




 本文深入探讨了Spark中的共享变量概念,包括广播变量和累加器的使用场景与创建方式。广播变量能有效减少数据传输,而累加器则支持并行操作,用于实现计数或求和等操作。
本文深入探讨了Spark中的共享变量概念,包括广播变量和累加器的使用场景与创建方式。广播变量能有效减少数据传输,而累加器则支持并行操作,用于实现计数或求和等操作。
参考:
共享变量
通常情况下,一个传递给 Spark 操作(例如 map 或 reduce)的函数 func 是在远程的集群节点上执行的。该函数 func 在多个节点执行过程中使用的变量,是同一个变量的多个副本。这些变量的以副本的方式拷贝到每个机器上,并且各个远程机器上变量的更新并不会传播回 driver program(驱动程序)。通用且支持 read-write(读-写) 的共享变量在任务间是不能胜任的。所以,Spark 提供了两种特定类型的共享变量 : broadcast variables(广播变量)和 accumulators(累加器)。
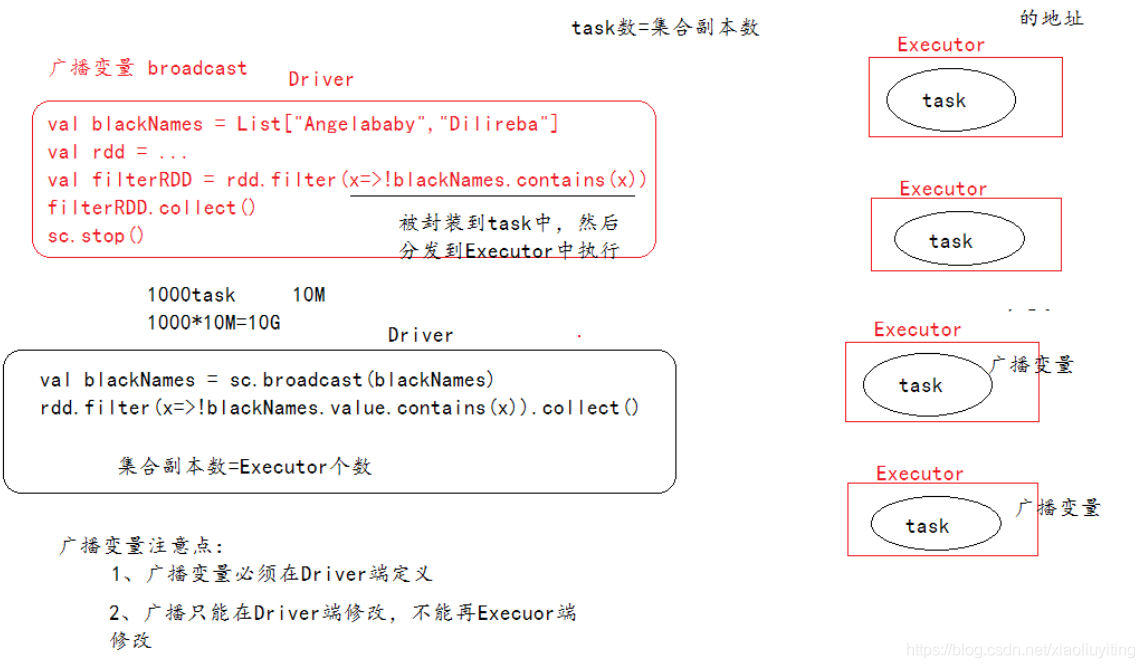
1、广播变量
Broadcast variables(广播变量)允许程序员将一个 read-only(只读的)变量缓存到每台机器上,而不是给任务传递一个副本。它们是如何来使用呢,例如,广播变量可以用一种高效的方式给每个节点传递一份比较大的 input dataset(输入数据集)副本。在使用广播变量时,Spark 也尝试使用高效广播算法分发 broadcast variables(广播变量)以降低通信成本。
Spark 的 action(动作)操作是通过一系列的 stage(阶段)进行执行的,这些 stage(阶段)是通过分布式的 “shuffle” 操作进行拆分的。Spark 会自动广播出每个 stage(阶段)内任务所需要的公共数据。这种情况下广播的数据使用序列化的形式进行缓存,并在每个任务运行前进行反序列化。这也就意味着,只有在跨越多个 stage(阶段)的多个任务会使用相同的数据,或者在使用反序列化形式的数据特别重要的情况下,使用广播变量会有比较好的效果。
广播变量通过在一个变量 v 上调用 SparkContext.broadcast(v) 方法来进行创建。广播变量是 v 的一个 wrapper(包装器),可以通过调用 value方法来访问它的值。代码示例如下:
2、累加器
Accumulators(累加器)是一个仅可以执行 “added”(添加)的变量来通过一个关联和交换操作,因此可以高效地执行支持并行。累加器可以用于实现 counter( 计数,类似在 MapReduce 中那样)或者 sums(求和)。原生 Spark 支持数值型的累加器,并且程序员可以添加新的支持类型。
作为一个用户,您可以创建 accumulators(累加器)并且重命名. 如下图所示, 一个命名的 accumulator 累加器(在这个例子中是 counter)将显示在 web UI 中,用于修改该累加器的阶段。 Spark 在 “Tasks” 任务表中显示由任务修改的每个累加器的值.

