







 本文探讨了word2vec训练结果差异的主要因素,包括语料库的场景和性质,以及算法参数如子采样、语言模型、窗口大小等。同时,介绍了评估word2vec模型好坏的方法,如词聚类、cos相关性和类比任务,并提到了相关资源和工具的使用。
本文探讨了word2vec训练结果差异的主要因素,包括语料库的场景和性质,以及算法参数如子采样、语言模型、窗口大小等。同时,介绍了评估word2vec模型好坏的方法,如词聚类、cos相关性和类比任务,并提到了相关资源和工具的使用。
- 这里并不是介绍word2vec的原理,因为原理介绍方面的资料网上多的是:推荐两个我认为很有价值的
- 首先word2vec训练结果的差异主要来自什么因素?
(1)语料影响最大:
语料的场景,比如微博的语料和新闻语料训练的结果差别很大。因为微博属于个人发帖,比较随意。而新闻比较官方正式,另外新闻句式相对复杂。经过训练对比:微博这种短文,训练的相似词更多是同级别的相关词。比如 深圳 相关的是 广州 。而用新闻语料,训练得到 深圳 相关的词 更多是与 深圳 有关联的词,比如 深圳大学。
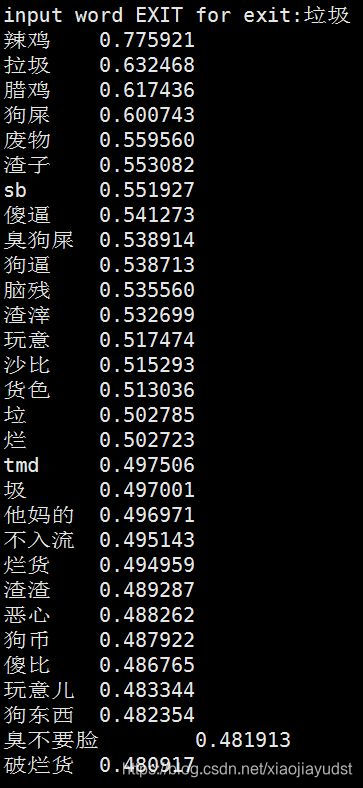
实际发现在微博,违法色情的词训练的比较好,因为黑产用这种渠道来推广;而在评论,骂人的词训练的比较好;在新闻,则是常见的正规的词训练的比较好。下面分别看一下‘评论 垃圾的相关词’跟‘新闻 垃圾的相关词’
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









