iou_threshold=self.rpn_nms).numpy()
#print("非极大抑制结果:")
#print(idx)
#print(idx.shape)
# 取出在非极大抑制中效果较好的内容,最多300个框,可能不到300个
good_boxes = decode_bbox[idx]
# 取出置信度
confs = c_confs[idx][:, None]
#print("取出筛选后剩下300个框的置信度:")
#print(confs)
#print(confs.shape)
# 进行拼接
c_pred = np.concatenate((confs, good_boxes), axis=1)
# 安置信度从大到小进行排序,得到索引
argsort = np.argsort(c_pred[:, 0])[::-1]
# 进行排序
c_pred = c_pred[argsort]
# 得到结果
results.append(c_pred)
#print("看看返回了啥东东:")
#print(np.array(results).shape) (1, 300, 5)
return np.array(results)
def detection_out_classifier(self, predictions, proposal_box, config, confidence):
"""
输入是最后模型得到的需要精调的结果,包括各类的置信度和精调值,进行精调(解码),默认配置,置信度0.5
predictions列表有2个值,(1, 300, 21)和(1, 300, 80);proposal_box(1, 300, 4)
"""
#---------------------------------------------------#
# 获得种类的置信度
#---------------------------------------------------#
proposal_conf = predictions[0] # (1, 300, 21)
#print("proposal_conf是什么:")
#print(proposal_conf)
#print(proposal_conf.shape)
#---------------------------------------------------#
# proposal_loc是回归预测结果
#---------------------------------------------------#
proposal_loc = predictions[1] # (1, 300, 80)
#print("proposal是某东东:")
#print(proposal_loc)
#print("输入进最后这个函数的框:")
#print(proposal_loc.shape)
#print(np.max(np.max(proposal_loc[0],axis=1)))
results = []
# 对每一张图片进行处理,由于在predict.py的时候,我们只输入一张图片,所以for i in range(len(mbox_loc))只进行一次
for i in range(len(proposal_conf)):
proposal_pred = []
# 建议框的宽,高
proposal_box[i, :, 2] = proposal_box[i, :, 2] - proposal_box[i, :, 0]
proposal_box[i, :, 3] = proposal_box[i, :, 3] - proposal_box[i, :, 1]
# 对每个建议框进行处理
for j in range(proposal_conf[i].shape[0]):
# 如果这个建议框的所有类的置信度都小于一个置信度阈值,那就删除
if np.max(proposal_conf[i][j, :-1]) < confidence:
continue
# 否则,得到这个框最大执行度的类别
label = np.argmax(proposal_conf[i][j, :-1])
# 得到这个框最大置信度的置信度值
score = np.max(proposal_conf[i][j, :-1])
# 得到这个框的建议框坐标
(x, y, w, h) = proposal_box[i, j, :]
# 这里乘4,要得到这个建议框应该取20个位置中的哪4个位置
(tx, ty, tw, th) = proposal_loc[i][j, 4*label: 4*(label+1)]
# 除以之前标准化的值
tx /= config.classifier_regr_std[0]
ty /= config.classifier_regr_std[1]
tw /= config.classifier_regr_std[2]
th /= config.classifier_regr_std[3]
# 建议框的中心
cx = x + w/2.
cy = y + h/2.
# 对建议框进行精调,得到最终的要在图片上标注的位置
cx1 = tx * w + cx
cy1 = ty * h + cy
w1 = math.exp(tw) * w
h1 = math.exp(th) * h
# 左上角和右下角坐标
x1 = cx1 - w1/2.
y1 = cy1 - h1/2.
x2 = cx1 + w1/2
y2 = cy1 + h1/2
# 经过第3次筛选,进行添加到列表中
proposal_pred.append([x1,y1,x2,y2,score,label])
# 类的数目
num_classes = np.shape(proposal_conf)[-1]
proposal_pred = np.array(proposal_pred)
#print("看看最后有几个符合要求的:")
#print(proposal_pred.shape)
good_boxes = []
# 如果最后有存在目标的框
if len(proposal_pred)!=0:
# 对每个类进行非极大抑制,取出同一类iou较大的框
for c in range(num_classes):
mask = proposal_pred[:, -1] == c
# 如果有这个类
if len(proposal_pred[mask]) > 0:
boxes_to_process = proposal_pred[:, :4][mask]
confs_to_process = proposal_pred[:, 4][mask]
idx = tf.image.non_max_suppression(boxes_to_process, confs_to_process, self.top_k, iou_threshold=self.classifier_nms).numpy()
# 取出在非极大抑制中效果较好的内容
good_boxes.extend(proposal_pred[mask][idx])
#print("经过第4次非极大抑制")
#print(len(good_boxes))
#print(good_boxes)
results.append(good_boxes)
return results


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言