在 UI 中跟踪累加器可以有助于了解运行阶段的进度(注: 这在 Python 中尚不支持).可以通过调用 SparkContext.longAccumulator() 或 SparkContext.doubleAccumulator() 方法创建数值类型的 accumulator(累加器)以分别累加 Long 或 Double 类型的值。集群上正在运行的任务就可以使用 add 方法来累计数值。然而,它们不能够读取它的值。只有 driver program(驱动程序)才可以使用 value 方法读取累加器的值。
下面的代码展示了一个 accumulator(累加器)被用于对一个数组中的元素求和:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Long = 10虽然此代码使用 Long 类型的累加器的内置支持, 但是开发者通过 AccumulatorV2 它的子类来创建自己的类型. AccumulatorV2 抽象类有几个需要 override(重写)的方法: reset 方法可将累加器重置为 0, add 方法可将其它值添加到累加器中, merge 方法可将其他同样类型的累加器合并为一个. 其他需要重写的方法可参考 API documentation. 例如, 假设我们有一个表示数学上 vectors(向量)的 MyVector 类,我们可以写成:
class VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] {
private val myVector: MyVector = MyVector.createZeroVector
def reset(): Unit = {
myVector.reset()
}
def add(v: MyVector): Unit = {
myVector.add(v)
}
...
}
// Then, create an Accumulator of this type:
val myVectorAcc = new VectorAccumulatorV2
// Then, register it into spark context:
sc.register(myVectorAcc, "MyVectorAcc1")注意,在开发者定义自己的 AccumulatorV2 类型时, resulting type(返回值类型)可能与添加的元素的类型不一致。
累加器的更新只发生在 action 操作中,Spark 保证每个任务只更新累加器一次,例如,重启任务不会更新值。在 transformations(转换)中, 用户需要注意的是,如果 task(任务)或 job stages(阶段)重新执行,每个任务的更新操作可能会执行多次。
累加器不会改变 Spark lazy evaluation(懒加载)的模式。如果累加器在 RDD 中的一个操作中进行更新,它们的值仅被更新一次,RDD 被作为 action 的一部分来计算。因此,在一个像 map() 这样的 transformation(转换)时,累加器的更新并没有执行。下面的代码片段证明了这个特性:
val accum = sc.longAccumulator
data.map { x => accum.add(x); x }
// Here, accum is still 0 because no actions have caused the map operation to be computed.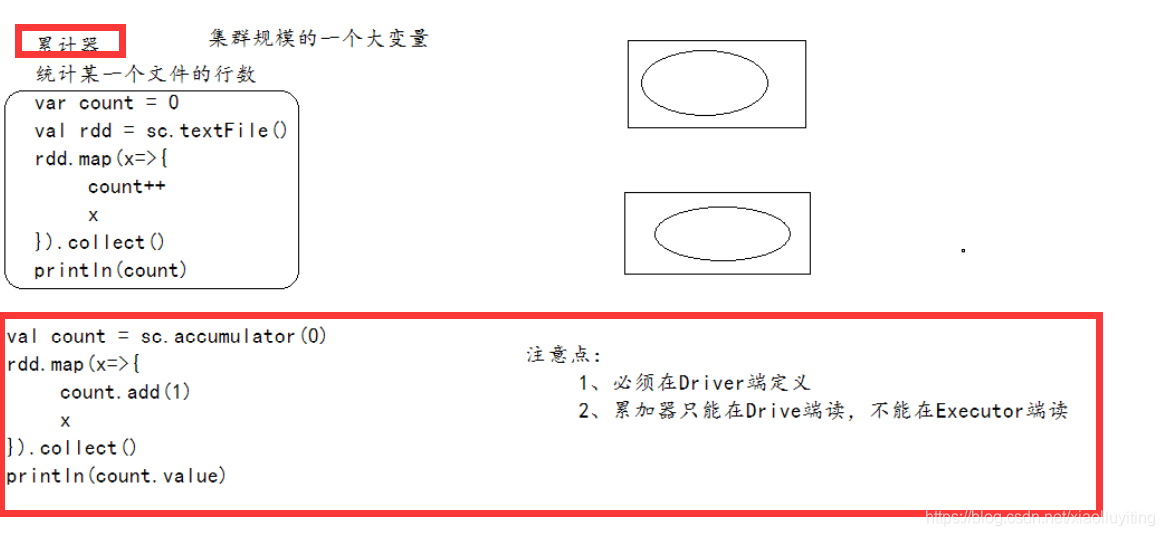

















 3107
3107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









