 京东网页爬虫实战
京东网页爬虫实战








 本文介绍如何使用Python爬取京东首页的标题,并将其保存为HTML和CSV格式文件。文章涵盖爬虫基础知识,如Urllib库的使用、正则表达式的应用及数据存储方法。
本文介绍如何使用Python爬取京东首页的标题,并将其保存为HTML和CSV格式文件。文章涵盖爬虫基础知识,如Urllib库的使用、正则表达式的应用及数据存储方法。
目录
任务描述
本关任务:编写一个爬虫,爬取 www.jd.com 网的 title。
相关知识
为了完成本关任务,需要具备几个基本的技能。首先需要对 Python 语言具有一定的掌握。了解其中的 Urllib 库, Re 库, Random 库。其中,Urllib 库主要实现对网页的爬取。Re 库实现数据的正则化表达。Random 库实现数据的随机生成。
网络爬虫是一种按照一定规则自动抓取互联网信息的程序或者脚本。爬虫的行为过程可以划分为三个部分:
-
载入;
-
解析;
-
存储。
网络爬虫
在利用 Python 进行数据爬取的过程中,我们首先需要了解爬虫的基本技能树,包括静态网页采集。动态网页采集,爬虫框架设计以及数据存储。
在静态网页它取得过程中,需要涉及正则化规则和一些 Python 库。比如 Request 和 beautifulSoup 。在进行动态网页爬取的过程中,需要解决验证码自动识别的问题。在进行爬虫框架设计的过程中,需要掌握 Pyspider 和 Scrapy 。在进行数据存储的过程中,需要掌握 CSV,EXCEL TXT 等格式文件和 MongDB 等数据库。
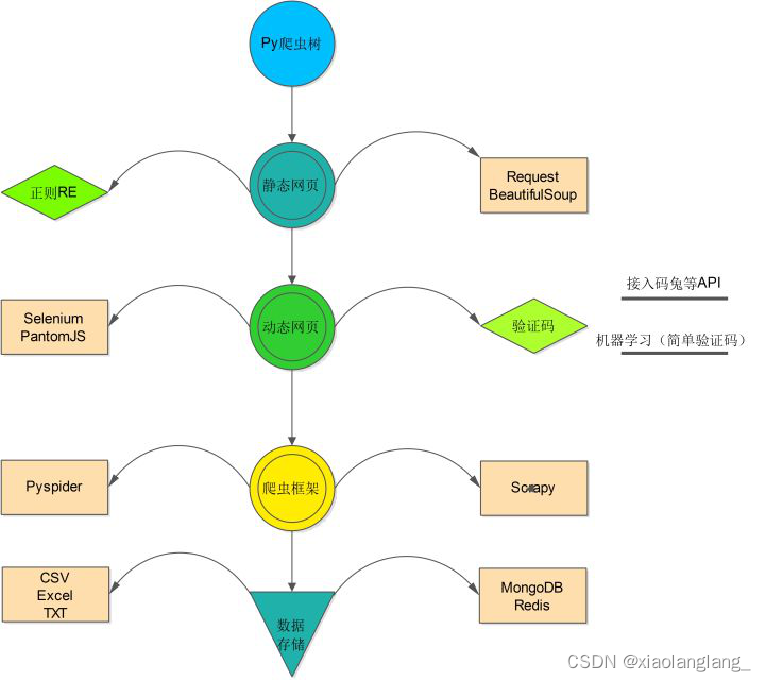
网络爬虫:载入
载入就是将目标网站数据下载到本地,主要步骤如下:
-
网站数据主要依托于网页 (html) 展示;
-
爬虫程序向服务器发送网络请求,从而获取相应的网页;
-
网站常用网络协议: http,https,ftp;
-
数据常用请求方式:get,post;
-
get :参数常放置在 URL 中,如: http://www.adc.com?p=1&q=2&r=3 , 问号后为参数;
-
post :参数常放置在一个表单(报文头( header ))中。
-
-
实际操作:抓取一个静态网页步骤
-
确定 URL;
-
确定请求的方式以及相关参数;
-
用浏览器或者抓包工具 URL 发送参数;
-
即可收到网页返回的结果。
网络爬虫:动态载入
部分页面的数据是动态加载的,比如 Ajax 异步请求,网页中的部分数据需要浏览器渲染或者用户的某些点击、下拉的操作触发才能获得的即 Ajax 异步请求。
面对动态加载的页面时,我们可以借助抓包工具,分析某次操作所触发的请求,通过代码实现相应请求利用智能化的工具:selenium + webdriver。
网络爬虫:解析
在载入的结果中抽取特定的数据,载入的结果主要分成三类 html、json、xml 。
-
html: beautifulSoup、xpath 等;
-
json: json 、 demjson 等;
-
Xml: xml 、 libxml2 等。
编程要求
请仔细阅读右侧代码,结合相关知识,在 Begin-End 区域内进行代码补充,编写一个爬虫,爬取 www.jd.com 网的 title ,具体要求如下:
- 获取 www.jd.com 的页面 html 代码并保存在 ./step1/京东.html;

-
使用正则提取 title;
-
将 title 的内容保存为 csv 文件,位置为 ./step1/csv_file.csv。
测试说明
平台会对你编写的代码进行测试:
预期输出:
html获取成功title匹配成功
import urllib.request
import csv
import re
#打开京东,读取并爬到内存中,解码, 并赋值给data
#将data保存到本地
# ********** Begin ********** #
data=urllib.request.urlopen("http://www.jd.com").read().decode("utf-8","ignore")
urllib.request.urlretrieve("http://www.jd.com",filename="./step1/京东.html")
# ********** End ********** #
#使用正则提取title
#保存数据到csv文件中
# ********** Begin ********** #
pattern="<title>(.*?)</title>"
title=set(re.compile(pattern,re.S).findall(data))
with open("./step1/csv_file.csv", 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(title)
# ********** End ********** #


















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











